如果您是InfluxData社区的成员,那么您可能希望在某些时候跨测量执行数学运算。你做了一些谷歌搜索并偶然发现了这个GitHub问题3552并且流下了一滴小小的泪水。好吧,今天我成了好消息的承载者。InfluxData发布了Flux的技术预览,Flux是一种新的查询语言和时间序列数据引擎,它具有跨测量执行数学运算的能力。
在本文中,我将分享两个如何跨测量执行数学运算的示例:
- 如何计算每个请求写入数据库的行的批量大小。以下示例是探索测量数学的最快方法。您可以简单地启动并运行沙箱,然后复制并粘贴代码以自行尝试。
- 如何“监控”热交换器的效率随着时间的推移。您可以找到此部件的数据集和Flux查询位于此仓库中。
如何计算每个请求写入数据库的行的批量大小
克隆沙箱并运行后./sandbox up,您将使整个TICK堆栈以容器化方式运行。“telegraf”数据库包含从本地计算机收集的多个指标。要计算要收集和写入InfluxDB的度量的批量大小,我们需要找到随时间写入数据库的行数,并将该值除以同一时间段内的写入请求数。
首先,过滤数据以隔离所写的写请求数和写入的行数。将该数据分别存储在两个表中,“httpd”和“write”。
httpd = from(bucket:"telegraf/autogen") |> range(start: dashboardTime) |> filter(fn:(r) => r._measurement == "influxdb_httpd" and r._field == "writeReq")
write = from(bucket:"telegraf/autogen") |> range(start: dashboardTime) |> filter(fn:(r) => r._measurement == "influxdb_write" and r._field == "pointReq")
接下来,加入两个表。在加入默认为左连接。最后,我们使用Map函数划分这两个值,并计算仪表板时间(-5m)的平均批量大小。
avg_batch_size = join(tables:{httpd:httpd, write:write}, on:["_time"]) |> map(fn:(r) => ({ _value: r._value_write / r._value_httpd})) |> mean()
旁注:虽然这个查询很简单,但效率很低。它仅用于演示目的。如果要查看较长时间范围内的平均批量大小,可能需要1)窗口httpd表和写表,2)分别计算平均值和最大值。做这样的事情将允许您在跨测量执行数学之前聚合数据,这将更快,更有效。
如何“监测”热交换器的效率随着时间的推移
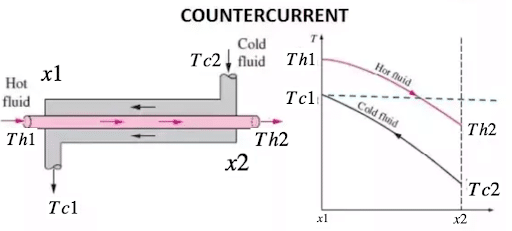
在这个例子中,我决定想象我是化工厂的操作员,我需要监控逆流热交换器的温度。我从四个不同的温度传感器收集冷(TC)和热(TH)流的温度。有两个入口(Tc2,Th1)传感器和两个出口(Tc1,Th2)传感器在位置x1和x2分别。
做了一些假设后,我可以用这个公式计算传热效率:
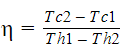
我在两个不同的时间从每个传感器收集温度读数,总共8个点。此数据集很小,仅用于演示目的。我的数据库结构如下:
| 数据库 | 测量 | 标签键 | 标记值 | 字段键 | 字段值 | 时间戳 |
| 传感器 | Tc1,Tc2,Th1,Th2 | 位置 | x1,x2 | 温度 | 总共8个 | t1,t2 |
由于温度读数存储在不同的测量中,我再次应用Join和Map来计算效率。我在Chronograf中使用Flux编辑器和Table视图来显示所有结果。
首先,我想收集每个传感器的温度读数。我从Th1开始。我需要准备数据。我删除了“_start”和“_stop”列,因为我没有执行任何组或窗口。我可以删除“_measurement”和“_field”,因为它们对我的所有数据都是相同的。最后,我对基于“位置”的任何分析不感兴趣,所以我也可以放弃它。我将只对相同时间戳的值执行数学运算,因此我保留“_time”列。
Th1 = from(bucket: "sensors") |> range(start: dashboardTime) |> filter(fn: (r) => r._measurement == "Th1" and r._field == "temperature") |> drop(columns:["_start", "_stop", "_measurement", "position", “_field”])
现在我可以应用相同的查询Th2。
Th2 = from(bucket: "sensors") |> range(start: dashboardTime) |> filter(fn: (r) => r._measurement == "Th2" and r._field == "temperature") |> drop(columns:["_start", "_stop", "_measurement", "position", “_field”])
接下来,我加入了两个表。
TH = join(tables: {Th1: Th1, Th2: Th2}, on: ["_time"])
Join默认为左连接。tables:{Th1: Th1, Th2: Th2}允许您指定后缀的命名(相当于Pandas中的“rsuffix / lsuffix”或SQL中的“table.id”语法)。
我也将这个逻辑应用于冷流:
TC = join(tables: {Tc1: Tc1, Tc2: Tc2}, on: ["_time"])
接下来,我和TH一起加入TC。

join(tables: {TC: TC, TH: TH}, on: ["_time"])
最后,我可以使用Map来计算所有测量的效率。这就是代码一起看起来的样子:
Th1 = from(bucket: "sensors") |> range(start: dashboardTime) |> filter(fn: (r) => r._measurement == "Th1" and r._field == "temperature") |> drop(columns:["_start", "_stop", "_measurement", "position", “_field”]) Th2 = from(bucket: "sensors") |> range(start: dashboardTime) |> filter(fn: (r) => r._measurement == "Th2" and r. _field == "temperature") |> drop(columns:["_start", "_stop", "_measurement", "position", “_field”]) TH = join(tables: {Th1: Th1, Th2: Th2}, on: ["_time"]) Tc1 = from(bucket: "sensors") |> range(start: dashboardTime) |> filter(fn: (r) => r._measurement == "Tc1" and r._field == "temperature") |> drop(columns:["_start", "_stop", "_measurement", "position", “_field”]) Tc2 = from(bucket: "sensors") |> range(start: dashboardTime) |> filter(fn: (r) => r._measurement == "Tc2" and r._field == "temperature") |> drop(columns:["_start", "_stop", "_measurement", "position", “_field”]) TCTH = join(tables: {Tc1: Tc1, Tc2: Tc2}, on: ["_time"]]) join(tables: {TC: TC, TH: TH}, on: ["_time"]) |> map(fn: (r) => (r._value_Tc2 - r._value_Tc1)/(r._value_Th1 - r._value_Th2)) |> yield(name: "efficiency")
我可以看到传热效率随着时间的推移而降低。这是一个非常简单的Flux功能的例子,但它让我的想象力疯狂。我是否可以构建一个类似于仅使用OSS的DeltaV报警管理解决方案的监控和警报工具?可能不是,但我可以梦想有人可能。
如果您像我一样并且发现情境化和比较有用,我建议您阅读我即将进行的用户体验评论。在该评论中,我将Flux Joins与Pandas Joins进行了比较。Flux有一些特点。对我来说最明显的是|>管道前进。起初,我不喜欢它。我几乎从不使用烟斗和我的小拇指想到必须学习新的中风。现在,我发现它们大大提高了可读性。每个管道前进都返回一个结果。阅读Flux查询感觉就像阅读要点。