1. 朴素贝叶斯的原理
基本方法:
朴素贝叶斯是典型的生成学习方法,生成方法由训练数据学习联合概率分布P(X,Y),然后求得后验概率分布P(Y|X),具体来讲,就是利用训练数据学习P(X|Y)的估计,得到联合概率分布:P(X,Y)=P(Y)P(X|Y),概率估计方法可是极大似然估计或是贝叶斯估计。
2. 利用朴素贝叶斯模型进行文本分类
文本分类步骤
(1)定义阶段:定义数据以及分类体系,具体分为哪些类别,需要哪些数据
(2)数据预处理:对文档做分词,去停用词
(3)数据提取特征:对文档矩阵进行降维,提取训练中最有用的特征
(4)模型训练阶段:选择具体的分类模型及算法,训练出文本分类器
(5)评测阶段:在测试集上测试并评测分类器的性能
(6)应用阶段
import numpy as np
import sklearn
from sklearn.datasets import fetch_20newsgroups
twenty_train = fetch_20newsgroups(subset='train',shuffle = True)
twenty_train.traget_names
#词袋模型
from sklearn.feature_extraction.text import CountVectorizer
count_vect = CountVectorizer()
x_train_counts = count_vect.fit_transform(twenty_train.data) #词袋模型
#训练及给出答案
from skleran.naive_bayes import MultionmialNB
clf = MultionmialNB.fit(x_train_counts,twenty_train.target)
twenty_test = fetch_20newsgroups(subset = 'test',shuffle = True) #生成测试集
x_test_counts = count_vect.fit_transform(twenty_test.data)
predicted=clf.predict(x_test_counts)
np.mean(predicted==twenty_test.target)3. SVM的原理
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。而朴素朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。
基于朴素贝叶斯公式,比较出后验概率的最大值来进行分类,后验概率的计算是由先验概率与类条件概率的乘积得出,先验概率和类条件概率要通过训练数据集得出,即为朴素贝叶斯分类模型,将其保存为中间结果,测试文档进行分类时调用这个中间结果得出后验概率。
4. 利用SVM模型进行文本分类
支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面.
一般SVM有下面三种: 硬间隔支持向量机(线性可分支持向量机):当训练数据线性可分时,可通过硬间隔最大化学得一个线性可分支持向量机。 软间隔支持向量机:当训练数据近似线性可分时,可通过软间隔最大化学得一个线性支持向量机。 非线性支持向量机:当训练数据线性不可分时,可通过核方法以及软间隔最大化学得一个非线性支持向量机。
5. pLSA、共轭先验分布;LDA主题模型原理
每篇文档用bag-of-words模型表示,也就是每篇文档只与所包含的词有关,而不考虑这些词的先后顺序。假设文档集D有N篇文档,主题模型认为在这N篇文档中一共隐含了Z个主题,每篇文档都可能属于一个或多个主题,这可以用给定文档dd时所属主题zz的概率分布p(z|d)表示。同理,一个主题下可以包含若干个词w,用概率分布p(w|z)表示。
所以,如果我们有文档集D,又求出对应这个文档集的主题模型,那这有什么意义呢?最明显的意义就是,这相当于给文档聚类了,并且聚类的结果有更合理的解释性。因为我们不但可以知道每一篇文档dd属于哪个类别z,我们还可以根据概率p(w|z)知道这个主题的关键词是哪些,从而给这个主题zz设置合理的标签。知道文档所属的类别,我们就可以判断两篇文档在语义上是否相似了。虽然可以直接根据文档向量的余弦距离来判断它们是否相似,但是这对近义词就无能为力,比如两篇同样介绍电子产品的文档,一篇大量用“苹果”这个关键词,而另一篇大量用“iPhone”,那么通过余弦距离判断的这两个维度上肯定是不相似的。而“苹果”、“iPhone”两个词都与电子产品关系很大,所以这两篇文档可以都属于同一个主题,也就可以断定他们语义上是相似的。
主题模型的用处还是很多的,在推荐系统,舆情监控等等,都有广泛的用途。
pLSA
pLSA(Probabilistic Latent Senmantic Indexing)是Hoffman在1999年提出的基于概率的隐语义分析。之所以说是probabilistic,是因为这个模型中还加入了一个隐变量:主题Z ,也正因为此,它被称之为主题模型。
共轭先验分布
定义及公式
设θ是总体分布中的参数(或参数向量),π(θ)是θ的先验密度函数,假如由抽样信息算得的后验密度函数与π(θ)有相同的函数形式,则称π(θ)是θ的(自然)共轭先验分布。
这里通过举一个例子来展示何为共轭先验分布。
设一事件A的概率p(A)=θ。为了估计θ的值,作了n次独立观察,其中事件A出现的次数为X,显然X服从二项分布X∼B(n,θ)。 因此 :

利用贝叶斯公式,我们首先需要确定先验概率p(θ)。在未得到其余信息前,我们只能认为θ在(0,1)上均匀分布,这是一种不失偏颇的先验估计。
到这里我们就已经可以计算出p(x,θ)这一联合概率分布。

然后通过联合概率分布,我们又可以得出p(x)的边缘概率分布。

综合以上可得θθ的后验分布:
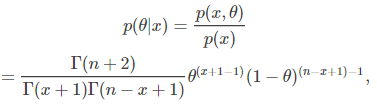
细心点就会发现这个分布就是参数为(x+1)和(n−x+1)(x+1)和(n−x+1)的贝塔分布,即p(θ|x) Be(x+1,n−x+1)p(θ|x) Be(x+1,n−x+1)。更奇妙的是先验分布p(θ)p(θ),区间(0,1)上的均匀分布也是一种特殊的贝塔分布Be(1,1)。
LDA介绍
LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生成模型,就是说,我们认为一篇文章的每个词都是通过“以一定概率选择了某个主题,并从这个主题中以一定概率选择某个词语”这样一个过程得到。文档到主题服从多项式分布,主题到词服从多项式分布。
LDA是一种非监督机器学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
LDA生成过程
对于语料库中的每篇文档,LDA定义了如下生成过程(generativeprocess):
对每一篇文档,从主题分布中抽取一个主题;
从上述被抽到的主题所对应的单词分布中抽取一个单词;
重复上述过程直至遍历文档中的每一个单词。
语料库中的每一篇文档与T(通过反复试验等方法事先给定)个主题的一个多项分布 (multinomialdistribution)相对应,将该多项分布记为θ。每个主题又与词汇表(vocabulary)中的V个单词的一个多项分布相对应,将这个多项分布记为φ。
LDA整体流程
文档集合D,主题集合T。
D中每个文档d看作一个单词序列<w1, w2, …… ,wn>,wi表示第i个单词,设d有n个单词。(LDA里面称之为wordbag,实际上每个单词的出现位置对LDA算法无影响)
文档集合D中的所有单词组成一个大集合VOCABULARY(简称VOC)。
LDA以文档集合D作为输入,希望训练出两个结果向量(设聚成k个topic,VOC中共包含m个词)。
对每个D中的文档d,对应到不同Topic的概率θd<pt1,...,ptk>,其中,pti表示d对应T中第i个topic的概率。计算方法是直观的,pti=nti/n,其中nti表示d中对应第i个topic的词的数目,n是d中所有词的总数。
对每个T中的topic,生成不同单词的概率φt<pw1,...,pwm>,其中,pwi表示t生成VOC中第i个单词的概率。计算方法同样很直观,pwi=Nwi/N,其中Nwi表示对应到topict的VOC中第i个单词的数目,N表示所有对应到topict的单词总数。
LDA的核心公式如下:
p(w|d)=p(w|t)*p(t|d)
直观的看这个公式,就是以Topic作为中间层,可以通过当前的θd和φt给出了文档d中出现单词w的概率。其中p(t|d)利用θd计算得到,p(w|t)利用φt计算得到。
实际上,利用当前的θd和φt,我们可以为一个文档中的一个单词计算它对应任意一个Topic时的p(w|d),然后根据这些结果来更新这个词应该对应的topic。然后,如果这个更新改变了这个单词所对应的Topic,就会反过来影响θd和φt。
6. 使用LDA生成主题特征,在之前特征的基础上加入主题特征进行文本分类
import numpy as np
import lda
# X:n*m的矩阵,表示有n个文本,m个单词,值表示出现次数或者是否出现。
X = np.genfromtxt("data\\source_wzp_lda_1.txt", skip_header=1, dtype=np.int)
# vocab是m个单词组成的list
file_vocab = open("data\\vectoritems_lda_3.txt", "r")
vocab = (file_vocab.read().decode("utf-8").split("\n"))[0:-1]
print len(vocab)
#指定11个主题,500次迭代
model = lda.LDA(random_state=1, n_topics=11, n_iter=1000)
model.fit(X)
# 主题-单词(topic-word)分布
topic_word = model.topic_word_
print("type(topic_word): {}".format(type(topic_word)))
print("shape: {}".format(topic_word.shape))
# 获取每个topic下权重最高的10个单词
n = 10
for i, topic_dist in enumerate(topic_word):
topic_words = np.array(vocab)[np.argsort(topic_dist)][:-(n + 1):-1]
print("topic {}\n- {}".format(i, ('-'.join(topic_words)).encode("utf-8")))
# 文档主题(Document-Topic)分布:
doc_topic = model.doc_topic_
print("type(doc_topic): {}".format(type(doc_topic)))
print("shape: {}".format(doc_topic.shape))
# 一篇文章对应一行,每行的和为1
# 输入前10篇文章最可能的Topic
for n in range(20):
'''
for i in doc_topic[n]:
print i
'''
topic_most_pr = doc_topic[n].argmax()
print("doc: {} topic: {}".format(n, topic_most_pr))
7. 参考 朴素贝叶斯1:sklearn:朴素贝叶斯(naïve beyes) - 专注计算机体系结构 - CSDN博客 LDA数学八卦 lda2:用LDA处理文本(Python) - 专注计算机体系结构 - CSDN博客 合并特征:Python:合并两个numpy矩阵 - 专注计算机体系结构 - CSDN博客python机器学习:朴素贝叶斯分类算法 https://mp.weixin.qq.com/s?src=11×tamp=1552023306&ver=1471&signature=VdN1JOPo8XxCAGbNGak0CoxnWRWZlZtWKOGdQoqpV*Z2q305Xhqk8CUdYYuI85IP5SmfdD0Z7AzxPUDdmPTXAJVZOwRUqekVz*6fSVNmX07ZI46EduKEU*1jXxfG2qSs&new=1
朴素贝叶斯实战篇之新浪新闻分类 https://blog.csdn.net/c406495762/article/details/77500679
朴素贝叶斯实战篇之新浪新闻分类 https://github.com/Jack-Cherish/Machine-Learning/tree/master/Naive%20Bayes
基于支持向量机SVM的文本分类的实现 https://blog.csdn.net/qq_30189255/article/details/54571370
文本建模系列之二:pLSA https://blog.csdn.net/u010223750/article/details/51334584
LSA,pLSA原理及其代码实现 https://www.cnblogs.com/bentuwuying/p/6219970.html
LSA,pLSA原理及其代码实现 https://blog.csdn.net/thriving_fcl/article/details/50878845
主题模型(概率潜语义分析PLSA、隐含狄利克雷分布LDA) https://www.cnblogs.com/softzrp/p/6964951.html
用LDA处理文本(Python) https://blog.csdn.net/u013710265/article/details/73480332