在python中,urllib是请求url连接的标准库,在python2中,分别有urllib和urllib,在python3中,整合成了一个,称谓urllib
urllib.request
request主要负责构建和发起网络请求
1)GET请求(不带参数)
response = urllib.request.urlopen(url,data=None, [timeout, ]*)
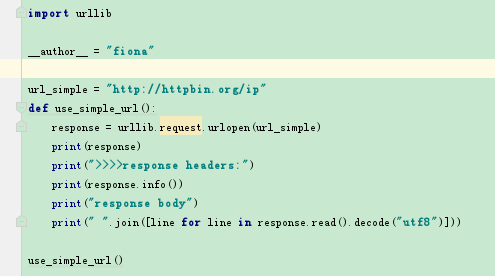
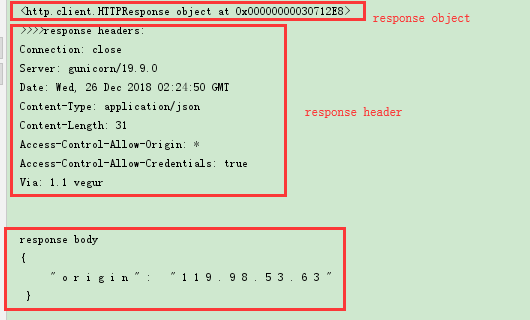
返回的response是一个http.client.HTTPResponse object
response操作:
a) response.info() 可以查看响应对象的头信息,返回的是http.client.HTTPMessage object
b) getheaders() 也可以返回一个list列表头信息
c) response可以通过read(), readline(), readlines()读取,但是获得的数据是二进制的所以还需要decode将其转化为字符串格式。
d) getCode() 查看请求状态码

e) geturl() 获得请求的url
>>>>>>>
2)GET请求(带参数)
需要用到urllib下面的parse模块的urlencode方法
param = {"param1":"hello", "param2":"world"}
param = urllib.parse.urlencode(param) # 得到的结果为:param2=world¶m1=hello
url = "?".join([url, param]) # http://httpbin.org/ip?param1=hello¶m2=world
response = urllib.request.urlopen(url)
3)POST请求:
urllib.request.urlopen()默认是get请求,但是当data参数不为空时,则会发起post请求
传递的data需要是bytes格式
设置timeout参数,如果请求超出我们设置的timeout时间,会跑出timeout error 异常。
param = {"param1":"hello", "param2":"world"}
param = urllib.parse.urlencode(param).encode("utf8") # 参数必须要是bytes
response = urllib.request.urlopen(url, data=param, timeout=10)
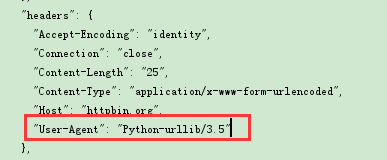
4)添加headers
通过urllib发起的请求,会有一个默认的header:Python-urllib/version,指明请求是由urllib发出的,所以遇到一些验证user-agent的网站时,我们需要伪造我们的headers
伪造headers,需要用到urllib.request.Request对象
headers = {"user-agent:"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
req = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(req)


对于爬虫来说,如果一直使用同一个ip同一个user-agent去爬一个网站的话,可能会被禁用,所以我们还可以用用户代理池,循环使用不同的user-agent
原理:将各个浏览器的user-agent做成一个列表,然后每次爬取的时候,随机选择一个代理去访问
uapool = ["谷歌代理", 'IE代理', '火狐代理',...]
curua = random.choice(uapool)
headers = {"user-agent": curua}
req = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(req)
5)添加cookie
为了在请求的时候,带上cookie信息,需要构造一个opener
需要用到http下面的cookiejar模块
from http import cookiejar
from urllib import request
a) 创建一个cookiejar对象
cookie = cookiejar.CookieJar()
b) 使用HTTPCookieProcessor创建cookie处理器
cookies = request.HTTPCookieProcessor(cookie)
c) 以cookies处理器为参数创建opener对象
opener = request.build_opener(cookies)
d) 使用这个opener来发起请求
resp = opener.open(url)
e) 使用opener还可以将其设置成全局的,则再使用urllib.request.urlopen发起的请求,都会带上这个cookie
request.build_opener(opener)
request.urlopen(url)
6)IP代理
使用爬虫来爬取数据的时候,常常需要隐藏我们真实的ip地址,这时候需要使用代理来完成
IP代理可以使用西刺(免费的,但是很多无效),大象代理(收费)等
代理池的构建可以写固定ip地址,也可以使用url接口获取ip地址
固定ip:
from urllib import request
import random
ippools = ["36.80.114.127:8080","122.114.122.212:9999","186.226.178.32:53281"]
def ip(ippools):
cur_ip = random.choice(ippools)
# 创建代理处理程序对象
proxy = request.ProxyHandler({"http":cur_ip})
# 构建代理
opener = request.build_opener(proxy, request.HttpHandler)
# 全局安装
request.install_opener(opener)
for i in range(5):
try:
ip(ippools)
cur_url = "http://www.baidu.com"
resp = request.urlopen(cur_url).read().decode("utf8")
excep Exception as e:
print(e)
使用接口构建IP代理池(这里是以大象代理为例)
def api():
all=urllib.request.urlopen("http://tvp.daxiangdaili.com/ip/?tid=订单号&num=获取数量&foreign=only")
ippools = []
for item in all:
ippools.append(item.decode("utf8"))
return ippools
其他的和上面使用方式类似
7)爬取数据并保存到本地 urllib.request.urlretrieve()
如我们经常会需要爬取一些文件或者图片或者音频等,保存到本地
urllib.request.urlretrieve(url, filename)
8)urllib的parse模块
前面第2)中,我们用到了urllib.parse.urlencode()来编码我们的url
a)urllib.parse.quote()
这个多用于特殊字符的编码,如我们url中需要按关键字进行查询,传递keyword='诗经'
url是只能包含ASCII字符的,特殊字符及中文等都需要先编码在请求
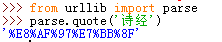
要解码的话,使用unquote
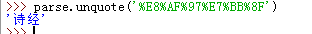
b)urllib.parse.urlencode()
这个通常用于多个参数时,帮我们将参数拼接起来并编译,向上面我们使用的一样

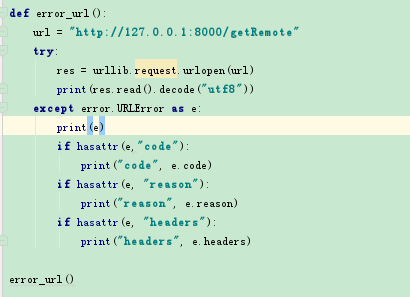
9)urllib.error
urllib中主要两个异常,HTTPError,URLError,HTTPError是URLError的子类
HTTPError包括三个属性:
code:请求状态码
reason:错误原因
headers:请求报头