版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wangyaninglm/article/details/84901323
5.spark dataframe 数据导入Elasticsearch
5.1 dataframe 及环境初始化
初始化, spark 第三方网站下载包:elasticsearch-spark-20_2.11-6.1.1.jar
http://spark.apache.org/third-party-projects.html
import sys
import os
print(os.getcwd())
# 加载包得放在这里
os.environ['PYSPARK_SUBMIT_ARGS'] = '--jars elasticsearch-spark-20_2.11-6.1.1.jar pyspark-shell'
import os
from pyspark.sql import SparkSession
from pyspark import SparkConf
from pyspark.sql.types import *
from pyspark.sql import functions as F
from pyspark.storagelevel import StorageLevel
import json
import math
import numbers
import numpy as np
import pandas as pd
os.environ["PYSPARK_PYTHON"] = "/home/hadoop/anaconda/envs/playground_py36/bin/python"
try:
spark.stop()
print("Stopped a SparkSession")
except Exception as e:
print("No existing SparkSession")
SPARK_DRIVER_MEMORY= "10G"
SPARK_DRIVER_CORE = "5"
SPARK_EXECUTOR_MEMORY= "3G"
SPARK_EXECUTOR_CORE = "1"
conf = SparkConf().\
setAppName("insurance_dataschema").\
setMaster('yarn-client').\
set('spark.executor.cores', SPARK_EXECUTOR_CORE).\
set('spark.executor.memory', SPARK_EXECUTOR_MEMORY).\
set('spark.driver.cores', SPARK_DRIVER_CORE).\
set('spark.driver.memory', SPARK_DRIVER_MEMORY).\
set('spark.driver.maxResultSize', '0').\
set("es.index.auto.create", "true").\
set("es.resource", "tempindex/temptype").\
set("spark.jars", "elasticsearch-hadoop-6.1.1.zip") # set the spark.jars
spark = SparkSession.builder.\
config(conf=conf).\
getOrCreate()
sc=spark.sparkContext
hadoop_conf = sc._jsc.hadoopConfiguration()
hadoop_conf.set("mapreduce.fileoutputcommitter.algorithm.version", "2")
5.2 清洗及写入数据
- 数据加载
#数据加载
df = (spark
.read
.option("header","true")
.option("multiLine", "true")
.csv('EXPORT.csv')
.cache()
)
print(df.count())
#
- 数据清洗,增加一列,或者针对某一列进行udf 转换
'''
#加一列yiyong ,如果是众城数据则为zhongcheng
'''
from pyspark.sql.functions import udf
from pyspark.sql import functions
df = df.withColumn('customer',functions.lit("腾讯用户"))
- 使用udf 清洗时间格式及数字格式
#udf 清洗时间
#清洗日期格式字段
from dateutil import parser
def clean_date(str_date):
try:
if str_date:
d = parser.parse(str_date)
return d.strftime('%Y-%m-%d')
else:
return None
except Exception as e:
return None
func_udf_clean_date = udf(clean_date, StringType())
def is_number(s):
try:
float(s)
return True
except ValueError:
pass
return False
def clean_number(str_number):
try:
if str_number:
if is_number(str_number):
return str_number
else:
None
else:
return None
except Exception as e:
return None
func_udf_clean_number = udf(clean_number, StringType())
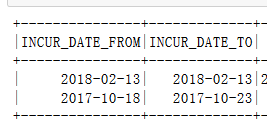
column_Date = [
"DATE_FROM",
"DATE_TO",
]
for column in column_Date:
df=df.withColumn(column, func_udf_clean_date(df[column]))
df.select(column_Date).show(2)
#数据写入
df.write.format("org.elasticsearch.spark.sql").\
option("es.nodes", "IP").\
option("es.port","9002").\
mode("Overwrite").\
save("is/doc")