1.1 语言计算:文本和词汇
入门
nltk下载地址 使用pip安装
>>>import nltk 检验是否成功。
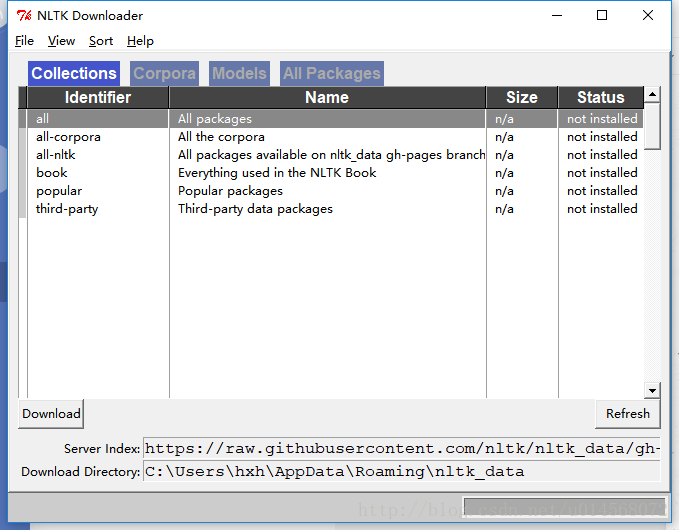
>>>nltk.download() 选择语料下载
使用python解释器加载book模块中的条目
>>>from nltk.book import *

输入名字如 >>>text1 即可找到相应的文本
搜索文本
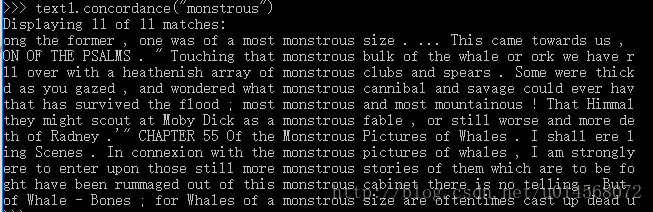
搜索文本中的某个词 >>>text1.concordance("monstrous")
搜索文本中与指定词相似的词 >>>text1.similar("monstrous")

研究同一文本中的两个及以上的词之间的关系 >>>text2.common_contexts(["monstrous","very"])
(可以用来考察两次的用法是否相似)
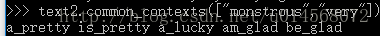
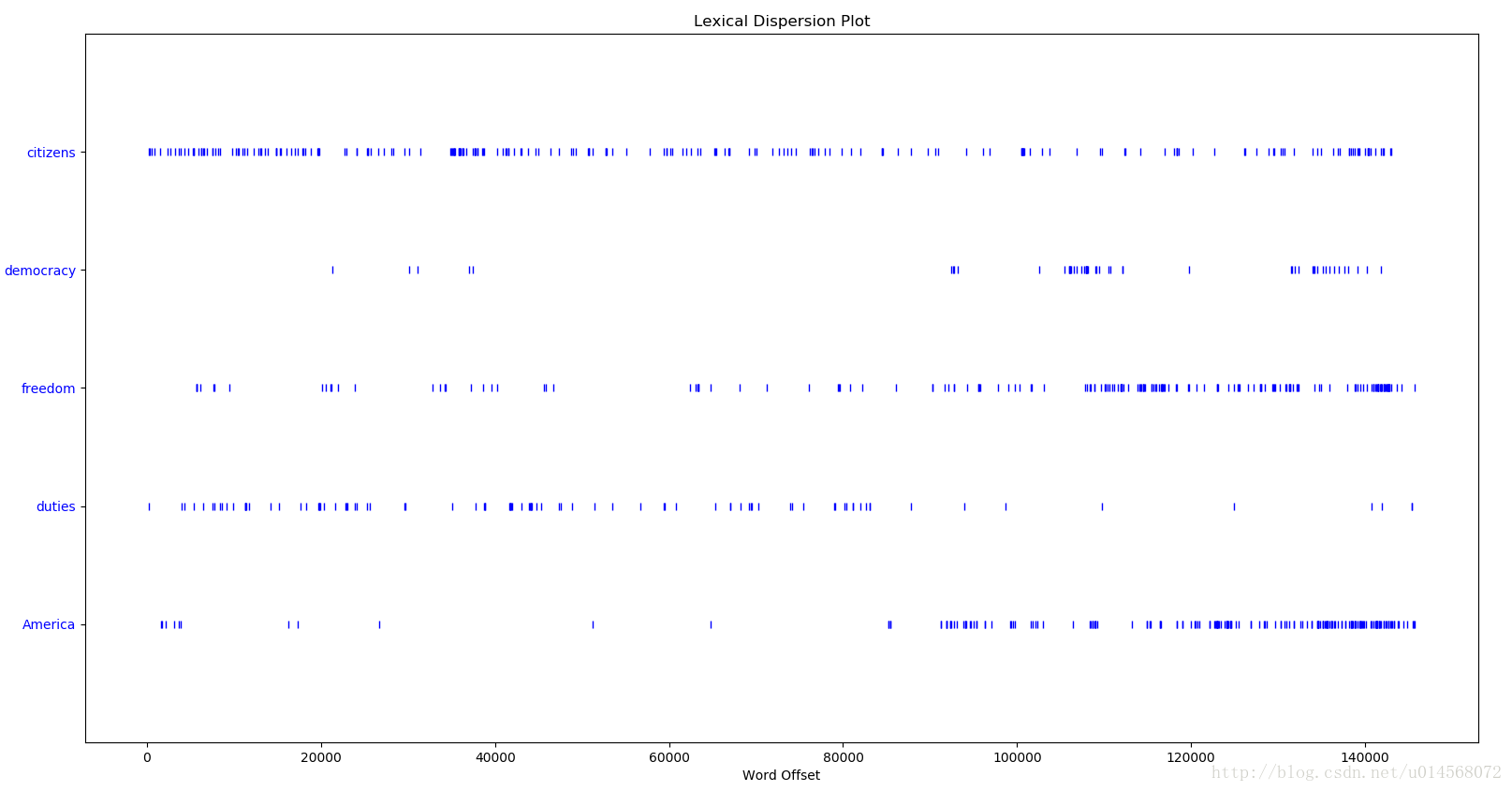
根据几个词在文本中出现位置的离散图观察单词分布
>>>text4.dispersion_plot(["citizens","democracy","freedom","duties","America"])
生成文本 >>>text3.generate()(书中nltk2.0.1版本可用,但是新版本不再支持)

计数词汇
使用len函数获取文本长度(包括单词及标点) >>>len(text3)
获取无重复的词汇表 >>>sorted(set(text3))
计算文本词汇丰富度
>>>from __feature__ import division
>>>len(text3) / len(set(text3))特定单词计数 >>>text3.count("smote")
1.2 近观Python:将文本当做词链表
主要介绍Python中链表的相关操作。(略)
1.3 计算语言:简单的统计
频率分布
统计文本中词的词频,降序排列保存至map中
>>>fdist1 = FreqDist(text1)
>>>vocabulary1 = fdist1.keys()
>>>vocabulary1[:50]
Top50词频可视化 >>>fdist1.plot(50,cumulative=True)
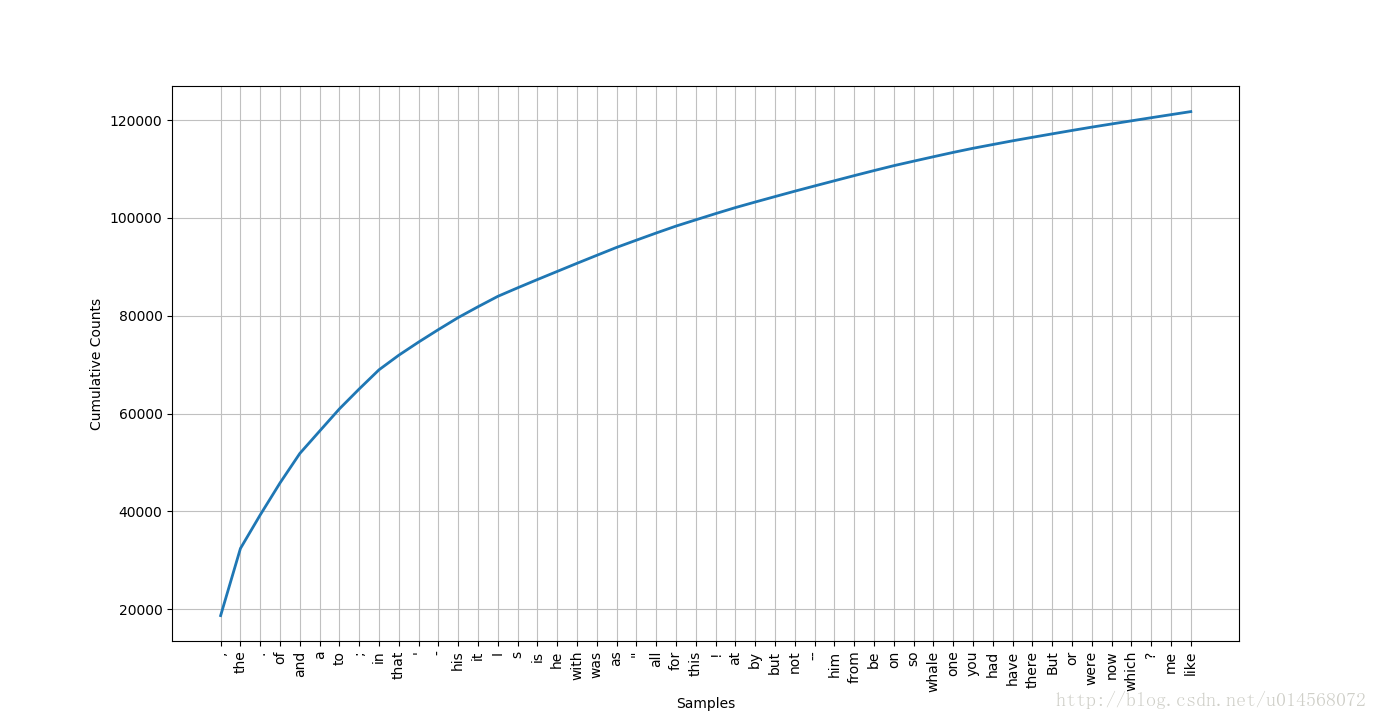
查看文本中只出现一次的词 >>>fdist1.hapaxes()
细粒度选择词
找出文本中长度超过15的词 :
>>>V = set(text1)
>>>long_words = [w for w in V if len(w) > 15]
>>>sorted(long_words)
词语搭配和双连词
提取文本词汇中的词对
>>>list(bigrams(['more', 'is', 'said', 'than', 'done']))
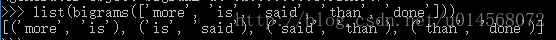
collocations() 函数在已知单个词的词频基础上,找到出现频繁的双连词
>>text4.collocations()

计算其他东西
查看文本中词长的分布
>>>fdist = FreqDist([len(w) for w in text1])
>>>fdist.keys()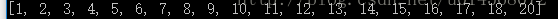
输出结果表明text1中最长的词是由20个字符组成。
>>>fdist.items()
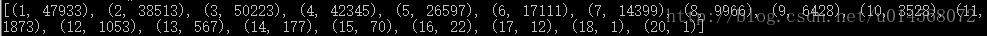
>>>fdist.max()
>>>fdist.freq(3)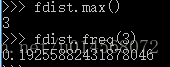
由结果可知,文本中长度为3的词最频繁,约占20%。
| Examples | Descriptions |
|---|---|
fdist = FreqDist(samples) |
创建包含给定样本的频率分布 |
fdist.inc(samples) |
增加样本 |
fdist['monstrous'] |
计数给定样本出现的次数 |
fdist.freq('monstrous') |
给定样本的频率 |
fdist.N() |
样本总数 |
fdist.keys() |
以频率递减顺序排序的样本链接 |
for sample in fdist: |
以频率递减的顺序遍历样本 |
fdist.max() |
数值最大的样本 |
fdist.tabulate() |
绘制频率分布表 |
fdist.plot() |
绘制频率分布图 |
fdist.plot(cumulative=True) |
绘制累积频率分布图 |
fdist1<fdist2 |
测试样本在fdist1中出现的频率是否小于fdist2 |
1.4 回到Python:决策与控制
主要介绍for循环与条件语句(略)
1.5 自动理解自然语言
词义消岐
指代消解 anaphora resolution
自动生成语言

遗憾地发现在nltk3.2里,书中的babelize_shell()这个服务也不再提供了。
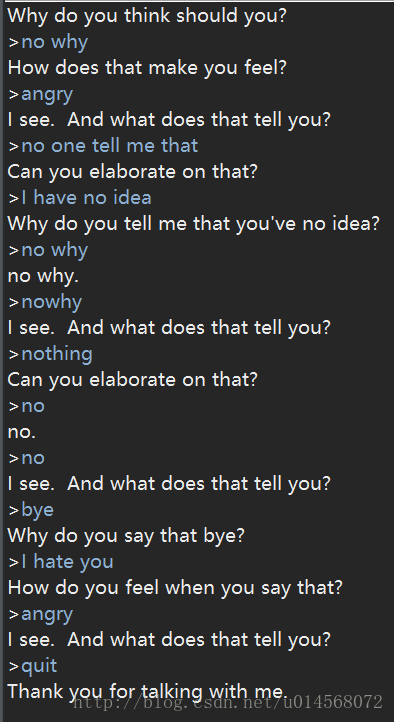
人机对话系统
>>>import nltk
>>>nltk.chat.chatbots()