一.分层自动化测试:ui代表页面级系统测试,service代表服务业务测试(接口测试),unit代表单元测试。Unit占70%,service占20%,UI占10%。
单元测试(unit):它可以通过mock框架,模拟各种异常场景,外部依赖最少,且可以做到测试粒度到最小的一种测试方法。也因为依赖少,可方便随时随地执行,也让问题排查很简单。这是一切测试的地基。
接口测试(service):这里要求测试人员对系统的结构和系统间的调度非常清楚,同时要了解接口逻辑关系,否则接口测试代码很容易遗漏一些异常场景。这一层由于含有一些业务逻辑和多接口的一个集成,所以相对单元测试来说,多了一些外界依赖,导致问题定位不会有单元测试层那么准确。因此投入会比单元测试多一些。
页面测试(ui):是常见的黑盒自动化测试场景。它最接近用户真实场景,也容易发现问题,但它的实现成本最高且太容易受外部依赖,影响脚本成功率,所以处在金字塔的顶端,但它不是金字塔的全部。自动化测试的劣势,其中80%都是因为ui自动化。
分层自动化测试倡导的就是,将系统分层,不同层次用合适的自动化方法进行测试的一种测试策略。
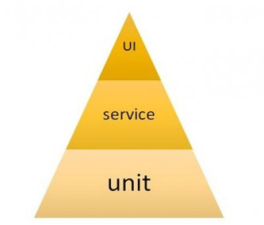
金字塔越高的部分表示需要投入的工作量和精力越大。
二.适合自动化测试的测试场景:
1)任务明确,不会频繁变动
2)回归测试比较频繁
3)界面比较稳定
4)有大量的重复任务
5)软件的维护周期较长
6)项目进度方面的压力较小
7)测试人员具备较强编程能力
自动化测试用例从手工测试用例中选取,如果迭代周期短,可以选取功能测试中的核心部分进行测试。
三.常用的自动化测试工具:
1) UTF=QTP,主要用于回归测试和同软件新版本测试,支持B/S和C/S架构。
2)RF(Robot Framework),python编写的功能自动化测试框架。具备良好的可扩展性,支持关键字驱动,可以同时测试多种类型的客户端或者接口,可以进行分布式测试执行。主要用于轮次很多的验收测试和验收测试驱动开发。
3)Selenium,用于Web应用程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样,主要功能包括:测试与浏览器的兼容性,测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。
四.Selenium:
selenium1.0版本
selenium IDE
Firefox浏览器中的一个小插件,实现浏览器操作的录制与回放
selenium Grid
用来对测试脚本做分布式执行,即实现在多台机器上和异构环境中运行测试用例(分布式的概念是写好一条用例可以调用不同的平台执行,如 A电脑上有一个测试用例,可以调用B电脑(linux)的 Firefox浏览器来跑A电脑上的测试用例;也可以调用C电脑(windows)的 Chrome浏览器来跑A电脑上的测试用例,这是分布式的概念)
selenium RC
使用浏览器内置的JavaScript 翻译器来翻译和执行selenese 命令(selenese 是 selenium 命令集合)
支持多种不同的语言编写测试脚本,通过selenium RC的服务器作为代理服务器去访问应用,达到测试的目的
① client libraries:用于编写测试脚本,用来控制selenium server的库,暴露API供调用
② selenium server:负责控制浏览器行为,Selenium Server 主要包括3 个部分:Launcher、Http Proxy、Core
Launcher:用于启动浏览器,把selenium Core加载到浏览器页面当中,并把浏览器的代理设置为selenium server的HTTP Proxy
Http Proxy:拦截请求
Selenium Core:就是一堆JavaScript函数的集合,即通过这些函数,解释成selenese命令,我们才可以实现用程序对浏览器进行操作
selenium 2.0版本:selenium+webdriver
通过WebDriver 去替代RC,webdrive提供了更出色的API,可以绕过JS,直接控制浏览器,更快,安全性更高。但为了保持兼容性,所以selenium 2.0中,RC 和webdriver 并存,但说起selenium 2.0 一般指的是webdriver
selenium 3.0版本
将Firefox独立化,对IE、Edge等浏览器有了更好的支持。彻底废弃了RC
selenium环境搭建
1)在线安装selenium:在python的pip路径下打开cmd,输入pip install selenium
Pip可以安装python的一些库,setuptools
2)离线安装selenium:下载好文件后,在文件路径下打开cmd,输入python setup.py install
Firefox中IDE
1)安装IDE,将下载好的IDE文件直接拖拽进Firefox浏览器中即可。
2)安装好之后在右上角打开IDE可以开始录制与回放了
IDE可以在录制完成后生成.py脚本文件,但我们一般不用此功能。
五.使用selenium通过七种元素或方法定位web中的模块:
先调用Firefox的webdriver打开Firefox浏览器然后通过driver.get()API打开www.baidu.com。

1.通过元素“id”定位到输入框并输入文字

2.通过元素“name”定位到输入框并输入文字

3.通过元素“class”定位到输入框并输入文字(若class的属性值中包含空格,我们一般不使用class进行定位)
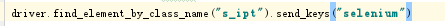
4.通过“link”来定位A标签

5.通过“patail_link”来定位A标签

6.通过xpath来定位web中的模块。绝对路径从根目录开始,以“/”开始。相对路径不需要从根目录开始,可以从某个有特定标志的目录下开始,以“//”开始。
相对路径:

绝对路径:

7.通过css来定位模块。css中绝对路径使用“空格号”或者“>”,但使用css来定位一般不使用绝对路径。
css通过id定位:

css通过class定位:
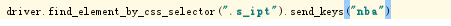
css通过id定位时用“#”开始,通过class定位时用“.”开始。
六.Webdriver中的一些其他API。
1)回退:
driver.back()
2)前进
driver.forward()
3)刷新
driver.refresh()
4)设置浏览器的大小
driver.set_window_size(480,320)
5)浏览器全屏
driver.maximize_window()
6)清除输入框的内容
driver.find_element_by_id(“kw”).clear()
7)查看定位的框的尺寸,可用print(size)打印结果
size = driver.find_element_by_id(“kw”).
print(size)
8)获取选定位置文本内容
driver.find_element_by_id(“kw”).text
9)获得属性值,括号里写需要查询的属性名,可用print()打印结果
attribute = driver.find_element_by_id(“kw”).get_attribute(‘name’)
10)看选定的位置是否显示出来,一般值是true或者false,后面可以调用if语句
result = driver.find_element_by_id(“kw”).is_displayed()
11)设定休眠时间:进入一个网页后等待一段时间后执行命令,括号里是等待的时间
import time
time.sleep(5)