参考论文:
《基于标签传播的社区挖掘算法研究综述》王庚等
参考博客:
https://www.cnblogs.com/end/p/6364345.html
基础概述
开始了解社区发现的时候,我以为这只是一种算法。后来深入下去才知道,它的状态是,上有老下有小的情况。
向上走:社区发现
复杂网络聚类
图论
由于项上走实在知识面太广,有待后期学习。所以决定先往下走。
向下走:各种相关算法 如LPA、BMLPA、LPAm、LPAm+、Fast Unfolding……
虽然社区发现算法的孩子也很多,但是它们兄弟之间都是有相关性的。各有优劣。下面我将首先对社区发现的相关概念做出论述后,再一一介绍社区发现算法的孩子们的故事。
社区:我们认为一张图中连接紧密的一组点构成的集合为一个社区。而社区与社区之间的连接是非常稀疏的。
社区发现:顾名思义,就是在关系图中找社区的过程。需要注意的是,社区发现是一种半监督学习。
随机图:一个图中任何两点之间边的概率相等。首先,确定n个点,然后以固定概率去给图中一对顶点连边,形成随机图 (这个过程可以用过邻接矩阵完成)
那么随机图跟我们的社区发现有什么关系呢?其实它就是一个参照。我们可以这样认为,随机图就是一张底线图,因为随机图中各节点的连线都是随机的,且每两个节点的连线概率都是相等的,因此认为随机图中基本没有所谓社区可言。因此认为与随机图相差越大,社区结构约明显。那么如何来衡量区别大小呢,就是用Modularity系数 (Newman 和 Girvan于2004年提出的)。
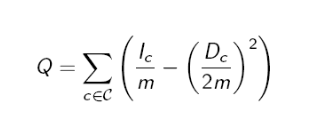
m,图中总边数;
:社区c中所有内部边的条数
:社区c中所有定点的度之和
公式理解:首先,计算每个社区,内部边的条数占图中总条数的比例与社区中总度数占图中总度数的比例之差。然后计算所有划分出的社区的这个值。
问题思考:根据概念,modularity 是与随机图有紧密关系的,怎么体现出与随机图的紧密关系。
个人理解:如果是随机图情况,相较于社区结构较明显的图,
较小,而
较大,整体也就较小。所以Q越大,图的社区结构越明显。
开始我们的算法之旅吧
社区发现的算法分类方式:异步算法和同步算法、重叠算法和非重叠算法
同步算法:是指一次更新全部节点,本次每个节点标签的更新结果只与之前的结果有关,与本次更新结果无关。
异步算法:是指本次对每个节点的更新不仅与之前的结果有关,还与本次已更新完的结果有关。假设节点 i 要依赖节点j进行更新,但节点 j 在本轮迭代中已经更新为了 j’ ,那么在异步算法中,将使用 j’ 来更新节点 i 。
实验研究表明,异步更新策略相对同步更新来说可能需要更多的迭代次数,但是得到的社区结构也相对更加稳定。
非重叠算法:每个节点标签是唯一的。
重叠算法:每个节点标签是不唯一的。
好了,下面开始来我们的经典算法吧。下面是我们的算法讲述流程图。
LPA算法
LPA算法是2002年由zhu等提出的,在2007年被Usha、Nandini、Raghavan应用到了社区发现领域,提出了RAK算法。但是大部分研究者称RAK算法为LPA算法。
算法思想:
- 为所有节点指定一个唯一标签
- 逐轮刷新所有节点的标签,直到达到收敛要求为止。
刷新规则:
以邻域中出现最多的那一类为中心点label。
缺点:可能出现所有顶点被划分到一个巨大社区的情况。为了防止这种情况发生,LPAm算法被提出。
LPAm算法
LPAm算法,即模块化标签传播算法。2009年由Lan X.Y提出。主要有Hop Attenuation(跳跃衰减)和Node Preference(节点倾向性选择)两部分组成。
- Hop Attenuation
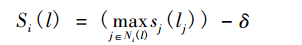
式中, 表示的是节点 i 上标签 l 的评分; 表示的是节点 j 的标签; 表示的是节点 i 的邻接点中标签为 的节点集合; 为衰减因子。初始化时节点的评分为 1,随着标签传播的过程评分会逐渐地减小,当评分降低为 0 的时候, 这个标签就无法再传递给其他节点,通过引入跳跃衰减的策略就能有效地避免大社区的形成。
- Node Preference
通过后续的研究, 实验结果发现跳跃衰减结合节点倾向性选择将能取得更好的效果, 在这两种策略结合的情况下,节点 i 的新标签 为:
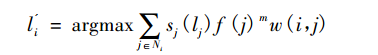
其中,
表示节点 i 和节点 j 之间边的权重;
表示的是节点倾向性选择函数; m 参数起到一个平衡因子的作用。Barber 等人在实验中初始
, 即表示节点的度数为 1。这样的话, 如果取
, 就表示算法倾向于选择邻接点中度数较大的节点所带有的标签,若一开始取 m < 0 则表示相反的选择。在通常情况下,m 取 0.1。
缺点:可能会存在陷入局部极大值情况。为了防止这种情况提出了LPAm+算法。
LPAm+
LPAm+ 算法实际上就是LPAm算法与MSG算法合并。
方法:通过MSG算法,可有效合并多个相似社区。具体方法可以查阅资料,或等待后期更新。
COPRA算法和BMLPA算法
COPRA算法,是一种重叠算法。BMLPA 算法(Balanced Multi-Label Propagation Algorithm),由北京交通大学武志昊于2012年提出的。它是一种重叠挖掘算法,是对COPRA算法的改进。
COPRA算法:
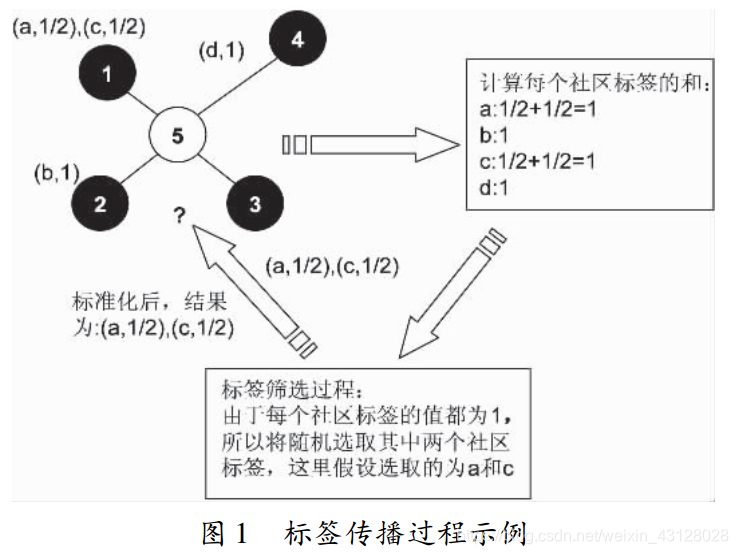
社区标签计算(c,b)。
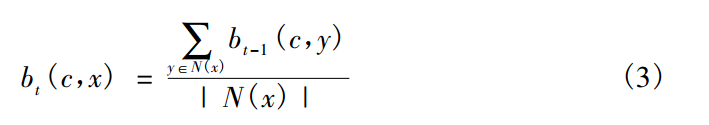
首先要计算其邻接点中所存在的社区标签的和, 接下来选择 v个数值最大的标签( v 表示设定的重叠社区个数, 图中v 的值为 2) 。若存在多个可选标签的话, 这时就需要进行标签的随机选择, 最后再将所选的标签进行标准化得到节点 5 的标签更新结果。
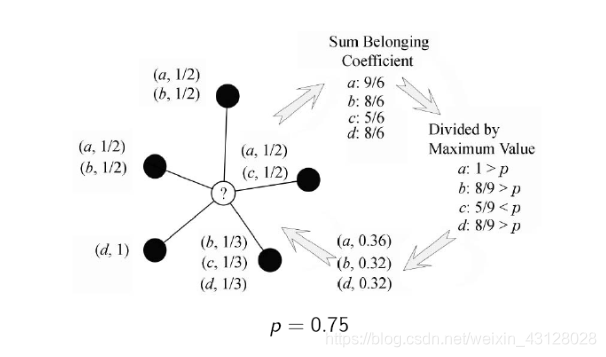
BMLPA的条件是不再局限于v个,而是通过更改阈值p来限制标签数。
优缺点:
COPRA算法,在遇到存在多个标签可选的情况下,该算法会随机进行选择,在这个过程中会导致该算法不稳定性。
BMLPA算法,不再需要初始化v的值,也就是说挖掘的重叠社区数目不再受参数v的限制。这样做虽然增加了算法的稳定性,但随之带来的是该算法挖掘得到的社区结构比较固定,使得算法的适应性有所下降。