1、一行代码实现1--100之和
![]()
2、如何在一个函数内部修改全局变量

3、列出5个python标准库
os:提供了不少与操作系统相关联的函数
sys: 通常用于命令行参数
re: 正则匹配
math: 数学运算
datetime:处理日期时间
4、字典如何删除键和合并两个字典

执行结果

5、谈下python的GIL
python的GIL是python的全局解释器锁,同一个进程中如果有多个线程运行,一个线程运行的时候会霸占解释器,上了个锁即GIL,进程内其他线程无法运行。如果遇到耗时操作,GIL会打开,其他线程先运行,所以多线程仍然是有先后顺序的。
6、python实现列表去重的方法
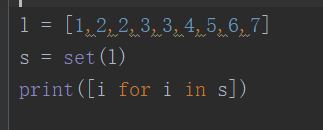
执行结果
![]()
7、fun(*args,**kwargs)中的*args,**kwargs什么意思?
用于函数的接收参数。可以接收补丁数量的参数。
*args是用来接收一个非键值对的可变数量的参数列表
**kwargs允许接收不定长度的键值对。
8、简述with方法打开处理文件帮我我们做了什么?

9、列表[1,2,3,4,5],请使用map()函数输出[1,4,9,16,25],并使用列表推导式提取出大于10的数,最终输出[16,25]

执行结果
![]()
10、python中生成随机整数、随机小数、0--1之间小数方法
随机整数:random.randint(a,b),生成区间内的整数
随机小数:习惯用numpy库,利用np.random.randn(5)生成5个随机小数
0-1随机小数:random.random(),括号中不传参
11、避免转义给字符串加哪个字母表示原始字符串?
r , 表示需要原始字符串,不转义特殊字符
12、<div class="nam">中国</div>,用正则匹配出标签里面的内容(“中国”),其中class的类名是不确定的

13、python中断言方法举例

执行结果

14、数据表student有id,name,score,city字段,其中name中的名字可有重复,需要消除重复行,请写sql语句
select distinct name from student
15、10个Linux常用命令
cd mv cp rm mkdir pwd -V which cat vim grep tree ls
16、列出python中可变数据类型和不可变数据类型,并简述原理
不可变:int,str,tuple 不允许变量的值发生变化,如果改变了值,相当于创建一个新的对象,相同值的对象,内存中的地址是一样的。
可变对象:list,dict 允许变量的值发生变化,例如append操作后,改变的是原对象的值。如果是两个相同值的对象,内存中的地址也是不一样的。
17、s = "ajldjlajfdljfddd",去重并从小到大排序输出"adfjl"

18、用lambda函数实现两个数相乘

17、字典根据键从小到大排序dict={"name":"zs","age":18,"city":"深圳","tel":"1362626627"}

sorted的key参数,表示在排序之前,可以指定一个函数对排序对象先运算,排序依据。i[0]表示字典的键。i[1]表示值
items方法可以获取字典的键值对元组
执行结果

18、利用collections库的Counter方法统计字符串每个单词出现的次数"kjalfj;ldsjafl;hdsllfdhg;lahfbl;hl;ahlf;h"

19、字符串a = "not 404 found 张三 99 深圳",每个词中间是空格,用正则过滤掉英文和数字,最终输出"张三 深圳"

执行结果

20、filter方法求出列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]

21、列表推导式求列表所有奇数并构造新列表,a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]

22、正则re.complie作用
将自己写的正则编译成对象,可重复使用,加快速度。
23、两个列表[1,5,7,9]和[2,2,6,8]合并为[1,2,2,3,6,7,8,9]

24、用python删除文件和用linux命令删除文件方法
python: os.remove("文件名")
linux:rm
25、log日志中,我们需要用时间戳记录error,warning等的发生时间,请用datetime模块打印当前时间戳 “2018-04-01 11:38:54”

星期几也顺便写了
26、数据库优化查询方法
外键,索引、联合查询、选择特定字段
27、请列出你会的任意一种统计图(条形图、折线图等)绘制的开源库,第三方也行
matplotlib
28、写一段自定义异常代码

29、正则表达式匹配中,(.*)和(.*?)匹配区别?
(.*)是贪婪匹配,尽可能多的匹配
(.*?)是尽可能少的匹配结果
30、[[1,2],[3,4],[5,6]]一行代码展开该列表,得出[1,2,3,4,5,6]

tip:列表生成式嵌套循环
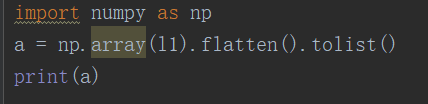
numpy库的flatten方法,- -简单暴力
31、x="abc",y="def",z=["d","e","f"],分别求出x.join(y)和x.join(z)返回的结果

执行结果

相当于 吧y分开,x加入到里面, d abc e abc f
32、举例说明异常模块中try except else finally的相关意义
else 没有捕捉到异常,执行else里面的,
finally 不管有木有异常 都执行finally里面的 参见withopen里面 不论是否成功打开文件,都会执行close()
33、举例说明zip()函数用法
zip()在运算时,能接受一个或多个可迭代对象作为参数,进行一一对应,返回一个元组的列表

执行结果:

34、a="小明 Python 98分",用re.sub,替换为小明 Java 100分

()限定大写字母开头到数字结尾之间的,
.*表示任意个任意字符
35、写5条常用sql语句
show databases;
show tables;
select * from tablename;
desc tablename;
delete from tablename where 字段名=xxx;
select * from tablename order by 字段名 asc(升序)或者desc(降序);
36、a="hello"和b="你好"编码成bytes类型
a = b"hello"
b = "哈哈".encode()
37、[1,2,3]+[4,5,6]的结果是多少?
相当于extend() 合并列表
38、提高python运行效率的方法
1、使用生成器,节约内存
2、优化for循环
3、核心模块用Cpython PyPy等,提高效率
4、多进程,多线程、协程
5、判断可能性大的放到前面
39、简述mysql和redis区别
redis:内存级非关系数据库,速度快,作网页缓存
mysql:关系型数据库 检索有一定io操作,访问速度慢
40、正则匹配,匹配日期2018-03-20

匹配结果

41、list=[7,6,5,4,3,2,1],从小到大排序,不许用sort,输出[1,2,3,4,5,6,7]
冒泡排序

i责设置冒泡次数,
j为列表下标
执行结果

42、写一个单列模式

执行结果

43、列出常见的状态码和意义
200 正常
204 No content 请求成功,无内容返回
206 GET范围请求已成功处理
301 重定向
400 参数错误
401 http认证失败
403 权限拒绝了
404 无url对应资源
500 服务器错误
44、列出常见MYSQL数据存储引擎
InnoDB:支持事务处理,支持外键,支持崩溃修复能力和并发控制。如果需要对事务的完整性要求比较高(比如银行),要求实现并发控制(比如售票),那选择InnoDB有很大的优势。如果需要频繁的更新、删除操作的数据库,也可以选择InnoDB,因为支持事务的提交(commit)和回滚(rollback)。
MyISAM:插入数据快,空间和内存使用比较低。如果表主要是用于插入新记录和读出记录,那么选择MyISAM能实现处理高效率。如果应用的完整性、并发性要求比 较低,也可以使用。
45、简述同源策略
同源策略需要同时满足以下三点要求:
1)协议相同
2)域名相同
3)端口相同
http:www.test.com与https:www.test.com 不同源——协议不同
http:www.test.com与http:www.admin.com 不同源——域名不同
http:www.test.com与http:www.test.com:8081 不同源——端口不同
只要不满足其中任意一个要求,就不符合同源策略,就会出现“跨域”
46、简述cookie和session的区别
1,session 在服务器端,cookie 在客户端(浏览器)
2、session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,同时 session 也会失效,存储Session时,键与Cookie中的sessionid相同,值是开发人员设置的键值对信息,进行了base64编码,过期时间由开发人员设置
3、cookie安全性比session差
47、简述多线程、多进程
进程:
1、操作系统资源分配的基本单位,进程之间相互独立
2、稳定性好,但是资源消耗大。
线程:
1、cpu进行资源分配和调度的基本单位,线程是进程再次细分,是比进程更小的独立运行的基本单位,一个进程下所有线程共享该进程资源,
2、IO操作密集,多线程运行效率高,但是如果其中一个崩溃,进程也会崩溃。
应用:
IO密集型用多线程,等待时候可以切换带其他线程运行
CPU密集的用多进程,IO操作少,因为线程多霸占GIL,其他线程不能运行,不能充分发挥多核CPU优势。
48、IOError、AttributeError、ImportError、IndentationError、IndexError、KeyError、SyntaxError、NameError分别代表什么异常
IOError:输入输出异常
AttributeError:试图访问一个对象没有的属性
ImportError:无法引入模块或包,基本是路径问题
IndentationError:语法错误,代码没有正确的对齐
IndexError:下标索引超出序列边界
KeyError:试图访问你字典里不存在的键
SyntaxError:Python代码逻辑语法出错,不能执行
NameError:使用一个还未赋予对象的变量
49、python中copy和deepcopy区别
复制不可变对象(数值,str,tuple)时候没区别
复制可变对象(list,dict)时候,copy复制的是指针,deepcopy复制的是对象。
50、列出几种魔法方法并简要介绍用途
__init__:对象初始化方法
__new__:创建对象时候执行的方法,单列模式会用到
__str__:当使用print输出对象的时候,只要自己定义了__str__(self)方法,那么就会打印从在这个方法中return的数据
__del__:删除对象执行的方法
51、C:\Users\ry-wu.junya\Desktop>python 1.py 22 33命令行启动程序并传参,print(sys.argv)会输出什么数据?

52、请将[i for i in range(3)]改成生成器

执行结果

53、举例sort和sorted对列表排序,list=[0,-1,3,-10,5,9]
sort是在list基础上进行修改,无返回值
sorted返回的是是新的list
54、对list排序foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4],使用lambda函数从小到大排序

执行结果

55、使用lambda函数对list排序foo = [-5,8,0,4,9,-4,-20,-2,8,2,-4],输出结果为
[0,2,4,8,8,9,-2,-4,-4,-5,-20],正数从小到大,负数从大到小
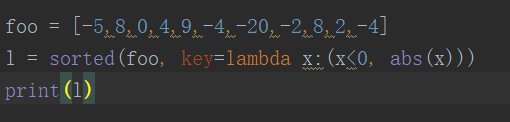
执行结果

56、列表嵌套字典的排序,分别根据年龄和姓名排序

执行结果

57、列表嵌套元组,分别按字母和数字排序
与上类似
58、列表嵌套列表排序,年龄数字相同怎么办?

59、根据键对字典排序(方法一,zip函数)

执行结果
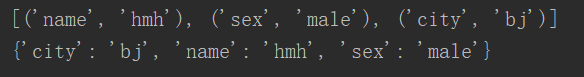
60、根据键对字典排序(方法二,不用zip)

61、列表推导式、字典推导式、生成器

62、最后出一道检验题目,根据字符串长度排序,看排序是否灵活运用

63、举例说明SQL注入和解决办法


64、正则匹配以163.com结尾的邮箱

65、s="info:xiaoZhang 33 shandong",用正则切分字符串输出['info', 'xiaoZhang', '33', 'shandong']

66、递归求和1-10
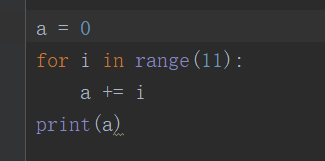
67、python字典和json字符串相互转化方法
json包里的dumps用来转成字符串
loads用来转成字典
68、MyISAM 与 InnoDB 区别:
1、InnoDB 支持事务,MyISAM 不支持,这一点是非常之重要。事务是一种高
级的处理方式,如在一些列增删改中只要哪个出错还可以回滚还原,而 MyISAM
就不可以了;
2、MyISAM 适合查询以及插入为主的应用,InnoDB 适合频繁修改以及涉及到
安全性较高的应用;
3、InnoDB 支持外键,MyISAM 不支持;
4、对于自增长的字段,InnoDB 中必须包含只有该字段的索引,但是在 MyISAM
表中可以和其他字段一起建立联合索引;
5、清空整个表时,InnoDB 是一行一行的删除,效率非常慢。MyISAM 则会重
建表;
69、正则匹配不是以4和7结尾的手机号

70、简述python引用计数机制
python垃圾回收主要以引用计数为主,标记-清除和分代清除为辅的机制,其中标记-清除和分代回收主要是为了处理循环引用的难题。
引用计数算法
只有当引用计数为0的时候,对象才会被真的删除

71、正则表达式匹配第一个URL

72、正则匹配中文

73、简述乐观锁和悲观锁
悲观锁, 就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
乐观锁,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制,乐观锁适用于多读的应用类型,这样可以提高吞吐量
74、Linux命令重定向 > 和 >>
Linux 允许将命令执行结果 重定向到一个 文件
将本应显示在终端上的内容 输出/追加 到指定文件中
> 表示输出,会覆盖文件原有的内容
>> 表示追加,会将内容追加到已有文件的末尾
用法示例:
将 echo 输出的信息保存到 1.txt 里echo Hello Python > 1.txt
将 tree 输出的信息追加到 1.txt 文件的末尾tree >> 1.txt75、正则表达式匹配出<html><h1>www.itcast.cn</h1></html>

76、python传参数是传值还是传址?
传的是指针,是引用传递
对于不可变类型(数值,str,tuple),不会改变原来变量
对于可变数据类型(list dict),会修改对应变量。
77、生成0-100的随机数

78、lambda匿名函数好处
精简代码,lambda省去了定义函数,map省去了写for循环过程

79、python正则中search和match
