转自:https://blog.csdn.net/fenghuangdesire/article/details/45823329
在社区内部节点之间连接密切,边密度高,容易形成派系(clique)。因此,社区内部的边有较大可能形成大的完全子图,而社区之间的边却几乎不可能形成较大的完全子图,从而可以通过找出网络中的派系来发现社区。

k-派系表示网络中含有k个节点的完全子图,如果一个k-派系与另一个k-派系有k-1个节点重叠,则这两个k-派系是连通的。由所有彼此连通的k-派系构成的集合就是一个k-派系社区。
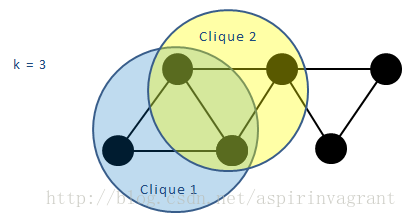
由所有彼此连通的k-派系构成的集合就是一个k-派系社区。
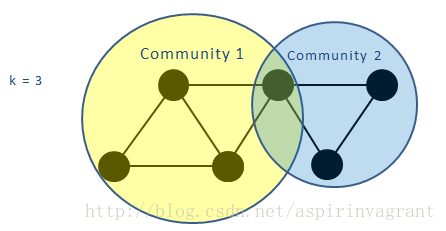
网络中会存在一些节点同时属于多个k-派系,但是它们所属的这些k-派系可能不相邻,它们所属的多个k-派系之间公共的节点数不足k-1个。这些节点同属的多个k-派系不是相互连通的,导致这几个k-派系不属于同一个k-派系社区,因此这些节点最终可以属于多个不同的社区,从而发现社区的重叠结构。
所以CPM算法的过程是首先寻找网络中极大的完全子图(maximal-cliques),然后利用这些完全子图来寻找k-派系的连通子图(即 k-派系社区),不同的k值对应不同的社区结构。找到所有的k-派系之后,可以建立这些派系的重叠矩阵(clique overlap matrix)。在这个对称的矩阵中,每一行(列)代表了一个派系,矩阵中的非对角线元素代表两个连通派系中共享的结点的数目。对角线元素代表派系的规模。将小于k-1的非对角线元素置为0,小于k的对角线元素置为1,得到k-派系连接矩阵,每个连通部分构成了一个k-派系社区。

由于k是个输入参数值,从而k的取值将会影响CMP算法的最终社区发现结果,当k取值越小社区将会越大,且社区结构为稀疏。但是实验证明k的取值影响不是很大,一般k值为4到6。然而,由于该算法是基于完全子图,因此CPM比较适用于完全子图比较多的网络,即边密集的网络,对于稀疏网络效率将会很低,且该算法还无法分配完全子图外的顶点。CPM的效率取决于寻找所有极大完全子图的效率,尽管寻找所有极大完全子图是NP完全问题,但在真实网络上是非常快的。
**如何寻找极大完全子图**?
极大完全子图是不能在扩展的,那么首先随机选取种子节点,然后在种子节点周围扩展成完全子图,如果这个完全子图不能再被扩展,那么我们就找到了极大完全子图。但是这种方式可能会将同一个极大完全子图产生多次。
下面给出寻找某个点a极大完全子图Q的算法,主要思想是如果x是在Q里,那么它一定是a的邻居。

参考资料:
Social and Information Network Analysis Jure Leskovec, Stanford University