大数据
- 大数据概念
- Hadoop
- Hadoop 运行环境搭建
- 安装hadoop
- Hadoop 目录结构
- Hadoop 运行模式
- HDFS
-
- HDFS 优缺点
- HDFS缺点
- HDFS组成架构
- HDFS 文件块大小
- HDFS 的 Shell 操作
-
- 启动Hadoop集群
- -help:输出这个命令参数
- -ls: 显示目录信息
- -mkdir:在HDFS上创建目录
- -moveFromLocal:从本地剪切粘贴到HDFS
- -appendToFile:追加一个文件到已经存在的文件末尾
- -cat:显示文件内容
- -chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
- -copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
- -copyToLocal:从HDFS拷贝到本地
- -cp :从HDFS的一个路径拷贝到HDFS的另一个路径
- -mv:在HDFS目录中移动文件
- -get:等同于copyToLocal,就是从HDFS下载文件到本地
- -getmerge:合并下载多个文件
- -put:等同于copyFromLocal
- -tail:显示一个文件的末尾
- -rm:删除文件或文件夹
- -rmdir:删除空目录
- -du统计文件夹的大小信息
- -setrep:设置HDFS中文件的副本数量
- HDFS客户端操作
- MapReduce
- zookeeper
- HBase
大数据概念
大数据(Big Data):指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产
大数据主要解决,海量数据的采集、存储和分析计算问题
通过对海量数据进行分析,挖掘,进而发现数据内在的规律,从而为企业或者国家创造价值
大数据特点(4V)
Volume(大量)
典型个人计算机硬盘的容量为TB量级,而一些大企业的数据量已经接近EB量级
Velocity(高速)
双11一秒交易额过100亿
Variety(多样)
这种类型的多样性也让数据被分为结构化数据和非结构化数据。相对于以往便于存储的以数据库/文本为主的结构化数据,非结构化数据越来越多,包括网络日志、音频、视频、图片、地理位置信息等,这些多类型的数据对数据的处理能力提出了更高要求。
Value(低价值密度)
价值密度的高低与数据总量的大小成反比
Hadoop
Hadoop是什么
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
- 主要解决,海量数据的存储和海量数据的分析计算问题。
- 广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
Hadoop 三大发行版本
Hadoop 三大发行版本:Apache、Cloudera、Hortonworks。
Apache 版本最原始(最基础)的版本,对于入门学习最好。2006
Cloudera 内部集成了很多大数据框架,对应产品 CDH。2008
Hortonworks 文档较好,对应产品 HDP。2011
Hortonworks 现在已经被 Cloudera 公司收购,推出新的品牌 CDP。
Hadoop 优势
- 高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元素或存储出现故障,也不会导致数据的丢失
- 高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。
- 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
- 高容错性:能够自动将失败的任务重新分配
Hadoop 组成

Hadoop1.x 时 代 ,Hadoop中 的MapReduce同时处理业务逻辑运算和资源的调度,耦合性较大。
在Hadoop2.x时 代,增加 了Yarn。Yarn只负责资 源 的 调 度 ,MapReduce 只负责运算。
Hadoop3.x在组成上没有变化
HDFS
Hadoop Distributed File System,简称 HDFS,是一个分布式文件系统。
HDFS架构概述
NameNode(nn)
存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
DataNode(dn)
在本地文件系统存储文件块数据,以及块数据的校验和
Secondary NameNode(2nn)
每隔一段时间对NameNode元数据备份
Block
数据块,为了能通过多个节点保存大数据集,HDFS将大数据集文件切分成一块块的数据块,在现有hadoop2版本中默认一个块大小为128M
YARN架构概述
Yet Another Resource Negotiator简称YARN ,另一种资源协调者,是Hadoop的资源管理器
- ResourceManager(RM):整个集群资源(内存、CPU等)的老大
- ApplicationMaster(AM):单个任务运行的老大
- NodeManager(N M):单个节点服务器资源老大
- Container:容器,相当一台独立的服务器,里面封装
任务运行所需要的资源,如内存、CPU、磁盘、网络等。
客户端可以有多个
集群上可以运行多个ApplicationMaster
每个NodeManager上可以有多个Container
MapReduce 架构概述
- MapReduce 将计算过程分为两个阶段:Map 和 Reduce
- Map 阶段并行处理输入数据
- Reduce 阶段对 Map 结果进行汇总
Hadoop 运行环境搭建
创建三台虚拟机
1.虚拟网卡IP设置
ip 192.168.228.1
gw 192.168.228.2
netmask 255.255.255.0
dns 8.8.8.8
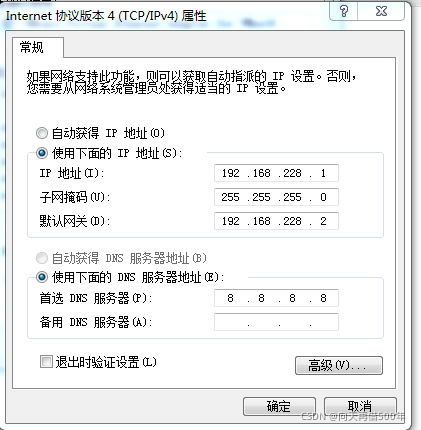
2.修改虚拟机的静态IP
第一台bigdata登录
# 切换root账户
su root
# 修改配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static ###修改
ONBOOT=yes ###修改
IPADDR=192.168.228.161 ###添加
NETMASK=255.255.255.0 ###添加
GATEWAY=192.168.228.2 ###添加
DNS1=8.8.8.8 ###添加
截图
重启网卡
service network restart
查看IP
ip addr
截图
3.修改主机名
su root
vi /etc/hostname
hadoop102
配置 Linux 克隆机主机名称映射 hosts 文件,打开/etc/hosts
vi /etc/hosts
192.168.228.161 hadoop102
192.168.228.162 hadoop103
192.168.228.163 hadoop104
reboot重启
另外两台主机配置如下
第二台bigdata登录
su root
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static ###
ONBOOT=yes ###
IPADDR=192.168.228.162 ###
NETMASK=255.255.255.0 ###
GATEWAY=192.168.228.2 ###
DNS1=8.8.8.8
重启网卡
service network restart
查看IP
ip addr
srt软件
su root
vi /etc/hostname
hadoop103
vi /etc/hosts
192.168.228.161 hadoop102
192.168.228.162 hadoop103
192.168.228.163 hadoop104
第三台bigdata登录
su root
vi /etc/sysconfig/network-scripts/ifcfg-ens33
BOOTPROTO=static ###
ONBOOT=yes ###
IPADDR=192.168.228.163 ###
NETMASK=255.255.255.0 ###
GATEWAY=192.168.228.2 ###
DNS1=8.8.8.8
重启网卡
service network restart
查看IP
ip addr
srt软件
su root
vi /etc/hostname
hadoop104
vi /etc/hosts
192.168.228.161 hadoop102
192.168.228.162 hadoop103
192.168.228.163 hadoop104
4.关闭防火墙
su root
#关闭防火墙
systemctl stop firewalld
#关闭防火墙开机启动
systemctl disable firewalld
#查看防火墙状态
systemctl status firewalld
5.配置SSH免登录
1. bigdata登录hadoop102
su bigdata
cd ~/(#进入到我的home目录)
cd .ssh(如果报错进行以下操作)
ssh hadoop102(自己-目的产生.ssh文件)
yes
123456
exit
cd .ssh
ssh-keygen -t rsa(三个回车)
# 分别执行下面3条命令
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
注意:
还需要在hadoop103上采用bigdata账号,配置一下无密登录到hadoop102、hadoop103、hadoop104;
还需要在hadoop104上采用bigdata账号配置一下无密登录到hadoop102、hadoop103、hadoop104服务器上。
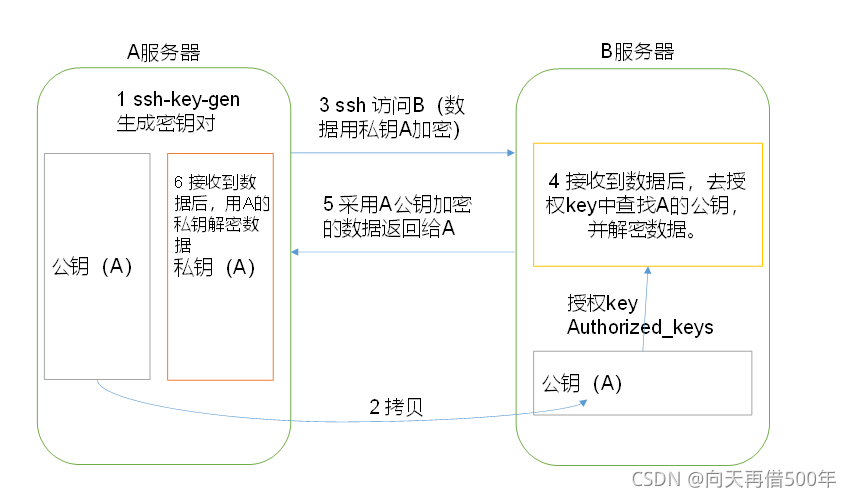
6.创建目录并修改权限
su root
mkdir /opt/software
mkdir /opt/module
chmod 777 /opt/software
chmod 777 /opt/module
7.安装JDK
卸载现有JDK
查询是否安装Java软件:
rpm -qa | grep java
如果安装的版本低于1.7,卸载该JDK
sudo rpm -e 软件包
查看JDK安装路径:
which java
用 XShell 传输工具将 JDK 导入到 opt 目录下面的 software 文件夹下面
在 Linux 系统下的 opt 目录中查看软件包是否导入成功
ls /opt/software/
解压 JDK 到/opt/module 目录下
tar -zxvf jdk-8u251-linux-x64.tar.gz -C /opt/module
配置 JDK 环境变量
su root
123456
vi /etc/profile
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_251
export PATH=$PATH:$JAVA_HOME/bin
:wq
source /etc/profile
测试 JDK 是否安装成功
java -version
另外两台机器配置
su bigdata
cd /opt
scp -r /opt/module hadoop103:/opt
scp -r /opt/module hadoop104:/opt
分别在hadoop103,hadoop104修改/etc/profile
su root
123456
vi /etc/profile
export JAVA_HOME=/opt/module/jdk1.8.0_251
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
su bigdata
安装hadoop
上传hadoop
将hadoop上传到 /opt/software
解压 /opt/module 下面
cd /opt/software
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module
配置hadoop
cd /opt/module/hadoop-2.7.2/etc/hadoop
第一个:hadoop-env.sh
vi hadoop-env.sh
#第27行左右
export JAVA_HOME=/opt/module/jdk1.8.0_251
第二个:core-site.xml
vi core-site.xml
<configuration>
<!--配置hdfs文件系统默认名称-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop(主机名):9000</value>
</property>
</configuration>
注意:名称是一个HDFS的URL
配置到configuration标签里面
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
mkdir -p /opt/module/hadoop-2.7.2/data/tmp
第三个:hdfs-site.xml
vi hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
第四个:mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
第五个:yarn-site.xml
vi yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
第六个:slaves
vi slaves
添加
hadoop102
hadoop103
hadoop104
复制到另外两台机器上
cd /opt/module
scp -r /opt/module/hadoop-2.7.2 hadoop103:/opt/module
scp -r /opt/module/hadoop-2.7.2 hadoop104:/opt/module
添加环境变量
将hadoop添加到环境变量(三台机器)
su root
vi /etc/profile
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
su bigdata
格式化hdfs
格式化namenode(hadoop102)(仅仅是第一次使用需要格式化)
hdfs namenode -format
注意:这里的格式化是格式成hadoop可以识别的文件系统,比如我们买了一块硬盘我们需要格式化成windows或者mac,linux系统识别的文件系统,才能使用这个文件系统。
启动hadoop(hadoop102)
# 先启动HDFS
start-dfs.sh
再启动YARN
start-yarn.sh
关闭安全模式
hdfs dfsadmin -safemode leave
验证是否启动成功
使用jps命令验证
# 12. 查看hadoop是否启动成功
jps 存在以下进程名称说明启动成功
5876 SecondaryNameNode
5702 DataNode
5995 Jps
5612 NameNode
可视化管理界面
http://hadoop102:50070 (HDFS管理界面)
http://hadoop102:8088 (MR管理界面)
截图
Hadoop 目录结构
- bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
- etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
- lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
- sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
- share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
Hadoop 运行模式
Hadoop 运行模式包括:本地模式、伪分布式模式以及完全分布式模式。
- 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用
- 伪分布式模式:也是单机运行,但是具备 Hadoop 集群的所有功能,一台服务器模拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用
- 完全分布式模式:多台服务器组成分布式环境。生产环境使用
单词计数
- 创建在 hadoop-3.1.3 文件下面创建一个 wcinput 文件夹
mkdir wcinput
- 在 wcinput 文件下创建一个 word.txt 文件
cd wcinput
- 编辑 word.txt 文件
vim word.txt
在文件中输入如下内容
hadoop yarn
hadoop mapreduce
dyk dyk
保存退出::wq
- 回到 Hadoop 目录/opt/module/hadoop-3.1.3
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
- 查看结果
cat wcoutput/part-r-00000
HDFS
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS 的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变
HDFS 优缺点
高容错性
- 数据自动保存多个副本。它通过增加副本的形式,提高容错性
- 某一个副本丢失以后,它可以自动恢复
适合处理大数据
- 数据规模:能够处理数据规模达到GB、TB、甚至PB级别的数据
- 文件规模:能够处理百万规模以上的文件数量,数量相当之大
可构建在廉价机器上,通过多副本机制,提高可靠性。
HDFS缺点
不适合低延时数据访问
- 比如毫秒级的存储数据,是做不到的。
无法高效的对大量小文件进行存储
- 存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
- 小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
不支持并发写入、文件随机修改
- 一个文件只能有一个写,不允许多个线程同时写;
- 仅支持数据append(追加),不支持文件的随机修改
HDFS组成架构
NameNode
就是Master,它是一个主管、管理者
(1)管理HDFS的名称空间;
(2)配置副本策略;
(3)管理数据块(Block)映射信息;
(4)处理客户端读写请求。
DataNode
就是Slave。NameNode下达命令,DataNode执行实际的操作
(1)存储实际的数据块;
(2)执行数据块的读/写操作
Client:
就是客户端
(1)文件切分。文件上传HDFS的时候,Client将文件切分成一个一个的Block,然后进行上传;
(2)与NameNode交互,获取文件的位置信息;
(3)与DataNode交互,读取或者写入数据;
(4)Client提供一些命令来管理HDFS,比如NameNode格式化;
(5)Client可以通过一些命令来访问HDFS,比如对HDFS增删查改操作;
Secondary NameNode
并非NameNode的热备。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode ;
(2)在紧急情况下,可辅助恢复NameNode
HDFS 文件块大小
HDFS中的文件在物理上是分块存储(Block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M
思考:为什么块的大小不能设置太小,也不能设置太大?
(1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
(2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开
始位置所需的时间。导致程序在处理这块数据时,会非常慢。
总结:HDFS块的大小设置主要取决于磁盘传输速率。
HDFS 的 Shell 操作
hadoop fs 具体命令 OR hdfs dfs 具体命令
启动Hadoop集群
[bigdata@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[bigdata@hadoop102 hadoop-2.7.2]$ sbin/start-yarn.sh
-help:输出这个命令参数
hadoop fs -help rm
-ls: 显示目录信息
hadoop fs -ls /
-mkdir:在HDFS上创建目录
hadoop fs -mkdir -p /sanguo/shuguo
-moveFromLocal:从本地剪切粘贴到HDFS
touch kongming.txt
hadoop fs -moveFromLocal ./kongming.txt /sanguo/shuguo
-appendToFile:追加一个文件到已经存在的文件末尾
touch liubei.txt
vi liubei.txt
输入
san gu mao lu
hadoop fs -appendToFile liubei.txt /sanguo/shuguo/kongming.txt
-cat:显示文件内容
hadoop fs -cat /sanguo/shuguo/kongming.txt
-chgrp 、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
hadoop fs -chmod 666 /sanguo/shuguo/kongming.txt
hadoop fs -chown bigdata:bigdata /sanguo/shuguo/kongming.txt
-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
hadoop fs -copyFromLocal README.txt /
-copyToLocal:从HDFS拷贝到本地
hadoop fs -copyToLocal /sanguo/shuguo/kongming.txt ./
-cp :从HDFS的一个路径拷贝到HDFS的另一个路径
hadoop fs -cp /sanguo/shuguo/kongming.txt /zhuge.txt
-mv:在HDFS目录中移动文件
hadoop fs -mv /zhuge.txt /sanguo/shuguo/
-get:等同于copyToLocal,就是从HDFS下载文件到本地
hadoop fs -get /sanguo/shuguo/kongming.txt ./
-getmerge:合并下载多个文件
比如HDFS的目录 /user/bigdata/test下有多个文件:log.1, log.2,log.3,…
hadoop fs -getmerge /user/bigdata/test/* ./zaiyiqi.txt
-put:等同于copyFromLocal
hadoop fs -put ./zaiyiqi.txt /user/bigdata/test/
-tail:显示一个文件的末尾
hadoop fs -tail /sanguo/shuguo/kongming.txt
-rm:删除文件或文件夹
hadoop fs -rm /user/bigdata/test/jinlian2.txt
hadoop fs -rm -r /user/bigdata/test
-rmdir:删除空目录
hadoop fs -mkdir /test
hadoop fs -rmdir /test
-du统计文件夹的大小信息
hadoop fs -du -s -h /user/bigdata/test
# 统计每个文件的大学校
hadoop fs -du -h /user/bigdata/test
-setrep:设置HDFS中文件的副本数量
hadoop fs -setrep 10 /sanguo/shuguo/kongming.txt
HDFS客户端操作
解压Hadoop压缩包到指定位置
配置HADOOP_HOME环境变量
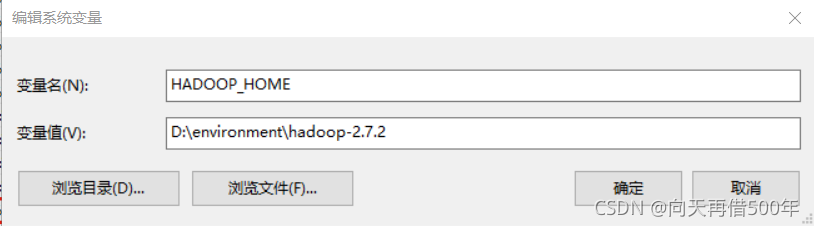
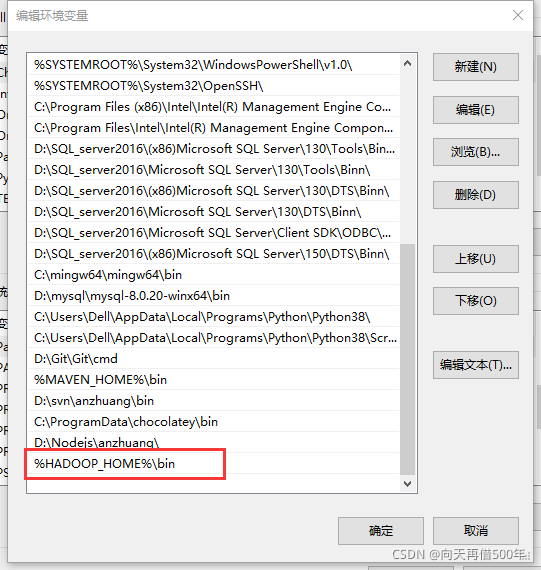
配置Path环境变量
%HADOOP_HOME%\bin
创建一个Maven工程
依赖
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
创建目录
导包hadoop、uri包 java.net.URI
@Test
public void testMkdirs() throws Exception {
// 1 获取文件系统
Configuration configuration = new Configuration();
// 配置在集群上运行
// configuration.set("fs.defaultFS", "hdfs://hadoop102:9000");
// FileSystem fs = FileSystem.get(configuration);
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.228.161:9000"), configuration, "bigdata");
// 2 创建目录
fs.mkdirs(new Path("/9527/666"));
// 3 关闭资源
fs.close();
}
HDFS文件上传(测试参数优先级)
//HDFS文件上传
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
//设置文件副本数量
configuration.set("dfs.replication", "2");
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.228.161:9000"), configuration, "bigdata");
// 2 上传文件
fs.copyFromLocalFile(new Path("D:\\dyk.txt"), new Path("/9527/666"));
// 3 关闭资源
fs.close();
System.out.println("over");
}
HDFS文件下载
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.228.161:9000"), configuration, "bigdata");
// 2 执行下载操作
// boolean delSrc 指是否将原文件删除
// Path src 指要下载的文件路径
// Path dst 指将文件下载到的路径
// boolean useRawLocalFileSystem 是否开启文件校验
fs.copyToLocalFile(false, new Path("/9527/666/dyk.txt"), new Path("D:\\java_dyk"), true);
// 3 关闭资源
fs.close();
}
HDFS文件夹删除
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.228.161:9000"), configuration, "bigdata");
// 2 执行删除
fs.delete(new Path("/9527"), true);
// 3 关闭资源
fs.close();
}
HDFS文件详情查看
查看文件名称、权限、长度、块信息
@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException{
// 1获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.228.161:9000"), configuration, "bigdata");
// 2 获取文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus status = listFiles.next();
// 输出详情
// 文件名称
System.out.println(status.getPath().getName());
// 长度
System.out.println(status.getLen());
// 权限
System.out.println(status.getPermission());
// 分组
System.out.println(status.getGroup());
// 获取存储的块信息
BlockLocation[] blockLocations = status.getBlockLocations();
for (BlockLocation blockLocation : blockLocations) {
// 获取块存储的主机节点
String[] hosts = blockLocation.getHosts();
for (String host : hosts) {
System.out.println(host);
}
}
System.out.println("-----------分割线----------");
}
// 3 关闭资源
fs.close();
}
HDFS文件和文件夹判断
@Test
public void testListStatus() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件配置信息
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.228.161:9000"), configuration, "bigdata");
// 2 判断是文件还是文件夹
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for (FileStatus fileStatus : listStatus) {
// 如果是文件
if (fileStatus.isFile()) {
System.out.println("f:"+fileStatus.getPath().getName());
}else {
System.out.println("d:"+fileStatus.getPath().getName());
}
}
// 3 关闭资源
fs.close();
}
MapReduce
MapReduce是一个分布式运算编程框架,是用户开发基于Hadoop的数据分析应用的核心框架
MapReduce的核心功能就是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发布在一个hadoop集群上
MapReduce优缺点
优点
- MapReduce易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。 - 良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。 - 高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。 - 适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力
缺点
- 不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。 - 不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。 - 不擅长DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下
MapReduce核心思想
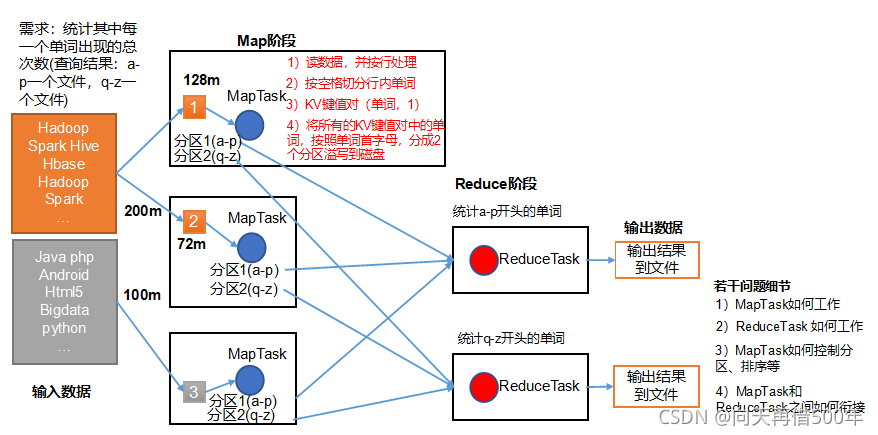
1)分布式的运算程序往往需要分成至少2个阶段。
2)第一个阶段的MapTask并发实例,完全并行运行,互不相干。
3)第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
4)MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
总结:分析WordCount数据流走向深入理解MapReduce核心思想
一个完整的MapReduce程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调
(2)MapTask:负责Map阶段的整个数据处理流程。
(3)ReduceTask:负责Reduce阶段的整个数据处理流程。
常用数据序列化类型
| java类型 | hadoop Writable 类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Null | NullWritable |
MapReduce编程
用户编写的程序分成三个部分:Mapper、Reducer和Driver。
Mapper阶段
- 用户自定义的Mapper要继承自己的父类
- Mapper的输入数据是KV对的形式(kv类型可以自定义)
- Mapper中的业务逻辑写在map()方法中
- Mapper的数据是KV对的形式(kv类型可以自定义)
- map()方法Map Task进程对每一个<K,V>调用一次
Reducer阶段
- 用户定义的Reducer要继承自己的父类
- Reducer的输入数据类型对应Mapper输出数据类型,也是 KV
- Reducer的业务逻辑写在reduce()方法中
- ReducerTask进程对每一组相同的<K,V>组调用一次reduce()方法
3.Driver
相当于YARN的集群客户端,用于提交我们整个YARN集群,提交的是封装了MapReduce程序相关运行参数的obj对象
Mapreduce WordCount案例实操
依赖
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.2</version>
</dependency>
</dependencies>
配置文件 log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
Mapper类
package com.bigdata.mapreduce;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 输出
for (String word : words) {
k.set(word);
context.write(k, v);
}
}
}
Reducer类
package com.bigdata.mapreduce
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {
// 1 累加求和
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 输出
v.set(sum);
context.write(key,v);
}
}
Driver驱动类
package com.bigdata.mapreduce
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取配置信息以及封装任务
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
// 2 设置jar加载路径
job.setJarByClass(WordcountDriver.class);
// 3 设置map和reduce类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
// 4 设置map输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
maven打包上传
jar后面的参数分别是 jar包的名字,主类的包路径,输入文件路径 输出文件路径
sbin/start-dfs.sh
sbin/start-yarn.sh
hadoop jar wc.jar com.bigdata.mr.wordcount.WordcountDriver /user/bigdata/input /user/bigdata/output
zookeeper
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目
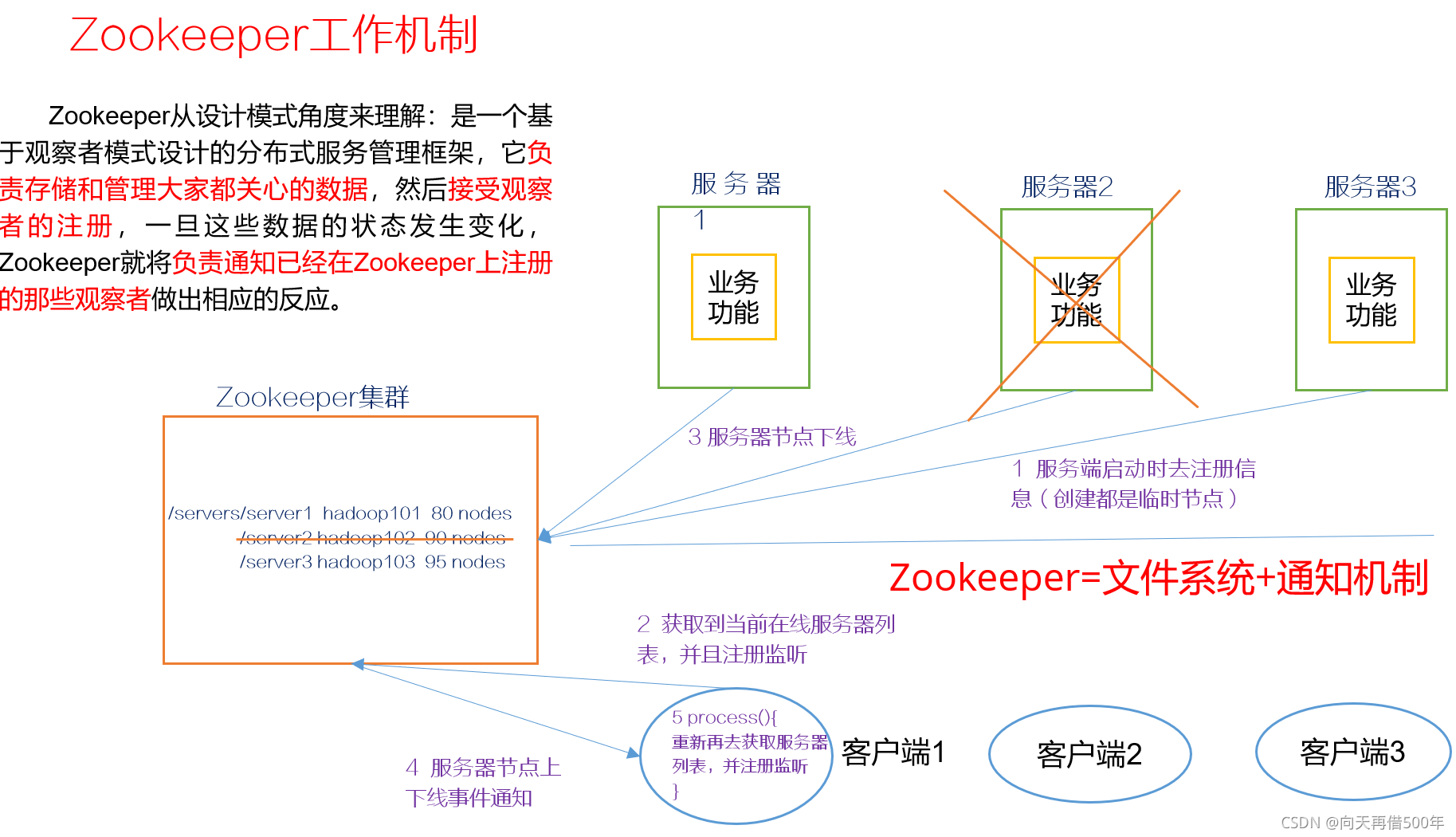
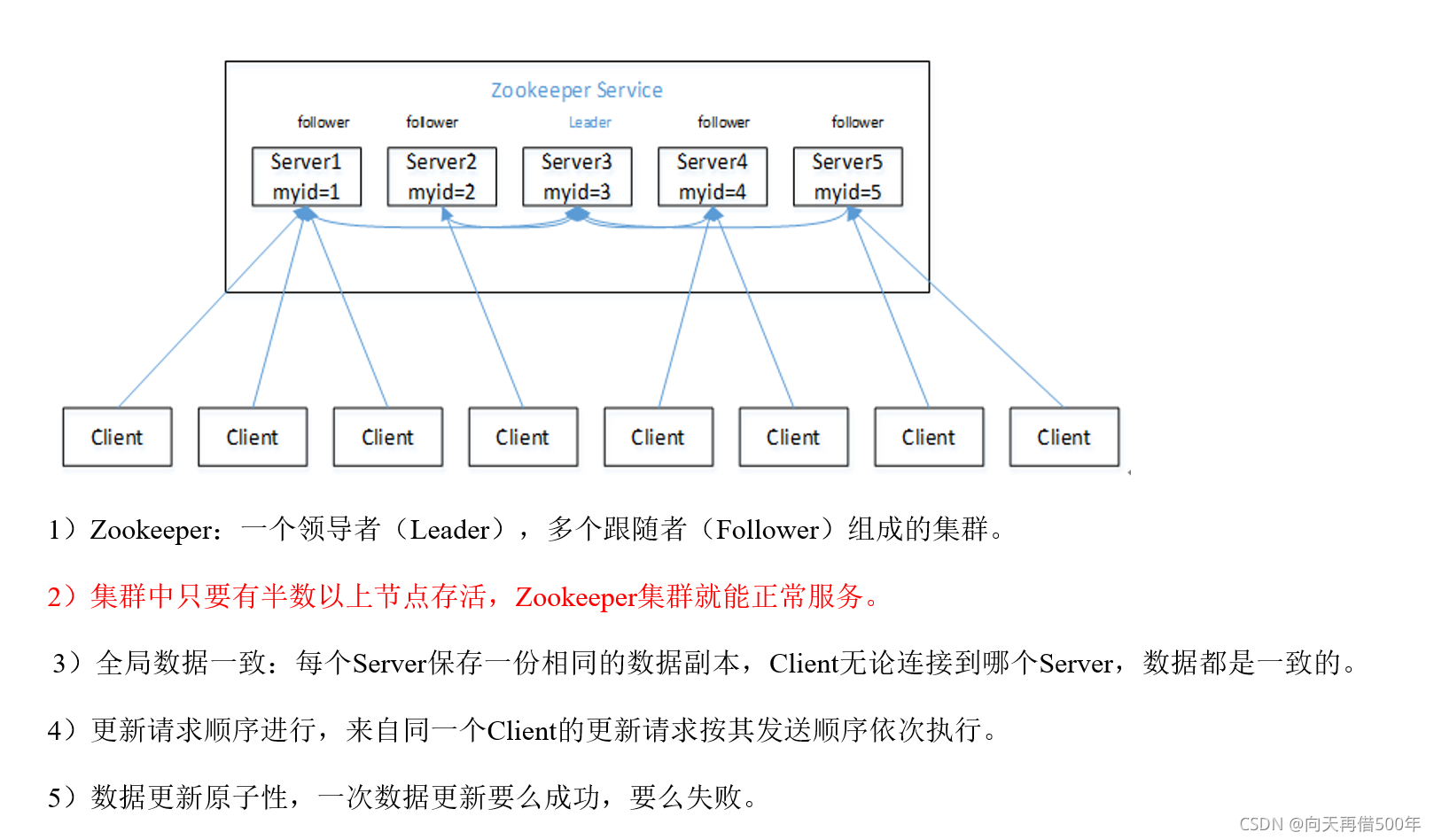
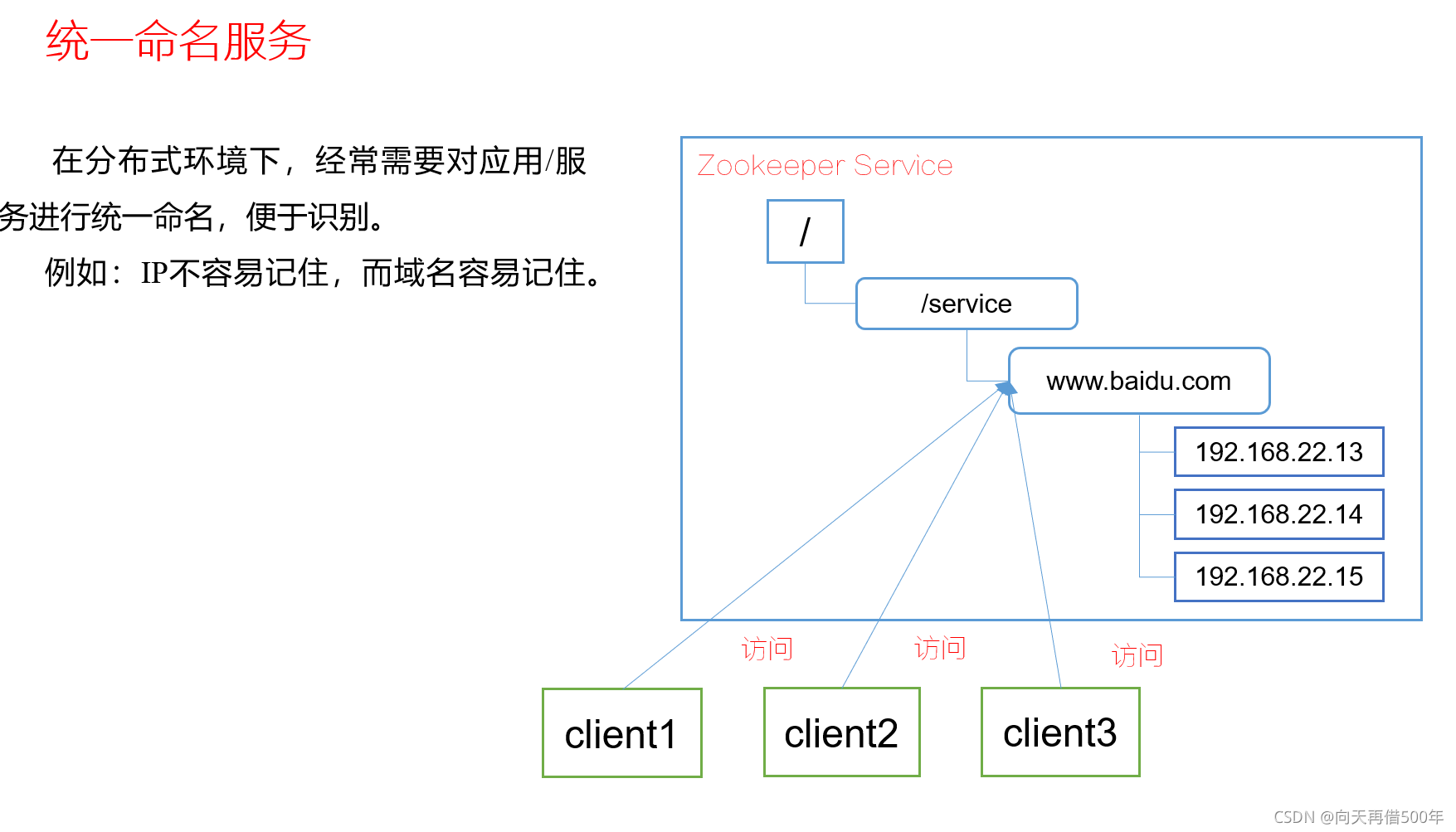
应用场景
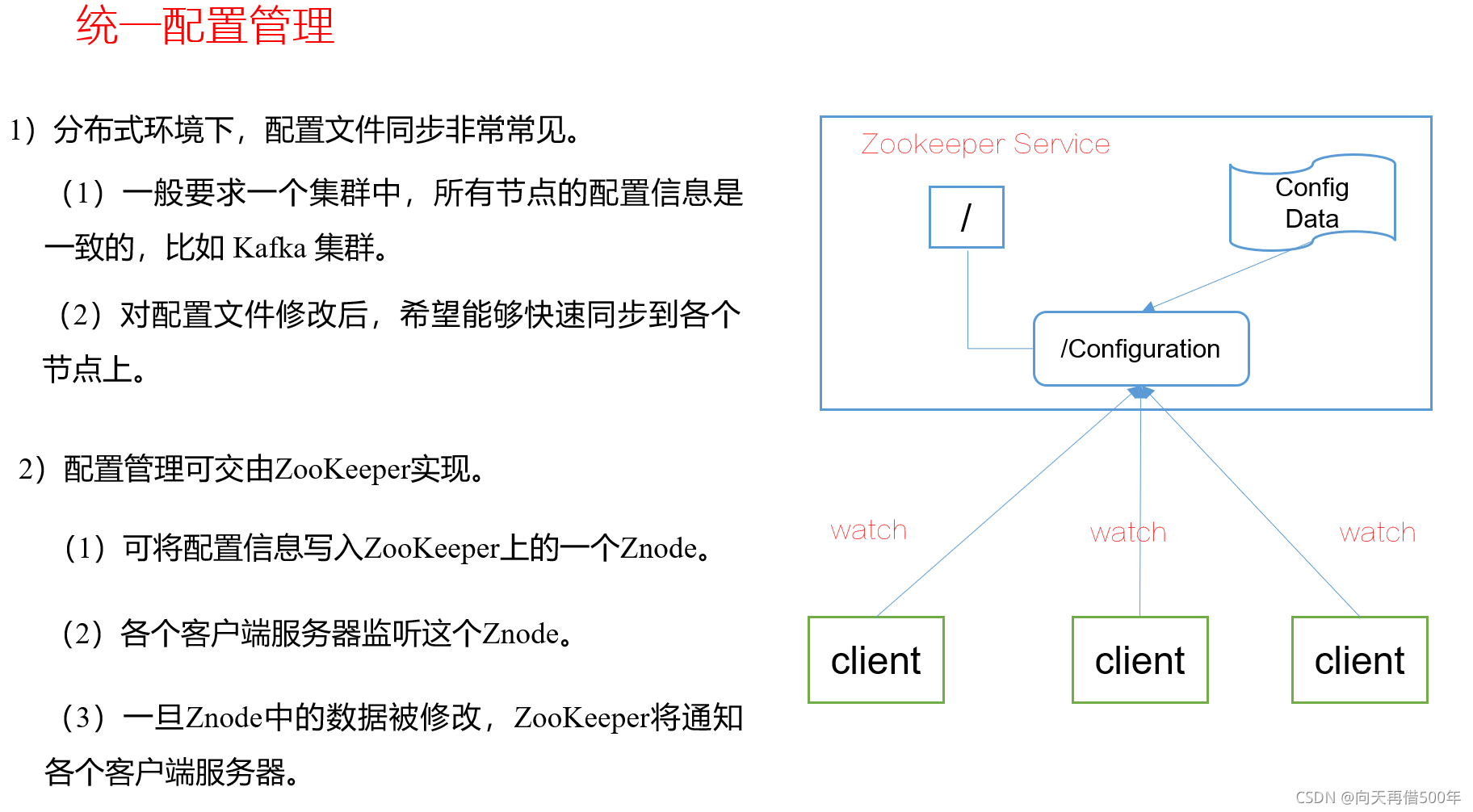
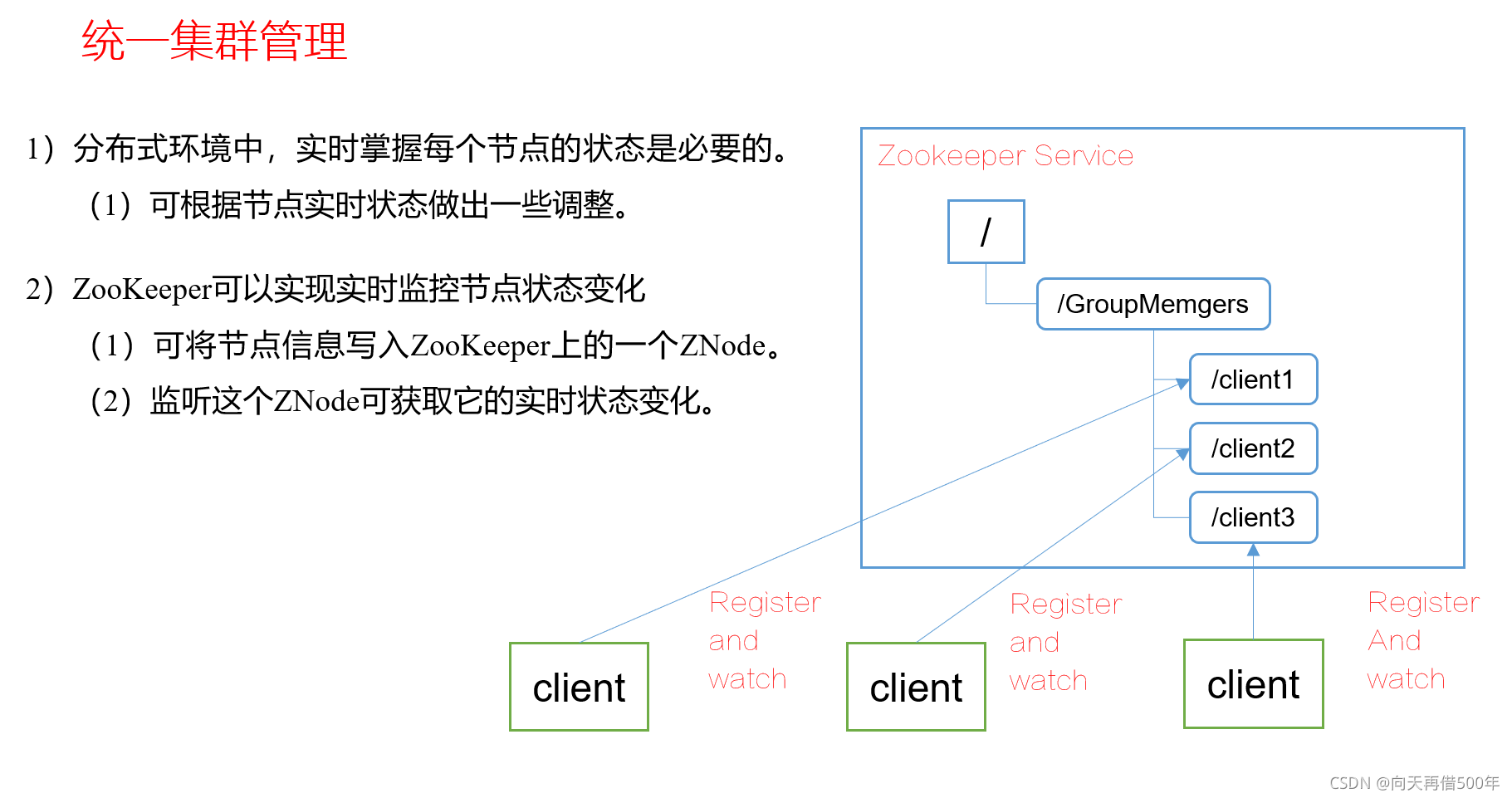
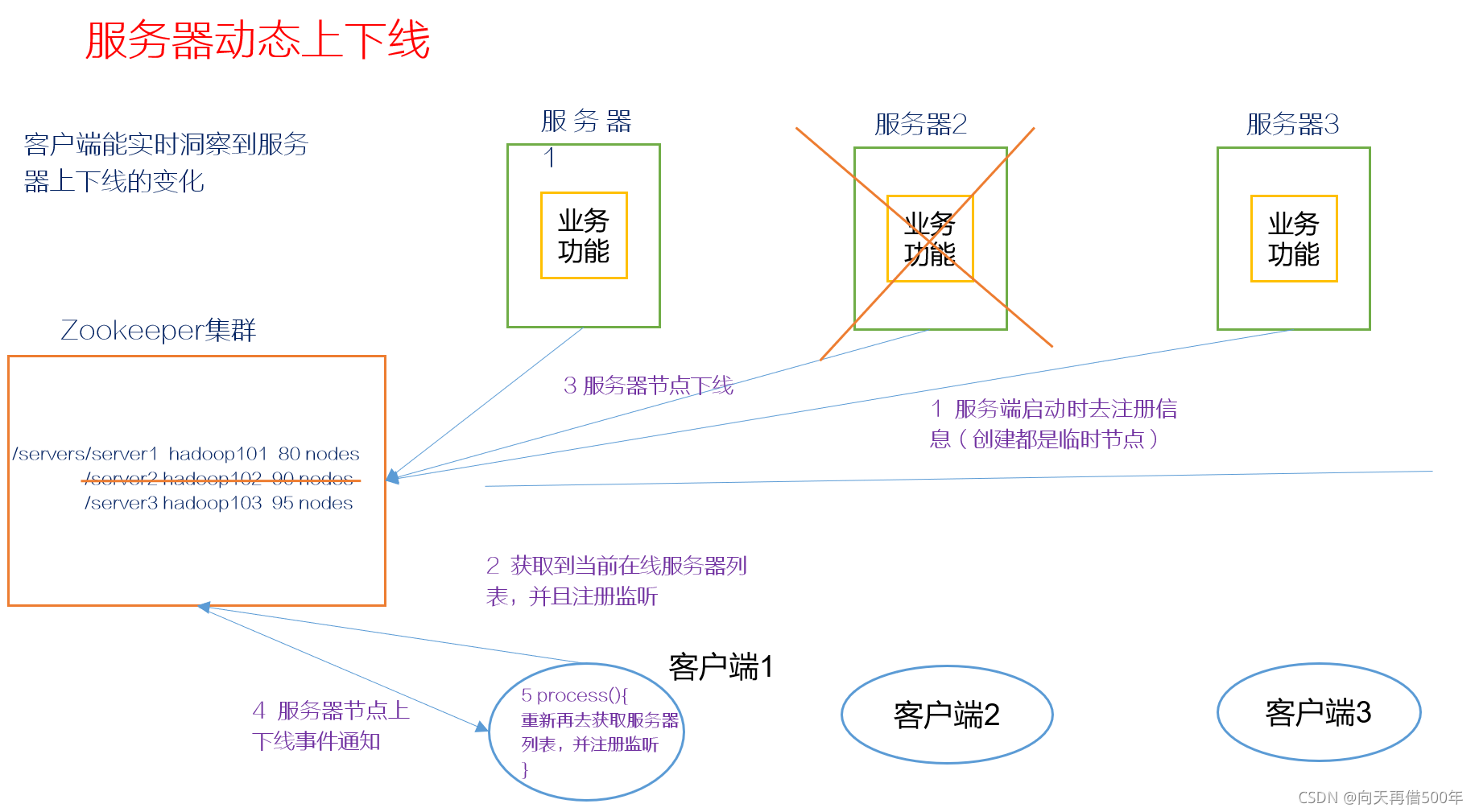
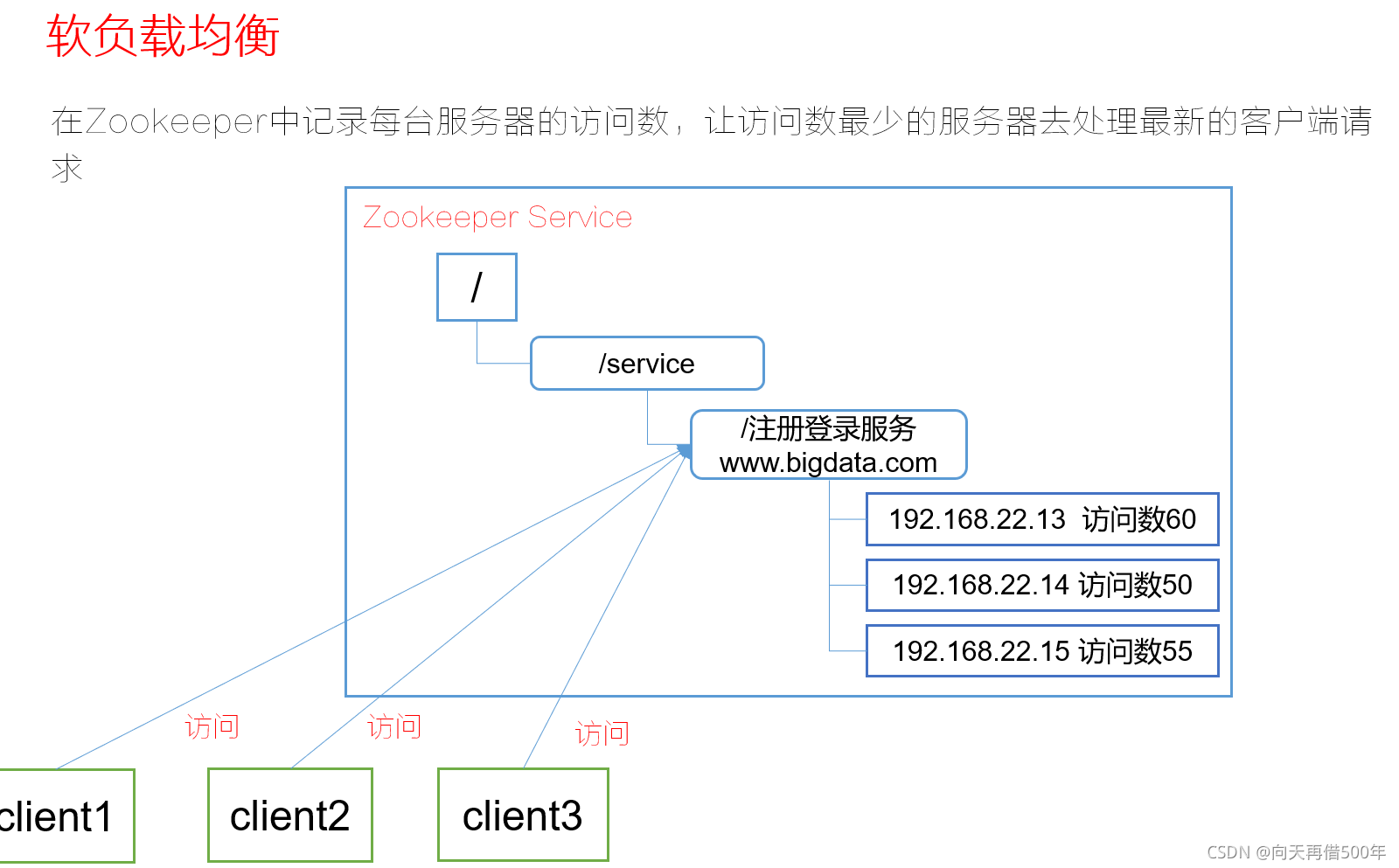
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等
zookeeper环境搭建
下载zookeeper上传到linux上面
解压
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module
cd /opt/module
# 重命名
mv zookeeper-3.4.10 zookeeper
修改配置文件
cd zookeeper
cd conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
#添加
dataDir=/opt/module/zookeeper/data
#添加内容
dataLogDir=/opt/module/zookeeper/log
server.1=hadoop102:2888:3888
server.2=hadoop103:2888:3888
server.3=hadoop104:2888:3888
cd ..
mkdir -m 777 data
mkdir -m 777 log
添加集群id
cd data
vi myid
#添加
1
复制文件到其他服务器
cd /opt/module
scp -r /opt/module/zookeeper bigdata@hadoop103:/opt/module
scp -r /opt/module/zookeeper bigdata@hadoop104:/opt/module
修改环境变量(三台同样执行)
su root
123456
vi /etc/profile
export ZOOKEEPER_HOME=/opt/module/zookeeper
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin
# 立即生效环境变量
source /etc/profile
# 切换普通用户
su bigdata
修改配置文件
到hadoop103上:修改myid为:2
cd /opt/module/zookeeper/data
vi myid
2
到hadoop104上:修改myid为:3
cd /opt/module/zookeeper/data
vi myid
3
启动(每台机器
zkServer.sh start
jps
zkServer.sh status
ZooInspector【连接zookeeper终端】
cd C:\ZooInspector\build
java -jar zookeeper-dev-ZooInspector.jar
HBase
HBase环境搭建
上传解压
cd /opt/software
tar -zxvf hbase-1.3.1-bin.tar.gz -C /opt/module
cd /opt/module
# 修改目录名字
mv hbase-1.3.1/ hbase
修改配置文件
cd hbase/conf
vi hbase-env.sh
# 将注释取消修改 27行左右
export JAVA_HOME=/opt/module/jdk1.8.0_251
# 将注释取消修改为false 128行左右
export HBASE_MANAGES_ZK=false
vi hbase-site.xml
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper/data</value>
</property>
vi regionservers
#添加
hadoop102
hadoop103
hadoop104
环境变量【每台机器都要执行】
su root
vi /etc/profile
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$HBASE_HOME/bin
source /etc/profile
su bigdata
启动
start-dfs.sh
start-yarn.sh
# zookeeper启动(三台同时执行)
zkServer.sh start
# HBase启动
start-hbase.sh
# HBase停止
stop-hbase.sh
hbase shell
访问
http://hadoop102:16010
Hbase的启动顺序为:zookeeper ->hadoop -> hbase
Hbase的停止顺序为:hbase -> hadoop -> zookeeper
HBaseAPI
获取Configuration对象
public static Configuration conf;
//静态代码块随着类加载加载初始化
static {
String ip="192.168.228.161,192.168.228.162,192.168.228.163";
// 使用 HBaseConfiguration 的单例方法实例化
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", ip);
conf.set("hbase.zookeeper.property.clientPort", "2181");
}
判断表是否存在
//判断表是否才存在
public static boolean isTableExist(String tableName) throws IOException {
// 在 HBase 中管理、访问表需要先创建 HBaseAdmin 对象
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
return admin.tableExists(TableName.valueOf(tableName));
}
创建表
//创建表
public static void createTable(String tableName, String... columnFamily) throws IOException {
// 在 HBase 中管理、访问表需要先创建 HBaseAdmin 对象
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
// 判断表是否存在
if (isTableExist(tableName)) {
System.out.println("表" + tableName + "已存在");
// System.exit(0);
} else {
// 创建表属性对象,表名需要转字节
// HTableDescriptor 表的描述器
// 创建表需要的是列族,不需要表
HTableDescriptor descriptor = new HTableDescriptor(TableName.valueOf(tableName));
// 创建多个列族
for (String cf : columnFamily) {
descriptor.addFamily(new HColumnDescriptor(cf));
}
// 根据对表的配置,创建表
admin.createTable(descriptor);
System.out.println("表" + tableName + "创建成功!");
}
}
删除表
//删除表
public static void dropTable(String tableName) throws IOException {
// 在 HBase 中管理、访问表需要先创建 HBaseAdmin 对象
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
if (isTableExist(tableName)) {
admin.disableTables(tableName);
admin.deleteTables(tableName);
System.out.println("表" + tableName + "删除成功!");
} else {
System.out.println("表" + tableName + "不存在!");
}
}
向表中插入数据
//向表中插入数据
public static void addRowData(String tableName, String rowKey, String columnFamily, String column, String value)
throws IOException {
// 创建 HTable 对象
Connection connection = ConnectionFactory.createConnection(conf);// 新的api
Table table = connection.getTable(TableName.valueOf(tableName));
// 向表中插入数据
Put put = new Put(Bytes.toBytes(rowKey)); // 要求是字节数组,转换为(Bytes.toBytes)
// 向 Put 对象中组装数据
// put.add() 封装到一个新的单元格
// 用于添加多条数据
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));
table.put(put);
// hTable.put(Put); put对象
// hTable.put(); list集合
table.close();
System.out.println("插入数据成功");
}
package com.blb;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class HbaseApi {
public static Configuration conf;
//静态代码块随着类加载加载初始化
static {
String ip="192.168.228.161,192.168.228.162,192.168.228.163";
// 使用 HBaseConfiguration 的单例方法实例化
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", ip);
conf.set("hbase.zookeeper.property.clientPort", "2181");
}
public static void main(String[] args) throws IOException {
//判断表是否才存在
//System.out.println(isTableExist("student"));
//创建表
// createTable("student","info");
//删除表
// dropTable("student");
addRowData("student","1001","info","age","18");
}
//判断表是否才存在
public static boolean isTableExist(String tableName) throws IOException {
// 在 HBase 中管理、访问表需要先创建 HBaseAdmin 对象
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
return admin.tableExists(TableName.valueOf(tableName));
}
//创建表
public static void createTable(String tableName, String... columnFamily) throws IOException {
// 在 HBase 中管理、访问表需要先创建 HBaseAdmin 对象
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
// 判断表是否存在
if (isTableExist(tableName)) {
System.out.println("表" + tableName + "已存在");
// System.exit(0);
} else {
// 创建表属性对象,表名需要转字节
// HTableDescriptor 表的描述器
// 创建表需要的是列族,不需要表
HTableDescriptor descriptor = new HTableDescriptor(TableName.valueOf(tableName));
// 创建多个列族
for (String cf : columnFamily) {
descriptor.addFamily(new HColumnDescriptor(cf));
}
// 根据对表的配置,创建表
admin.createTable(descriptor);
System.out.println("表" + tableName + "创建成功!");
}
}
//删除表
public static void dropTable(String tableName) throws IOException {
// 在 HBase 中管理、访问表需要先创建 HBaseAdmin 对象
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
if (isTableExist(tableName)) {
admin.disableTables(tableName);
admin.deleteTables(tableName);
System.out.println("表" + tableName + "删除成功!");
} else {
System.out.println("表" + tableName + "不存在!");
}
}
//向表中插入数据
public static void addRowData(String tableName, String rowKey, String columnFamily, String column, String value)
throws IOException {
// 创建 HTable 对象
Connection connection = ConnectionFactory.createConnection(conf);// 新的api
Table table = connection.getTable(TableName.valueOf(tableName));
// 向表中插入数据
Put put = new Put(Bytes.toBytes(rowKey)); // 要求是字节数组,转换为(Bytes.toBytes)
// 向 Put 对象中组装数据
// put.add() 封装到一个新的单元格
// 用于添加多条数据
put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(column), Bytes.toBytes(value));
table.put(put);
// hTable.put(Put); put对象
// hTable.put(); list集合
table.close();
System.out.println("插入数据成功");
}
}