条件随机场
马尔可夫过程
定义
假设一个随机过程中,
tn 时刻的状态
xn的条件发布,只与其前一状态
xn−1 相关,即:
P(xn∣x1,x2,...,xn−1)=P(xn∣xn−1)
则将其称为 马尔可夫过程。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wTcnB5QJ-1588083401296)(img/马尔可夫过程.png)]](https://img-blog.csdnimg.cn/20200428221656234.png)
隐马尔科夫算法
定义
隐马尔科夫算法是对含有未知参数(隐状态)的马尔可夫链进行建模的生成模型,如下图所示:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lBfYoqPm-1588083445495)(img/隐马尔科夫算法.png)]](https://img-blog.csdnimg.cn/2020042822174091.png)
在隐马尔科夫模型中,包含隐状态 和 观察状态,隐状态
xi 对于观察者而言是不可见的,而观察状态
yi 对于观察者而言是可见的。隐状态间存在转移概率,隐状态
xi到对应的观察状态
yi 间存在输出概率。
假设
- 假设隐状态
xi 的状态满足马尔可夫过程,i时刻的状态
xi 的条件分布,仅与其前一个状态
xi−1相关,即:
P(xi∣x1,x2,...,xi−1)=P(xi∣xi−1)
- 假设观测序列中各个状态仅取决于它所对应的隐状态,即:
P(yi∣x1,x2,...,xi−1,y1,y2,...,yi−1,yi+1,...)=P(yi∣xi)
存在问题
在序列标注问题中,隐状态(标注)不仅和单个观测状态相关,还和观察序列的长度、上下文等信息相关。例如词性标注问题中,一个词被标注为动词还是名词,不仅与它本身以及它前一个词的标注有关,还依赖于上下文中的其他词。
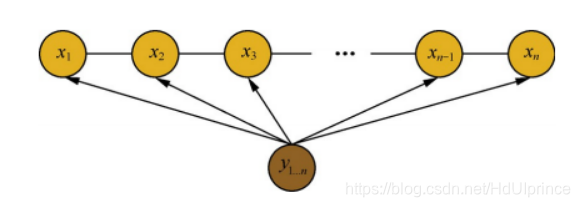
条件随机场 (以线性链条件随机场为例)
定义
给定
X=(x1,x2,...,xn) ,
Y=(y1,y2,...,yn) 均为线性链表示的随机变量序列,若在给随机变量序列 X 的条件下,随机变量序列 Y 的条件概率分布
P(Y∣X) 构成条件随机场,即满足马尔可夫性:
扫描二维码关注公众号,回复:
11165287 查看本文章

P(yi∣x1,x2,...,xi−1,y1,y2,...,yi−1,yi+1)=P(yi∣x,yi−1,yi+1)
则称为
P(Y∣X) 为线性链条件随机场。
通过去除了隐马尔科夫算法中的观测状态相互独立假设,使算法在计算当前隐状态
xi时,会考虑整个观测序列,从而获得更高的表达能力,并进行全局归一化解决标注偏置问题。
参数化形式
p(y∣x)=Z(x)1i=1∏nexp⎝⎛i,k∑λktk(yi−1,yi,x,i)+i,l∑μlsl(yi,x,i)⎠⎞
其中:
Z(x) 为归一化因子,是在全局范围进行归一化,枚举了整个隐状态序列
x1…n的全部可能,从而解决了局部归一化带来的标注偏置问题。
Z(x)=y∑exp⎝⎛i,k∑λxtk(yi−1,yi,x,i)+i,l∑μlsl(yi,x,i)⎠⎞
tk 为定义在边上的特征函数,转移特征,依赖于前一个和当前位置
s1 为定义在节点上的特征函数,状态特征,依赖于当前位置。
简化形式
因为条件随机场中同一特征在各个位置都有定义,所以可以对同一个特征在各个位置求和,将局部特征函数转化为一个全局特征函数,这样就可以将条件随机场写成权值向量和特征向量的内积形式,即条件随机场的简化形式。
step 1
将转移特征和状态特征及其权值用统一的符号表示,设有k1个转移特征,
k2个状态特征,
K=k1+k2,记
fk(yi−1,yi,x,i)={tk(yi−1,yi,x,i),sl(yi,x,i),k=1,2,⋯,K1k=K1+l;l=1,2,⋯,K2
step 2
对转移与状态特征在各个位置i求和,记作
fk(y,x)=i=1∑nfk(yi−1,yi,x,i),k=1,2,⋯,K
step 3
将
λx 和
μl 用统一的权重表示,记作
wk={λk,μl,k=1,2,⋯,K1k=K1+l;l=1,2,⋯,K2
step 4
转化后的条件随机场可表示为:
P(y∣x)Z(x)=Z(x)1expk=1∑Kwkfk(y,x)=y∑expk=1∑Kwkfk(y,x)
step 5
若
w 表示权重向量:
w=(w1,w2,...,wK)T
以
F(y,x) 表示特征向量,即
F(y,x)=(f1(y,x),f2(y,x),⋯,fK(y,x))T
则,条件随机场写成内积形式为:
Pw(y∣x)=Zw(x)exp(w⋅F(y,x))Zw(x)=∑yexp(w⋅F(y,x))
学习问题
这里主要介绍一下 BFGS 算法的思路。
输入:特征函数
f1,f2,...,fn:经验分布
P
(X,Y);
输出:最优参数值
w
,最优模型
Pw
(y∣x)。
- 选定初始点 w^{(0)}, 取
B0 为正定对称矩阵,k = 0;
- 计算
gk=g(w(k)),若
gk=0 ,则停止计算,否则转 (3) ;
- 利用
Bkpk=−gk 计算
pk;
- 一维搜索:求
λk使得
f(w(k)+λkpk)=λ>0minf(w(k)+λpk)
-
设
w(k+1)=w(k)+λk∗pk
-
计算
gk+1 = g(w^{(k+1)}),
若
gk=0, 则停止计算;否则,利用下面公式计算
Bk+1:
Bk+1=Bk+ykTδkykykT−δkTBkδkBkδkδkTBkyk=gk+1−gk,δk=w(k+1)−w(k)
7. 令
k=k+1,转步骤(3);
预测问题
对于预测问题,常用的方法是维特比算法,其思路如下:
输入:模型特征向量
F(y,x) 和权重向量
w,输入序列(观测序列)
x=x1,x2,...,xn;
输出:条件概率最大的输出序列(标记序列)
y∗=(y1∗,y2∗,...,yn∗),也就是最优路径;
- 初始化
δ1(j)=w⋅F1(y0=start,y1=j,x),j=1,2,⋯,m
Ψi(l)=arg1⩽j⩽mmax{δt−1(j)+w⋅Fi(yi−1=j,yi=l,x)},l=1,2,⋯,m
- 递推,对
i=2,3,...,n
δi(l)=1∈j⩽mmax{δt−1(j)+w⋅Fi(yi−1=j,yi=l,x)},l=1,2,⋯,m
- 终止
maxy(w⋅F(y,x))=max1≤j⩽mδn(j)yn∗=argmax1⩽j⩽mδn(j)
- 返回路径
yi∗=Ψi+1(yi+1∗),i=n−1,n−2,⋯,1
求得最优路径
y∗=(y1∗,y2∗,...,yn∗)
例子说明
利用维特比算法计算给定输入序列
x 对应的最优输出序列
y∗:
maxi=1∑3w⋅Fi(yi−1,yi,x)
- 初始化
δ1(j)=w⋅F1(y0=start,y1=j,x),j=1,2i=1,δ1(1)=1,δ1(2)=0.5
- 递推,对
i=2,3,...,n
i=2δ2(l)=max{δ1(j)+w⋅F2(j,l,x)}δ2(1)=max{1+λ2t2,0.5+λ4t4}=1.6,Ψ2(1)=1δ2(2)=max{1+λ1t1+μ2s2,0.5+μ2s2}=2.5,Ψ3(2)=1i=32δ3(l)=maxj{δ2(j)+w⋅F3(j,l,x)}δ3(1)=max{1.6+μ5s5,2.5+λt3+μ3s3}=4.3,Ψ3(1)=2δ3(2)=max{1.6+λt1+μ4s4,2.5+λ5t5+μ4s4}=3.2,Ψ3(2)=1
- 终止
maxy(w⋅F(y,x))=maxδ3(l)=δ3(1)=4.3y3∗=argmax1δ3(l)=1
4. 返回路径
y2∗=Ψ3(y3∗)=Ψ3(1)=2y1∗=Ψ2(y2∗)=Ψ2(2)=1
求得最优路径
y∗=(y1∗,y2∗,...,yn∗)=(1,2,1)
