首先采用kesci的第三套练习作为groupby的初步用法介绍,后面有什么收获或者心得再补充。
原文链接:
kesci数据分析练习题
导入库和数据:
import pandas as pd
drinks = pd.read_csv('/drinks.csv')
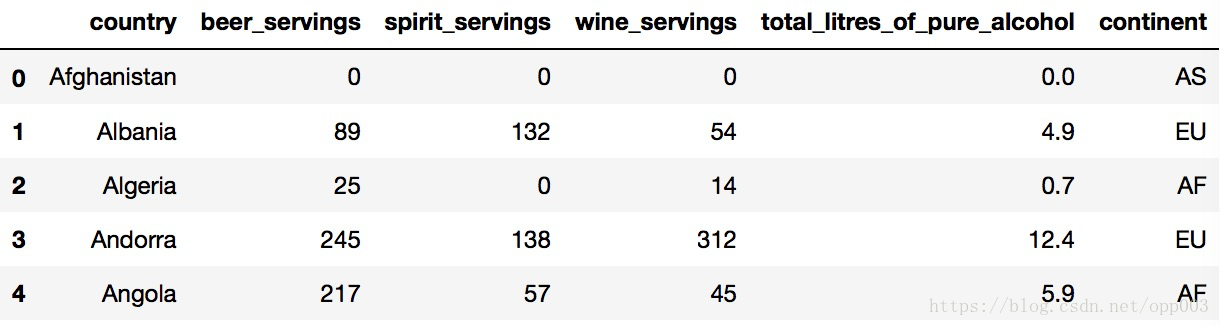
用head方法查看下导入的数据,如下图
1.查看平均消耗的啤酒(beer)最多的大陆(continent):
drinks.groupby('continent').beer_servings.mean()
输出:
continent
AF 61.471698
AS 37.045455
EU 193.777778
OC 89.687500
SA 175.083333
Name: beer_servings, dtype: float64
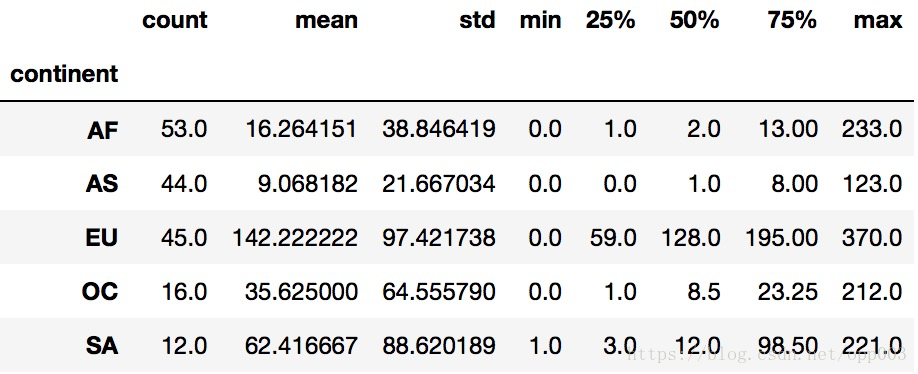
2.打印出每个大陆(continent)的红酒消耗(wine_servings)的描述性统计值
drinks.groupby('continent').wine_servings.describe()
输出如图:
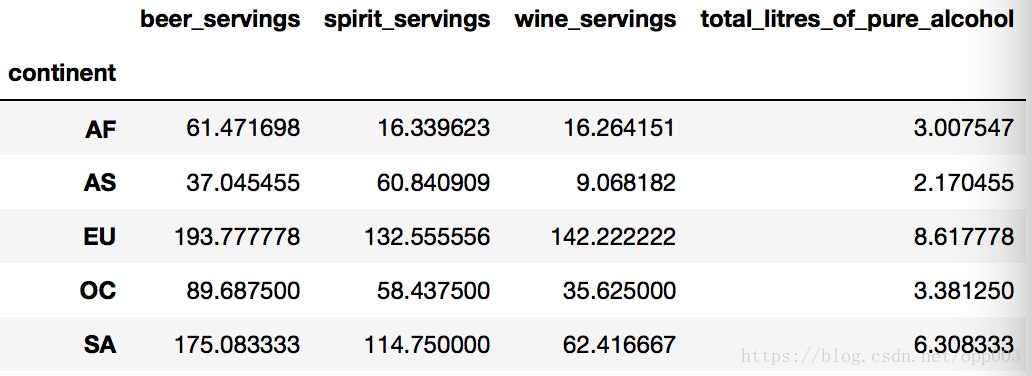
3.打印出每个大陆每种酒类别的消耗平均值
drinks.groupby('continent').mean()
输出如图:
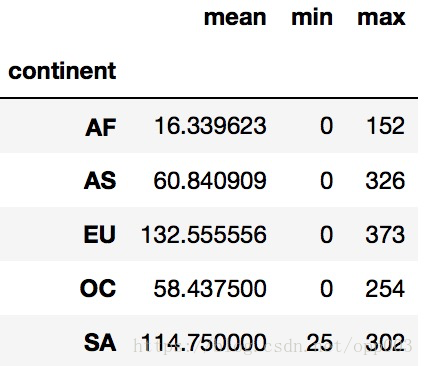
4.打印出每个大陆对spirit饮品消耗的平均值,最大值和最小值
drinks.groupby('continent').spirit_servings.agg(['mean', 'min', 'max'])
输出如图: