- 文档对象模型(DOM)
- 使用 JavaScript 创建内容
- 使用浏览器事件
- 性能
DOM
我们将深入了解文档对象模型 (DOM) 是什么、如何创建 DOM,以及如何使用 JavaScript 来访问它。
DOM 代表“文档对象模型”,是一种树状结构,是HTML 文档的表示,反映了元素之间的关系,并包含元素的内容和属性。
DOM 不是:
- JavaScript 语言的一部分
DOM 是:
从浏览器构建的- 可以通过
使用 document 对象供 JavaScript 代码全局访问
如何从 HTML 源代码转换为我们在浏览器中看到的内容?

浏览器处理接受数据的规则,整个流程都由令牌解析器来完成,当令牌解析器在执行这一流程时,有另一个流程正在消耗这些令牌(token),并将它们转换为节点(node)对象。例如,我们转换了第一个 html 令牌并创建了 html 节点,然后消耗第二个令牌并创建 head 节点。
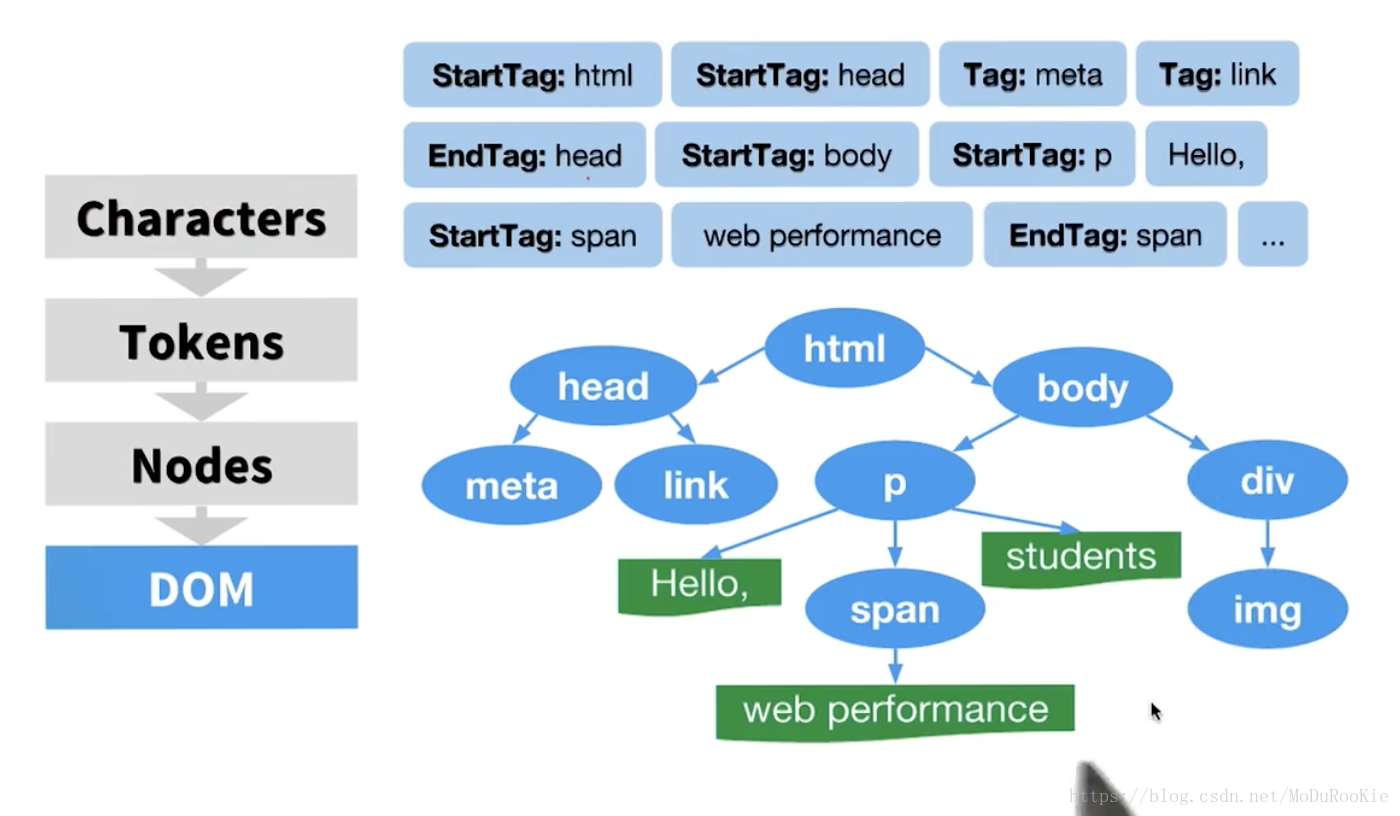
节点之间有关系吗?是的,注意令牌解析器发出了起始令牌和结束令牌,这样就可以显示节点之间的关系。StartTag: head 令牌出现在 EndTag: html 令牌前面,表示 head 令牌是 html 令牌的子级。类似的 meta 和 link 节点是 head 节点的子级,等等,就形成了稳定对象模型(DOM)。

它是一个树结构(tree structure),表示 html 的内容和属性,以及节点之间的关系(子级),注意这些对象包含所有的属性。DOM 是 HTML 标记的完整解析表示。
总结上述整个过程步骤:
- 收到 HTML
- HTML 标签被转换为令牌
- 令牌被转换为节点
- 节点被转换为 DOM
当你请求一个网站时,无论该网站的后端语言是什么,它都会用 HTML 进行响应。浏览器会接收到一连串的 HTML。这些字节通过一个复杂的(但完全记录在案的)解析过程来运行,该过程可以确定不同的字符(例如开始标签字符 <,像 href 这样的属性,像 > 这样的右尖括号)。解析发生后,接下来是一个称为标记化的过程。标记化过程每次使用一个字符来构建令牌。这些令牌包括:
- 文档类型(DOCTYPE)
- 开始标签(StartTag)
- 结束标签(EndTag)
- 注释(Comment)
- 字符(Character)
- 文件结束(End-of-file)
在这个阶段,浏览器已经收到了服务器发送的字节,并将字节转换为标签,然后读取了所有标签,进而创建了一个令牌列表。这个令牌列表将会通过树构建阶段。这个阶段的输出结果是一个树状结构——这就是 DOM!
一个树状结构,反映了 HTML 的内容和属性,以及节点之间的所有关系。
DOM 是 HTML 的完整解析表示。
DOM 是所接收到的 HTML 文档的关系和属性的模型(描述)。请记住,DOM 代表“文档对象模型”,文档的对象模型。可以使用浏览器提供的一个特殊对象来访问 DOM:document,这个对象不是由 JavaScript 语言提供的,但应该已经存在,并且可供 JavaScript 代码自由访问。
DOM 由 W3C 组织进行标准化。有很多组成 DOM 的规范,以下是其中几个:
- 核心规范
- 事件规范
- 样式规范
- 验证规范
- 加载和保存规范
之前我们学习了如何通过 ID(#)、类(.)和标签(如 p)来选择页面元素。接下来,我们将学习如何使用 JavaScript 和 DOM 来访问页面元素!
通过 ID 选择页面元素
document 是一个对象,就像一个 JavaScript 对象一样,这意味着它有键/值对。有些值只是数据片段,而其他值则是可以提供某种功能的函数(也称为方法!)。
document.getElementById('idName');我们需要将一个字符串传递给 .getElementById(),写明我们希望它查找并返回给我们的元素的 ID。了解更多有关此方法
关于这种方法,有几件重要的事情需要记住:
- 它在
document对象上被调用 - 它会返回单个项目
MDN 上的 .getElementById()
通过类或标签选择页面元素
由于 ID 是唯一的,而且在 HTML 中只有一个元素具有该 ID,因此 document.getElementById() 最多只会返回一个元素。那么,我们如何选择多个 DOM 元素呢?
接下来我们将要介绍的两个 DOM 方法都会返回多个元素,它们是:
.getElementsByClassName().getElementsByTagName()
关于这两种方法,有几件重要的事情需要记住:
- 两种方法都使用
document对象 - 二者都会返回多个项目
所返回的列表(html集合)不是数组,特殊的列表,叫做NodeList
通过类来访问元素
我们需要使用一个希望让它搜索/返回的类字符串来调用:
document.getElementsByClassName('brand-color');.getElementById() 与 .getElementsByClassName() 和 .getElementsByTagName() 二者不同的一点,因为这一点很容易被忽视。那就是,.getElementsByClassName() 和 .getElementsByTagName() 的名称中都多了一个“s”。
通过标签来访问元素
document.getElementsByTagName('p');节点、元素和接口
节点接口
| 顺序 | 项目 |
|---|---|
| 首先发生 | 标签(tag) |
| 第二发生 | 令牌(token) |
| 第三发生 | 节点(nodes) |
| 第四发生 | DOM |
DOM 是如何构建的?
- 字符
- 标签
- 令牌
- 节点
- DOM
“节点(Node)”究竟是什么?
Node = Class // N 大写表示类
node = object // n 小写表示对象
Node 就像建筑的蓝图。该蓝图包含建筑数据,我们称之为属性。它具有一系列的建筑功能,我们称之为方法。某些属性可能是建筑颜色、门的数量或者窗户的数量。某些方法可能是保护建筑安全的警报系统或者为草浇水的喷洒系统。假设这个蓝图是很多真实建筑的模型,替代蓝图的另一个术语是接口。接口会告诉我们应用到单个项目的属性和方法。
接口用来表示一系列被继承的属性和方法。
节点(Node)是一个蓝图,包含有关真实节点(nodes)所有属性和方法的信息。
节点接口是每个真实节点创建后的所有属性(数据)和方法(功能)的蓝图。节点接口有很多属性和方法,但它不是很具体。这就好像,“建筑蓝图”没有“房屋蓝图”或“摩天大楼蓝图”那么具体。后者是更具体的蓝图,而这些更具体的蓝图可能会有自己的属性和方法,这些属性和方法只针对房屋或只针对摩天大楼。
元素接口(Element)
正如节点接口一样,元素接口是用于创建元素的蓝图:MDN 上的元素接口
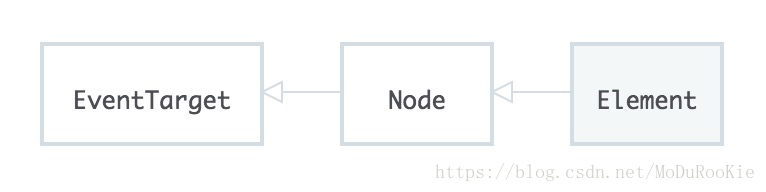
元素指向其父代-节点,即元素接口是节点接口的子代。这也表明元素接口继承了所有节点接口的属性和方法。这意味着,从元素接口创建的任何元素(element,小写“e”!)同时也是节点接口的子代。也就是说,元素(element,小写“e”!)同时也是节点(node,小写“n”!)。
元素接口有自己的 .getElementsByClassName(),它和 document 对象上的同名方法具有完全相同的功能。这意味着,你可以使用 document 对象来选择一个元素,然后你可以对该元素调用 .getElementsByClassName(),从而接收到一系列带有该类名的元素,它们都是该特定元素的子代!
// 选择 ID 为 "sidebar" 的 DOM 元素
const sidebarElement = document.getElementById('sidebar');
// 在 "sidebar" 元素中找寻任何具有 "sub-heading" 类的元素
const subHeadingList = sidebarElement.getElementsByClassName('sub-heading');要查看所有不同的接口,请参见:Web API 接口
更多访问元素方法
几乎 MDN 上的每个方法都有一个浏览器兼容性表格,列出了每个浏览器开始支持该特定方法的时间。值得庆幸的是,所有浏览器基本上都支持官方标准。
但在过去,情况并非如此。你必须编写不同的代码,才能在不同的浏览器中执行相同的操作。而且,你还得编写代码来检查所使用的浏览器类型,才能为该浏览器运行正确的代码。几个 JavaScript 库应运而生,以帮助缓解这些问题。 jQuery库 的主要作用之一是抽象画不同浏览器之间的区别。作为开发者,编写特定的 jQuery 方法,然后 jQuery 会判断运行的是哪个浏览器并针对该浏览器使用正确的代码。因为jQuery 使我们可以非常轻松地编写可在多个浏览器中正确运行的代码。
querySelector 方法
// 找寻并且返回 ID 名为 "header" 的元素
document.querySelector('#header');
// 找寻并且返回第一个 类 名为 "header" 的元素
document.querySelector('.header');
// 找寻并返回第一个 <header> 元素
document.querySelector('header');请查看 MDN 上的 .querySelector() 方法:https://developer.mozilla.org/zh-CN/docs/Web/API/Document/querySelector
注意,我想指出一个潜在的棘手问题,那就是 .querySelector() 方法只会返回一个元素。如果你使用它通过 ID 搜索元素,这是很合理的。但是,尽管 .getElementsByClassName() 和 .getElementsByTagName() 都会返回多个元素的列表,使用 .querySelector() 运行类选择器或标签选择器仍会只返回它所找到的第一个项目。
querySelectorAll 方法
.querySelector() 方法只会返回 DOM 中的一个元素(如果存在的话)。但是,确实有些时候你会想要获取具有特定类的所有元素列表,或某种类型的所有元素(例如所有 <tr> 标签)。我们可以使用 .querySelectorAll() 方法来做到这一点!
// 找寻并返回所有 类 名为 "header" 的元素列表
document.querySelectorAll('.header');
// find and return a list of <header> elements
// 找寻并返回所有 <header> 的元素列表
document.querySelectorAll('header');当获得所有元素列表(NodeList)后,因为它不是数组,我们无法使用数组方法 .map 循环访问列表中的项目。但 NodeList 提供了 forEach 方法和数组方法 forEach 非常相似,但是并非所有浏览器都完全支持 forEach 方法。
如果要循环访问列表中的项目,可以使用 for 循环。首先将返回的所有元素存储在变量中:
const listOfElements = document.querySelectorAll('h2');
for(let I = 0; I < listOfElements.length; I++) {
console.log(listOfElements[I]);
}请参见 MDN 上的 .querySelectorAll() 方法:https://developer.mozilla.org/zh-CN/docs/Web/API/Document/querySelectorAll