版权声明:本文为博主原创文章,转载或者引用请务必注明作者和出处,尊重原创,谢谢合作 https://blog.csdn.net/u012328159/article/details/51462942
异常检测(anomaly detection)
关于异常检测(anomaly detection)本文主要介绍一下几个方面:
- 异常检测定义及应用领域
- 常见的异常检测算法
- 高斯分布(正态分布)
- 异常检测算法
- 评估异常检测算法
- 异常检测VS监督学习
- 如何设计选择features
- 多元高斯分布
- 多元高斯分布在异常检测上的应用
一、异常检测定义及应用领域
先来看什么是异常检测?所谓异常检测就是发现与大部分对象不同的对象,其实就是发现离群点。异常检测有时也称偏差检测。异常对象是相对罕见的。下面来举一些常见的异常检测的应用:
- 欺诈检测:主要通过检测异常行为来检测是否为盗刷他人信用卡。
- 入侵检测:检测入侵计算机系统的行为
- 医疗领域:检测人的健康是否异常
二、常见的异常检测算法
有许多的异常检测算法,不过本篇博客只会详细介绍基于模型的技术。主要有以下几种异常检测方法:
- 基于模型的技术:许多异常检测技术首先建立一个数据模型,异常是那些同模型不能完美拟合的对象。例如,数据分布的模型可以通过估计概率分布的参数来创建。如果一个对象不服从该分布,则认为他是一个异常。
- 基于邻近度的技术:通常可以在对象之间定义邻近性度量,异常对象是那些远离大部分其他对象的对象。当数据能够以二维或者三维散布图呈现时,可以从视觉上检测出基于距离的离群点。
- 基于密度的技术:对象的密度估计可以相对直接计算,特别是当对象之间存在邻近性度量。低密度区域中的对象相对远离近邻,可能被看做为异常。
三、高斯分布(正态分布)
高斯分布也称正态分布,若一个随机变量X服从高斯分布,记为:
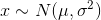 。其中
。其中
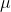 为数学期望,
为数学期望,
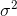 为方差,其概率密度函数为:
为方差,其概率密度函数为:
。其中
为数学期望,
为方差,其概率密度函数为:
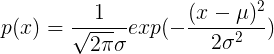
其大体图像如下图所示:
其图像看起来像个钟型,因此又称为钟型曲线。正态分布的期望
决定了其中心位置,标准差
决定了其宽度。如果
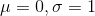 ,则称为标准正态分布,其图像如下图所示:
,则称为标准正态分布,其图像如下图所示:
决定了其中心位置,标准差
决定了其宽度。如果
,则称为标准正态分布,其图像如下图所示:
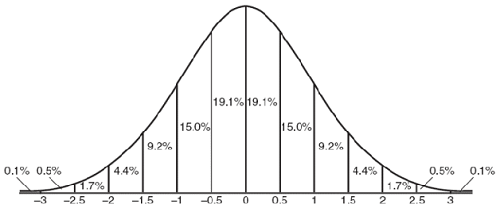
下面再来看几个高斯分布的图像,注意体会
,
对图像的影响:
,
对图像的影响:
参数估计(parameter estimation): 假如给定数据集
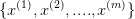 ,已知数据集中样本服从正态分布,即
,已知数据集中样本服从正态分布,即
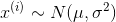 ,那么该如何求出参数
和
,那么该如何求出参数
和
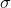 呢?这便是参数估计。我们有如下公式来估计
,
:
呢?这便是参数估计。我们有如下公式来估计
,
:
,已知数据集中样本服从正态分布,即
,那么该如何求出参数
和
呢?这便是参数估计。我们有如下公式来估计
,
:
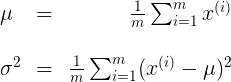
具体到features公式为:
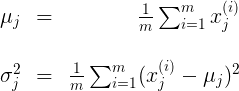
四、异常检测算法
对于给定的训练集:
,对于每一个样本x都有
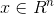 ,即每个样本都是一个n维向量,那么可以建立一个概率模型来估计每个样本的概率密度:
,即每个样本都是一个n维向量,那么可以建立一个概率模型来估计每个样本的概率密度:
,对于每一个样本x都有
,即每个样本都是一个n维向量,那么可以建立一个概率模型来估计每个样本的概率密度:
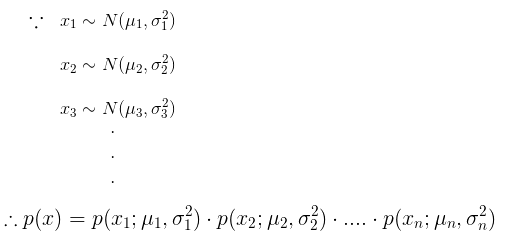
结合三中讲的参数估计,我们可以得到一个异常检测算法:

写到这,大家应该有个疑问:就是这个
 值是怎么确定的?其实这个
是个经验值,NG给出的方法是选择在验证集上使评估指标(如F-measure)值最大的那个
。
值是怎么确定的?其实这个
是个经验值,NG给出的方法是选择在验证集上使评估指标(如F-measure)值最大的那个
。
值是怎么确定的?其实这个
是个经验值,NG给出的方法是选择在验证集上使评估指标(如F-measure)值最大的那个
。
以上就是异常检测的算法,能够很好的检测出离群点。接下来看一个例子,如何运用上述异常检测算法来识别出异常点:(例子来自ng machine learning 课)
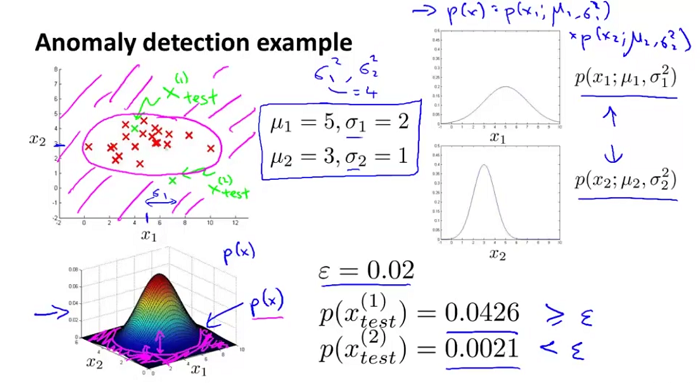
上图中对于给定的两个测试样本
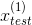 、
、
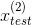 ,可以分别计算出它们的概率密度,分别为0.0426,0.0021,然后分别和给定的
值比较,能够得出
为离群点。
,可以分别计算出它们的概率密度,分别为0.0426,0.0021,然后分别和给定的
值比较,能够得出
为离群点。
、
,可以分别计算出它们的概率密度,分别为0.0426,0.0021,然后分别和给定的
值比较,能够得出
为离群点。
五、异常检测算法的评估
前面也讲过,对于数据集怎样划分训练集,交叉验证机和测试集,在异常检测中同样也需要这样划分数据集。下面给出一个划分的例子:

数据集划分好了,我们还需要一些指标去评估我们的算法,因此precision、recall和F-Measure又能派上用场了,关于这几个评估指标在前面博客关于不平衡算法的评估方法
http://blog.csdn.net/u012328159/article/details/51282428详细讲过,如果有不清楚的同学可以参见这篇博客。
六、异常检测VS监督学习
异常检测算法基本已经介绍完了,大家可能会想到异常检测算法和前面讲过的监督学习算法(线性回归、逻辑回归、神经网络等)有什么区别呢,貌似都可以看做是个分类问题,对样本的label做出判断。。下面就来比较一下异常检测算法和监督学习算法的区别以及各自的特点,然后对比下它们各自的适应场景,给大家一个直观的理解。
先来看看异常检测算法和监督学习算法的对比:

总结来讲:在异常检测中,异常点是少之又少,因此监督学习算法很难从这些异常样本中学到什么。。。
下面来看一下异常检测算法和监督学习算法的各自应用场景:

七、如何设计选择features
实际上影响一个学习算法效率的因素之一就是特征,你选择使用什么样的特征,作为机器学习算法的输入,得到的效率绝对是不一样的。因此,接下来介绍下在异常检测算法中怎样设计选择特征变量 。
异常检测算法其实就是对符合高斯分布的数据建模,如果样本不是很符合高斯分布,算法也可以很好的运行,但是如果把样本转换成高斯分布,算法的效果会更好。有时候我们会遇到样本不符合高斯分布的情况,而且偏的有点远,因此这时通常来讲我们需要对数据进行转换,让其符合高斯分布,一般可以通过对数转(log(x))进行转换。例如:
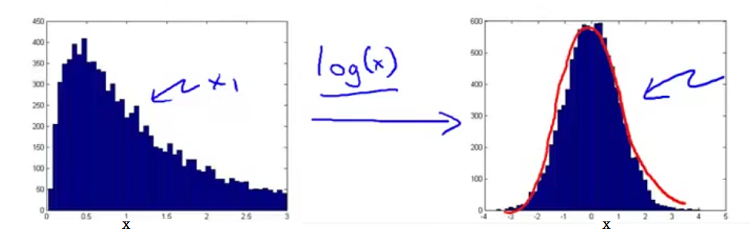
有时候我们还需要根据实际应用情况设计新的特征变量来帮助异常检测算法更好的检测离群点。举个检测网络系统的例子来看看怎样设计出更合理的特征:

从上图能够看出我们新设计的特征
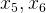 能够更好的反应出网络的异常情况。
能够更好的反应出网络的异常情况。
能够更好的反应出网络的异常情况。
八、多元高斯分布
多元高斯分布有其优点也有其局限性,我们先来看看其优点。其优点是能够捕捉到上面模型捕捉不到的异常样本,来看一个例子:
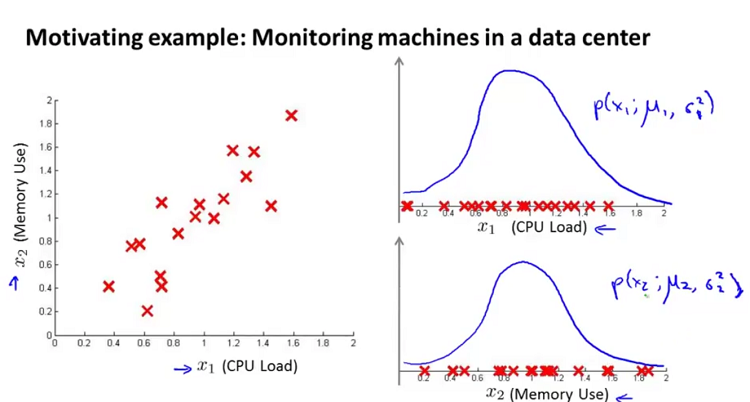
(1)我们的原始数据为下图所示(图左为二维的数据,图右为把两个特征分别当做高斯分布来建模)
(2)假如有个异常点(绿色样本点)如下图左中所示,其在下图右中的检测情况为:
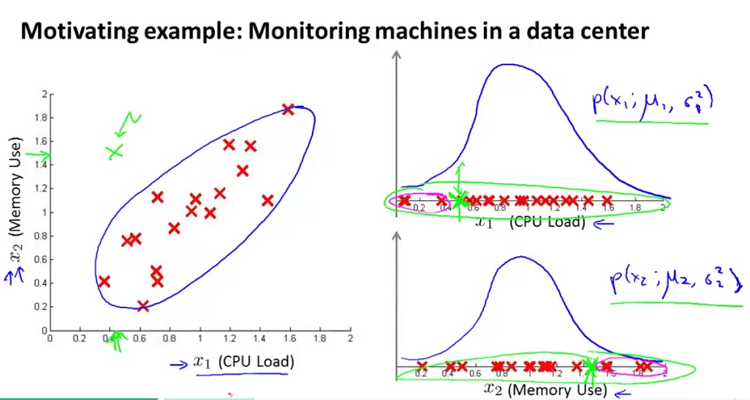
从上图能够看出,这个绿色的异常样本在单独建模的模型中并不能检测出来。因此这就需要通过多元高斯分布构建模型来检测。
多元高斯分布的概率密度函数为:
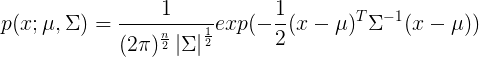
其中
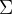 为n*n维协方差矩阵,
为n*n维协方差矩阵,
 为矩阵
的行列式。
为矩阵
的行列式。
为n*n维协方差矩阵,
为矩阵
的行列式。
下面我们来看一些例子,来说明向量
和矩阵
对概率密度函数的影响。
和矩阵
对概率密度函数的影响。
先来看
的影响:
的影响:
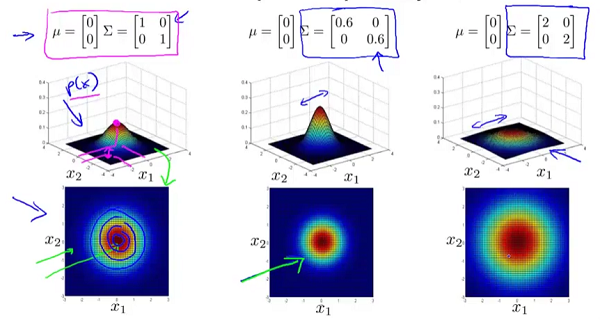
图一
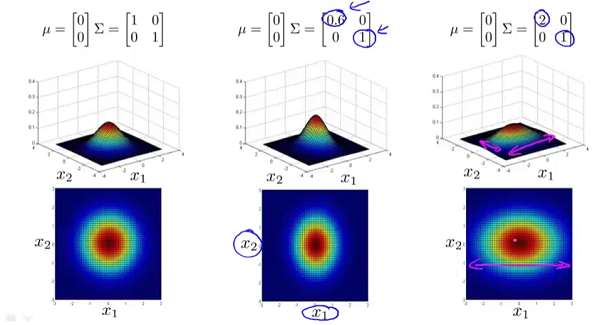
图二
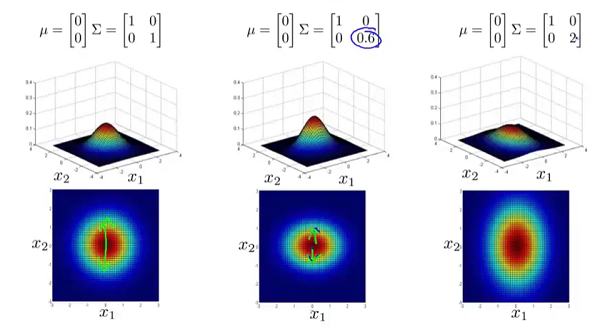
图三
从上面三个图中可以看出当矩阵
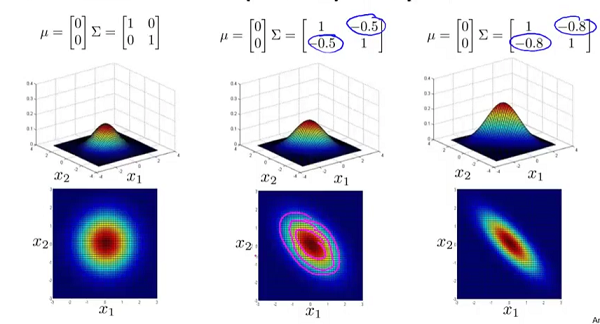
的副对角线都为0时,主对角线上的元素大小控制着概率密度函数俯瞰图的形状大小,至于具体到数字大小对应的形状,大家自己观察便知。
的副对角线都为0时,主对角线上的元素大小控制着概率密度函数俯瞰图的形状大小,至于具体到数字大小对应的形状,大家自己观察便知。
再来看看主对角线不变,变化副对角线是如何影响的例子:
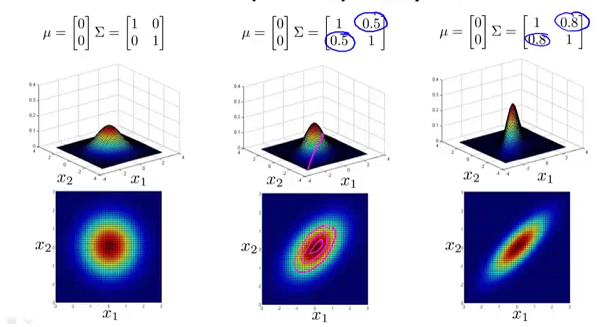
图四
图五
能够看出,副对角线控制的是倾斜程度。
下面来看看
对概率密度函数的影响:
对概率密度函数的影响:
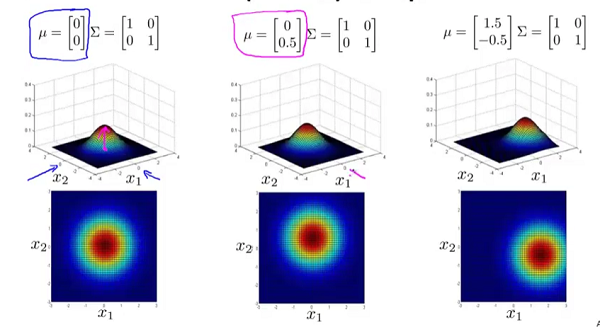
从上图能够看出
控制着图形的位置变化。
控制着图形的位置变化。
九、多元高斯分布在异常检测上的应用
介绍完多元高斯分布,下面我们来介绍下通过多元高斯分布推导出来的异常检测算法:

下面我们来看下多元高斯分布模型与多个一元高斯模型之间的关系:
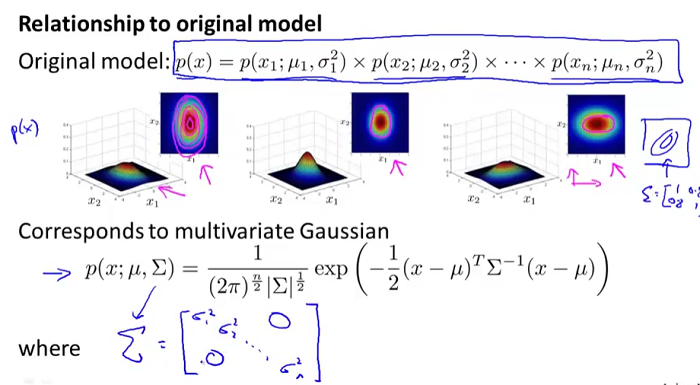
其实就是当多元高斯分布模型的协方差矩阵
为对角矩阵,且对角线上的元素为各自一元高斯分布模型的方差时,二者是等价的。
为对角矩阵,且对角线上的元素为各自一元高斯分布模型的方差时,二者是等价的。
下面来总结比较下多元高斯分布模型和多个一元高斯分布模型:

以上就是关于异常检测的一些知识点。