nltk安装踩坑记录,折腾了好久,pip install nltk这步成功,from nltk.book import * 这步失败了,输入nltk.download()出现下框。
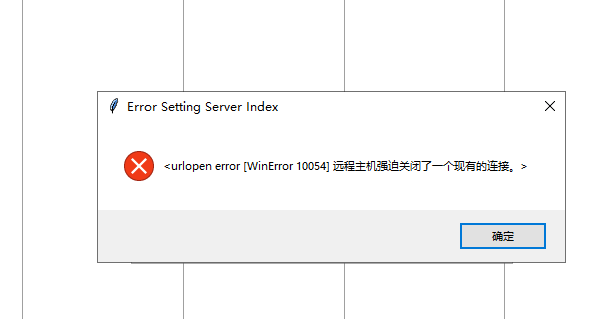
点击确定后,将Download Directory记下来,每台电脑的路径可能会不同。下图是我的路径地址
网上搜索资料,要从https://github.com/nltk/nltk_data下载nltk_data,这里只有package这个包有用,解压然后将文件放入上面这个路径中
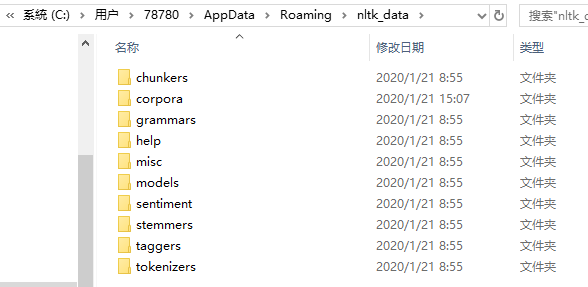
重点来了,这时还需要将corpora文件夹中的zip文件全部解压到当前目录才能用!!全部解压之后在cmd中输入from nltk.book import *成功

安装成功后,可以开始真正的学习笔记了
搜索文本
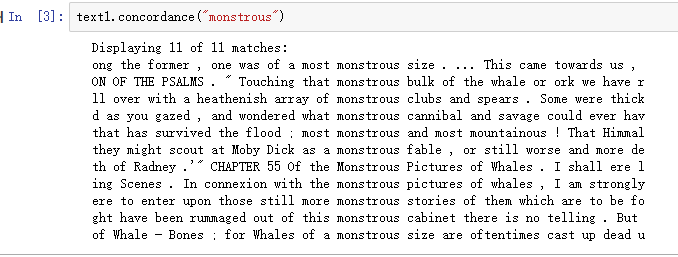
text1.concordance("monstrous"),可以查看Moby Dick《白鲸记》中的词monstrous:
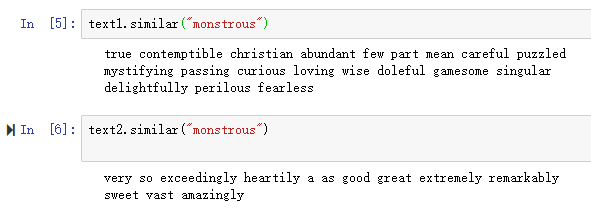
通过similar函数可以看出还有哪些词出现在相似的上下文中。
函数common_contexts允许我们研究两个或两个以上的词共同的上下文,如monstrous和very。我们必须用方括号和圆括号把这些词括起来,中间用逗号分割:

text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"]) 可以绘制美国总统就职演说词汇分布图:可以用来研究随时间推移语言使用上的变化。

词汇计数
因为在集合中所有重复的元素都只算一个。Python中我们可以使用命令:set(text3)获得text3的词汇表。

sorted()包裹起Python表达式set(text3),得到一个词汇项的排序表,这个表以各种标点符号开始,然后是以A开头的词汇。大写单词排在小写单词前面。通过求集合中元素的个数间接获得词汇表的大小,使用len来获得的这个数值。通过len(text3)获得的长度是包括重复字符的长度。
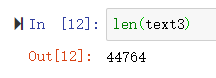
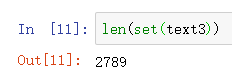
上图代表小说中只有2789个不同的单词或词类型。
现在,让我们对文本词汇丰富度进行测量。下面这图示例,不同的单词数目占据全文单词总数的6%,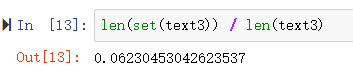
接下来,让我们专注于特定的词。我们可以计数一个词在文本中出现的次数,计算一个特定的词在文本中占据的百分比:

代表text3中,smote出现了5次,text4中 'a' 占据了text4中1.4643%
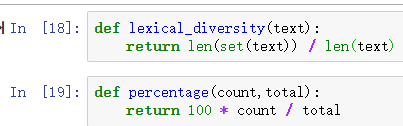
构造两个函数分别用来计算一个不同的单词数目占据全文单词总数的百分比和特定的词在文本中占据的百分比
频率分布
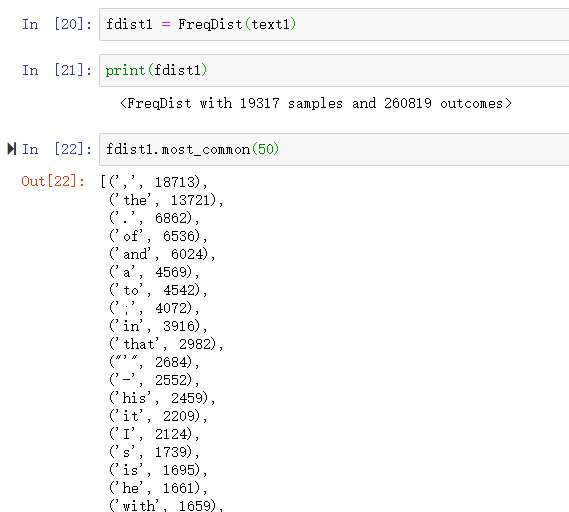
FreqDist可以寻找文本中最常见的词
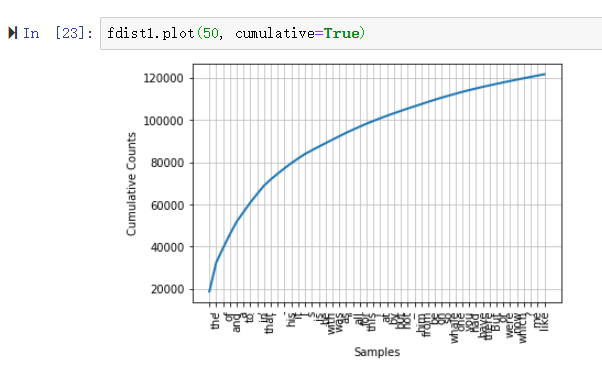
绘制词汇的累积频率图
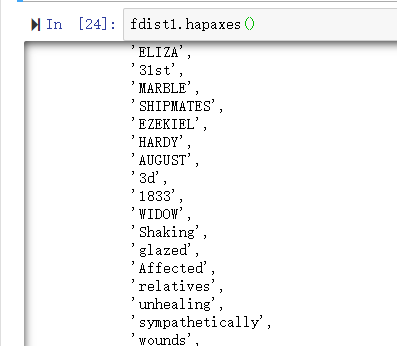
hapaxes()查看低频词
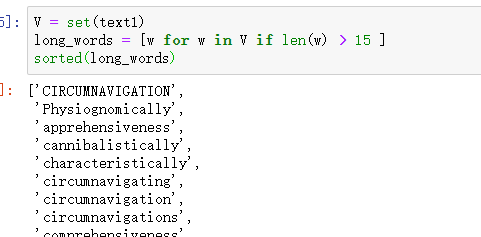
细粒度的选择词
找出文本词汇表长度中超过15个字符的词。
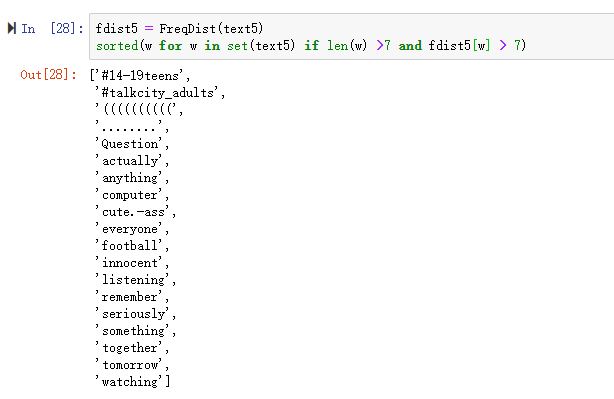
若对text5使用上述代码将会出现以下情况
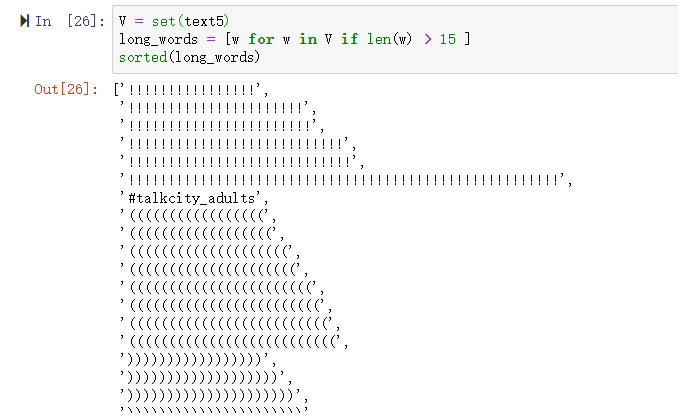
发现这时的结果并没有什么实际意义,于是我们想到也许找出频繁出现的长词会更好。这样看起来更有前途,因为这样忽略了短高频词和长低频词。len(w) > 7 保证词长都超过七个字母,fdist5[w] > 7 保证这些词出现超过7 次。
词语搭配和双连词
bigrams() 获取双连词

找到比我们基于单个词的频率预期得到的更频繁出现的双连词。collocations() 函数为我们做这些。

3.4 计数其他东西
可以查看文本中词长的分布,通过创造一长串数字的列表的FreqDist,其中每个数字是文本中对应词的长度:

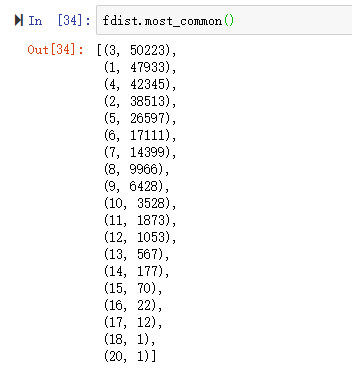
most_common()显示出长度为3的词语出现了50223次,长度为1的词语出现了47933次等等
最频繁的词长度是3,长度为3的词有50223个。关于词长的进一步分析可能帮助我们了解作者、文本或语言之间的差异。