1. 任务
【任务八-特征工程2】分别用IV值和随机森林挑选特征,再构建模型,进行模型评估
2. 用IV值特征选择
2.1 IV值
IV的全称是Information Value,中文意思是信息价值,或者信息量
2.1.1 IV的计算
为了介绍IV的计算方法,我们首先需要认识和理解另一个概念——WOE,因为IV的计算是以WOE为基础的。
2.1.2 WOE
WOE的全称是“Weight of Evidence”,即证据权重。WOE是对原始自变量的一种编码形式。
要对一个变量进行WOE编码,需要首先把这个变量进行分组处理(也叫离散化、分箱等等,说的都是一个意思)。分组后,对于第i组,WOE的计算公式如下:
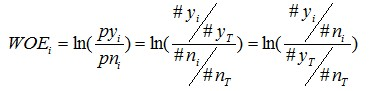
pyi是这个组中响应客户(风险模型中,对应的是违约客户,总之,指的是模型中预测变量取值为“是”或者说1的个体)占所有样本中所有响应客户的比例,pni是这个组中未响应客户占样本中所有未响应客户的比例,#yi是这个组中响应客户的数量,#ni是这个组中未响应客户的数量,#yT是样本中所有响应客户的数量,#nT是样本中所有未响应客户的数量。
WOE越大,这种差异越大,这个分组里的样本响应的可能性就越大,WOE越小,差异越小,这个分组里的样本响应的可能性就越小
2.1.3 IV的计算公式
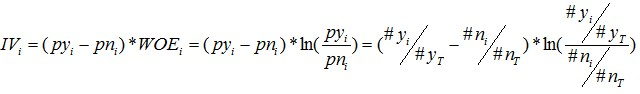
有了一个变量各分组的IV值,我们就可以计算整个变量的IV值,方法很简单,就是把各分组的IV相加:
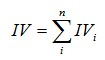
3. 用随机森林特征选择
3.1 特征重要性
随机森林一个重要特征:能够计算单个特征变量的重要性。
3.1.1 计算方法
-
对于随机森林中的每一颗决策树,使用相应的OOB(袋外数据)数据来计算它的袋外数据误差,记为errOOB1.
-
随机地对袋外数据OOB所有样本的特征X加入噪声干扰(就可以随机的改变样本在特征X处的值),再次计算它的袋外数据误差,记为errOOB2.
-
假设随机森林中有Ntree棵树,那么对于特征X的重要性=∑(errOOB2-errOOB1)/Ntree,之所以可以用这个表达式来作为相应特征的重要性的度量值是因为:若给某个特征随机加入噪声之后,袋外的准确率大幅度降低,则说明这个特征对于样本的分类结果影响很大,也就是说它的重要程度比较高。
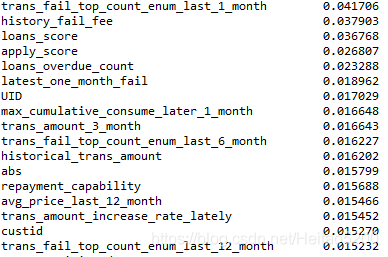
实验结果
代码
#!/usr/bin/env python 3.6
#-*- coding:utf-8 -*-
# @File : IV.py
# @Date : 2018-11-27
# @Author : 黑桃
# @Software: PyCharm
#
# # -*- coding:utf-8 -*-
# # Author:Bemyid
# from fancyimpute import BiScaler, KNN, NuclearNormMinimization
import pandas as pd
import math
import numpy as np
from scipy import stats
from sklearn.utils.multiclass import type_of_target
from sklearn.linear_model import LogisticRegression
from sklearn import svm
from sklearn.tree import DecisionTreeClassifier
from xgboost.sklearn import XGBClassifier
from lightgbm.sklearn import LGBMClassifier
from mlxtend.classifier import StackingClassifier
from sklearn.metrics import accuracy_score, roc_auc_score
import warnings
import pickle
from sklearn.ensemble import RandomForestClassifier
warnings.filterwarnings("ignore")
path = "E:/MyPython/Machine_learning_GoGoGo/"
"""
0 读取特征
"""
print("0 读取特征")
f = open(path + 'feature/feature_V2.pkl', 'rb')
train, test, y_train, y_test = pickle.load(f)
data = pd.read_csv(path + 'data_set/data.csv',encoding='gbk')
f.close()
def predict(clf, train, test, y_train, y_test):
# 预测
y_train_pred = clf.predict(train)
y_test_pred = clf.predict(test)
y_train_proba = clf.predict_proba(train)[:, 1]
y_test_proba = clf.predict_proba(test)[:, 1]
# 准确率
print('[准确率]')
print('训练集:', '%s' % accuracy_score(y_train, y_train_pred), end=' ')
print('测试集:', '%s' % accuracy_score(y_test, y_test_pred))
# auc取值:用roc_auc_score或auc
print('[auc值]')
print('训练集:', '%s' % roc_auc_score(y_train, y_train_proba), end=' ')
print('测试集:', '%s' % roc_auc_score(y_test, y_test_proba))
"""
2 随机森林挑选特征
"""
forest = RandomForestClassifier(oob_score=True,n_estimators=100, random_state=0,n_jobs=1)
forest.fit(train, y_train)
print('袋外分数:', forest.oob_score_)
predict(forest,train, test, y_train, y_test)
feature_impotance1 = sorted(zip(map(lambda x: '%.4f'%x, forest.feature_importances_), list(train.columns)), reverse=True)
print(feature_impotance1[:10])
def woe(X, y, event=1):
res_woe = []
iv_dict = {}
for feature in X.columns:
x = X[feature].values
# 1) 连续特征离散化
if type_of_target(x) == 'continuous':
x = discrete(x)
# 2) 计算该特征的woe和iv
# woe_dict, iv = woe_single_x(x, y, feature, event)
woe_dict, iv = woe_single_x(x, y, feature, event)
iv_dict[feature] = iv
res_woe.append(woe_dict)
return iv_dict
def discrete(x):
# 使用5等分离散化特征
res = np.zeros(x.shape)
for i in range(5):
point1 = stats.scoreatpercentile(x, i * 20)
point2 = stats.scoreatpercentile(x, (i + 1) * 20)
x1 = x[np.where((x >= point1) & (x <= point2))]
mask = np.in1d(x, x1)
res[mask] = i + 1 # 将[i, i+1]块内的值标记成i+1
return res
def woe_single_x(x, y, feature, event=1):
# event代表预测正例的标签
event_total = sum(y == event)
non_event_total = y.shape[-1] - event_total
iv = 0
woe_dict = {}
for x1 in set(x): # 遍历各个块
y1 = y.reindex(np.where(x == x1)[0])
event_count = sum(y1 == event)
non_event_count = y1.shape[-1] - event_count
rate_event = event_count / event_total
rate_non_event = non_event_count / non_event_total
if rate_event == 0:
rate_event = 0.0001
# woei = -20
elif rate_non_event == 0:
rate_non_event = 0.0001
# woei = 20
woei = math.log(rate_event / rate_non_event)
woe_dict[x1] = woei
iv += (rate_event - rate_non_event) * woei
return woe_dict, iv
import warnings
warnings.filterwarnings("ignore")
iv_dict = woe(train, y_train)
iv = sorted(iv_dict.items(), key = lambda x:x[1],reverse = True)
useless = []
for feature in train.columns:
if feature in [t[1] for t in feature_impotance1[50:]] and feature in [t[1] for t in feature_impotance2[50:]]:
useless.append(feature)
print(feature, iv_dict[feature])
train.drop(useless, axis = 1, inplace = True)
test.drop(useless, axis = 1, inplace = True)
importance = forest.feature_importances_
imp_result = pd.DataFrame(importance)
imp_result.columns=["impor"]
rf_impc = pd.Series(forest.feature_importances_, index=train.columns).sort_values(ascending=False)
lr = LogisticRegression(C = 0.1, penalty = 'l1')
svm_linear = svm.SVC(C = 0.01, kernel = 'linear', probability=True)
svm_poly = svm.SVC(C = 0.01, kernel = 'poly', probability=True)
svm_rbf = svm.SVC(gamma = 0.01, C =0.01 , probability=True)
svm_sigmoid = svm.SVC(C = 0.01, kernel = 'sigmoid',probability=True)
dt = DecisionTreeClassifier(max_depth=5,min_samples_split=50,min_samples_leaf=60, max_features=9, random_state =2333)
xgb = XGBClassifier(learning_rate =0.1, n_estimators=80, max_depth=3, min_child_weight=5,
gamma=0.2, subsample=0.8, colsample_bytree=0.8, reg_alpha=1e-5,
objective= 'binary:logistic', nthread=4,scale_pos_weight=1, seed=27)
lgb = LGBMClassifier(learning_rate =0.1, n_estimators=100, max_depth=3, min_child_weight=11,
gamma=0.1, subsample=0.5, colsample_bytree=0.9, reg_alpha=1e-5,
nthread=4,scale_pos_weight=1, seed=27)
sclf = StackingClassifier(classifiers=[svm_linear, svm_poly, svm_rbf, svm_sigmoid, dt, xgb, lgb],
meta_classifier=lr, use_probas=True,average_probas=False)
sclf.fit(train, y_train.values)
predict(sclf, train, test, y_train, y_test)
[准确率] 训练集: 0.8264 测试集: 0.7917
[auc值] 训练集: 0.8921 测试集: 0.7895