报表系统优化
背景:
11.22早晨 刚放下背包,收到一份邮件,邮件意思是公司报表数据库慢,让我帮忙看看。邮件还附带了一个SQL文本,指出这个SQL慢。随后电话了开发人员了解事情来龙去脉,原来是在一个月前 DB组帮他们迁移了报表数据库,现在感觉这个新环境比没迁移前还要慢(由于老环境已经回收了,到底慢多少已经无从考证了),老环境15分钟跑完的任务新环境需要1个小时。新环境的硬件资源比老环境高了很多。
环境信息:
DB: oracle 11.2.0.4.0
OS:rhel 6.8
由于库被迁移过,询问实施人员,包括统计信息,执行计划固定都做过,按理说问题不大。
由于现在数据库整体比较慢,而且比老库慢了4倍,所以初步断定是系统级别没设置好导致。
我抓取了业务忙时的报告 发现3个问题:
1、Buffer Hit % = 54.32% db cahce命中率过低;
![]()
db buffercache hit命中率极低,建议调整大一点,可以缓解IO的压力。
2、IO延迟;
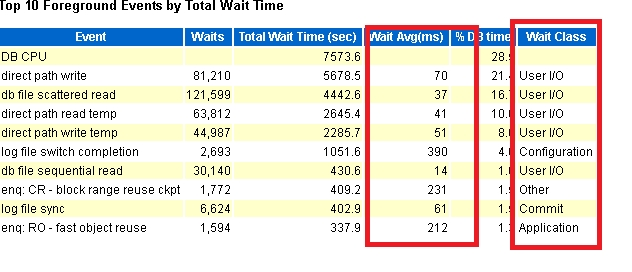
从awr报告可以看出 IOPS为712,显然偏低。
通过iostat 测试,发现系统IO热点太集中,询问系统管理员 得知这个系统使用的是一个低端存储,且存储层面和数据库层面没有做条带化。
- redolog日志切换过于频繁
![]()
Log file switch 切换等待事件,发生这种等待事件要么是系统太忙,要么是日志组过小,要么是手动发起了切换命令。
查看数据库日志文件大小,
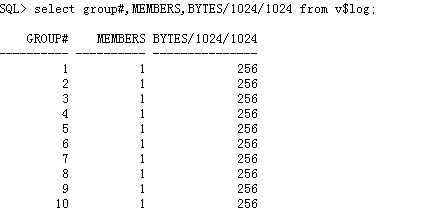
一看吓一跳,一个报表系统的日志组 才256MB?这不是搞笑的嘛!
数据库redolog日志 27MB/s产生 ,现在数据库配置的 redolog 256M,这样计算一个redolog 256/27=9s ,一个redolog 9s被写满。
从查询来看,切换基本上也是9s,切换频率过快,这样会导致IO繁忙,

在同步数据的时候我看他们添加了 append ,建议结合使用 +nologging 插入方式。
总结:
- Buffer hit%命中率太低;
---通过增加dbbuffercache 大小,如果是ASMM管理模式,可以增加SGA大小可以解决。大小可以参考 v$db_cache_advice
- 磁盘IO延迟太严重;
---需要提高存储IO能力或者降低系统IO读写次数(优化SQL,降低物理读 逻辑读,开发不想改SQL)。在系统层面可以通过dd 、iostat 来测试和监控IO指标。
- 增加redolog日志组大小;
----redog log切换推荐15~20分钟一次,按照业务量计算设置为2G合适。
结果:
周六迁移存储到闪存,周一早上跑业务 11分钟执行完成。由一小时到11分钟,主要优化了 redolog 日志组大小,dbbuffercache 大小和更换了存储。
其实还可以进一步优化系统能力,既然领导能接受现状,我就不找事了。