什么是异常检测
简单来说异常检测就是在一大堆数据中将正常的数据和异常的数据分开,把异常数据检测出来。具体方法就是通过训练集训练出一个可以用来做分类的函数。在进行异常检测的时候所提供的训练集有下面几种类型:
1、训练集里面的样本都有标记,如果在测试集里根据分类函数分出来的某个样本不属于训练集里的任何一个类别则判定该样本为未知;
2、训练集里所有样本均为正常样本;
3、训练集里存在少许异常样本,但大多数均为正常样本,但是没标记。
所以异常检测和普通分类问题的最大区别就在于异常检测中异常的样本极少,而普通分类中几种样本的数量上不会有太大的差异。
异常检测的指标
在用训练出来的分类函数对测试集进行分类之后,模型会输出两个参数,一个是所分类别,另一个是对所分类别的置信度。
如何评判一个模型的好坏呢?
我们一般会用分类的准确率的高低来评判一个模型的好坏,但是在异常检测中由于异常样本数极少,所以不管用什么模型来进行分类,分类准确率都会比较高。
第一种情况:有标记的样本
数据集里面有100个辛普森家族成员的照片和5张不是辛普森家族成员的照片,我们进行异常检测,发现按照某个模型来分类的话,如果设阈值
为下图,则在5个异常样本中错分了4个到正常样本,我们把这错分的4个样本叫missing;此外在100个正常样本中错分了1个到异常样本,我们把这1个错分的样本叫做False alarm。

当我们把阈值
设为如下图时,我们的missing和False alarm就变了。

从上面的两张图可以知道用missing和False alarm来对分类模型的好坏进行评价比用准确率来评价效果会好得多。但是另一个问题就出现了,用什么规则来定义missing和False alarm对模型好坏的影响力呢?
这时候就要人为制定一个规则了,比如:

在Cost Table A中我们定义一个missing加1分,一个False alarm加100分,那么计算上面两种情况会发现当
接近0.5时得分为104分,当
接近0.8时得分为603,很明显在这个规则下
接近0.5时的模型更好一些。
在Cost Table B中我们定义一个missing加100分,一个False alarm加1分,那么计算上面两种情况会发现当
接近0.5时得分为401分,当
接近0.8时得分为306,很明显在这个规则下
接近0.8时的模型更好一些。
至于到底怎么选择Cost Table我们要根据实际应用来决定。
第二种情况:没有标记的样本
在训练样本没有被标记的情况下,我们要根据训练样本生成一个概率模型 ,然后将测试集中的每个样本代入概率模型 ,如果算出来的概率 则认为这个样本是正常的,如果计算出来的概率 则认为样本是异常的。这里面的阈值 是开发人员自己定义的。
那么我们要怎么求这个概率模型呢?
这里我们就要用到极大似然估计了。假设训练样本是从一个概率密度函数
产生的,那么这个函数中的
决定了
的形状,但
是未知的,我们的目的就是找到一个能使得训练集从概率密度函数
中产生的概率最大的
。
比如说我们有一组训练集样本
,我们设生成训练集的概率密度函数为
,则要想让生成训练集的概率最大,我们就要求解下面的函数:
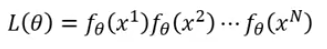
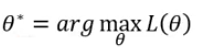
新问题又来了,怎么找这个概率函数
呢?
我们通常会用高斯分布作为概率模型,然后求出高斯分布的参数从而确定模型。至于为什么用高斯分布,可以参考另一篇文章—— 概率生成模型。
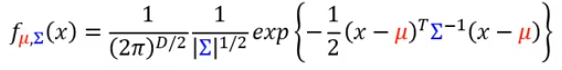
参数
是平均值,
是协方差。
如果我们的训练集产生的分布如下所示,当我们用高斯分布当作生成模型时不同的
会呈现不同的效果,就像下图中所示,很显然比较大的
函数可以使得高斯分布效果更好一些。

下面来求取参数:

