图
直观显示图结构的方法:用小圆圈或小方块代表顶点,用连接于其间的直线段或者曲线弧表示对应的边。
图:无向图、有向图及混合图
深度优先搜索实质功能:先将当前节点v标记为DISCOVERED(已发现)状态,再逐一核对其各邻居u的状态并做相应处理。待其所有邻居均以处理完毕之后,将顶点v置为VISITED(访问完毕)状态,便可回溯。
深度优先搜索
从图的某个顶点出发,访问图中的所有顶点,且使每个顶点仅被访问一次。这一过程叫做图的遍历。
深度优先搜索的思想:
①访问顶点v;
②依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
③若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
比如:
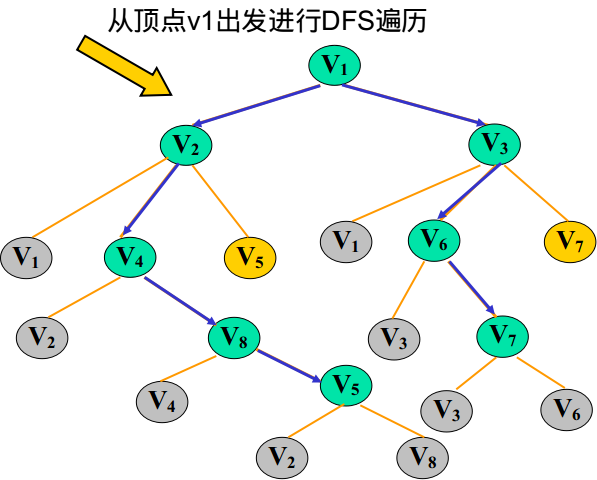
在这里为了区分已经访问过的节点和没有访问过的节点,我们引入一个一维数组bool visited[MaxVnum]用来表示与下标对应的顶点是否被访问过,
流程:
☐ 首先输出 V1,标记V1的flag=true;
☐ 获得V1的邻接边 [V2 V3],取出V2,标记V2的flag=true;
☐ 获得V2的邻接边[V1 V4 V5],过滤掉已经flag的,取出V4,标记V4的flag=true;
☐ 获得V4的邻接边[V2 V8],过滤掉已经flag的,取出V8,标记V8的flag=true;
☐ 获得V8的邻接边[V4 V5],过滤掉已经flag的,取出V5,标记V5的flag=true;
☐ 此时发现V5的所有邻接边都已经被flag了,所以需要回溯。(左边黑色虚线,回溯到V1,回溯就是下层递归结束往回返)
☐
☐ 回溯到V1,在前面取出的是V2,现在取出V3,标记V3的flag=true;
☐ 获得V3的邻接边[V1 V6 V7],过滤掉已经flag的,取出V6,标记V6的flag=true;
☐ 获得V6的邻接边[V3 V7],过滤掉已经flag的,取出V7,标记V7的flag=true;
☐ 此时发现V7的所有邻接边都已经被flag了,所以需要回溯。(右边黑色虚线,回溯到V1,回溯就是下层递归结束往回返)广度优先搜索
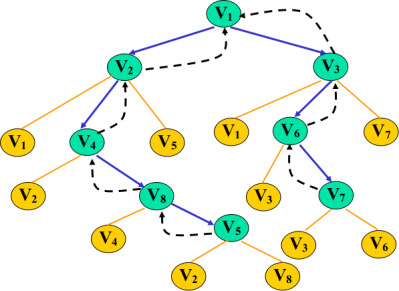
所谓广度,就是一层一层的,向下遍历,层层堵截,还是这幅图,我们如果要是广度优先遍历的话,我们的结果是V1 V2 V3 V4 V5 V6 V7 V8。
广度优先搜索的思想:
① 访问顶点vi ;
② 访问vi 的所有未被访问的邻接点w1 ,w2 , …wk ;
③ 依次从这些邻接点(在步骤②中访问的顶点)出发,访问它们的所有未被访问的邻接点; 依此类推,直到图中所有访问过的顶点的邻接点都被访问;
说明:
为实现③,需要保存在步骤②中访问的顶点,而且访问这些顶点的邻接点的顺序为:先保存的顶点,其邻接点先被访问。 这里我们就想到了用标准模板库中的queue队列来实现这种先进现出的服务。
老规矩我们还是走一边流程:
说明:
☐将V1加入队列,取出V1,并标记为true(即已经访问),将其邻接点加进入队列,则 <—[V2 V3]
☐取出V2,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V3 V4 V5]
☐取出V3,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V4 V5 V6 V7]
☐取出V4,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V5 V6 V7 V8]
☐取出V5,并标记为true(即已经访问),因为其邻接点已经加入队列,则 <—[V6 V7 V8]
☐取出V6,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V7 V8]
☐取出V7,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[V8]
☐取出V8,并标记为true(即已经访问),将其未访问过的邻接点加进入队列,则 <—[]
拓扑排序
有向无环图:顶点A和B互换之后依然是一个拓扑排序,所以同一有向图的拓扑排序未必唯一。
不含环路的有向图------有向无环图一定存在拓扑结构吗?答案是肯定的。
有向无环图的拓扑结构一定存在。因为有向无环图对应于偏序关系,而拓扑排序则对应于全序关系。
DFS搜索善于检测环路的特性,恰好可以用来判别输入是否为有向无环图。
在图论中,拓扑排序(Topological Sorting)是一个有向无环图(DAG, Directed Acyclic Graph)的所有顶点的线性序列。且该序列必须满足下面两个条件:
第一,每个顶点出现且只出现一次。
第二,若存在一条从顶点 A 到顶点 B 的路径,那么在序列中顶点 A 出现在顶点 B 的前面。
有向无环图(DAG)才有拓扑排序,非DAG图没有拓扑排序一说。
例如,下面这个图:
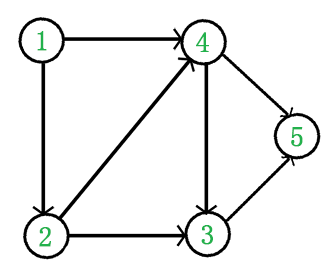
它是一个 DAG 图,那么如何写出它的拓扑排序呢?这里说一种比较常用的方法:
第一,从 DAG 图中选择一个 没有前驱(即入度为0)的顶点并输出。
第二,从图中删除该顶点和所有以它为起点的有向边。
第三,重复 1 和 2 直到当前的 DAG 图为空或当前图中不存在无前驱的顶点为止。后一种情况说明有向图中必然存在环。
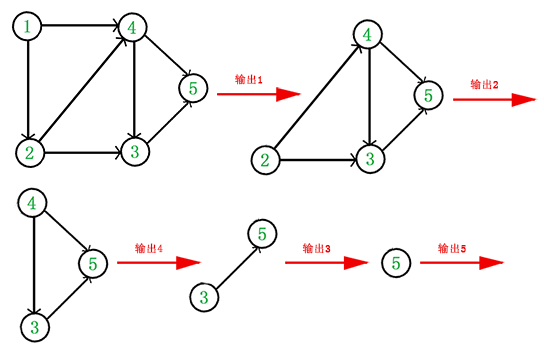
于是,得到拓扑排序后的结果是 { 1, 2, 4, 3, 5 }。
通常,一个有向无环图可以有一个或多个拓扑排序序列。
二、拓扑排序的应用
拓扑排序通常用来“排序”具有依赖关系的任务。
比如,如果用一个DAG图来表示一个工程,其中每个顶点表示工程中的一个任务,用有向边<A,B>表示在做任务 B 之前必须先完成任务 A。故在这个工程中,任意两个任务要么具有确定的先后关系,要么是没有关系,绝对不存在互相矛盾的关系(即环路)。
三、拓扑排序的实现
根据上面讲的方法,我们关键是要维护一个入度为0的顶点的集合。
图的存储方式有两种:邻接矩阵和邻接表。这里我们采用邻接表来存储图,C++代码如下:
#include<iostream>
#include <list>
#include <queue>
using namespace std;
/************************类声明************************/
class Graph
{
int V; // 顶点个数
list<int> *adj; // 邻接表
queue<int> q; // 维护一个入度为0的顶点的集合
int* indegree; // 记录每个顶点的入度
public:
Graph(int V); // 构造函数
~Graph(); // 析构函数
void addEdge(int v, int w); // 添加边
bool topological_sort(); // 拓扑排序
};
/************************类定义************************/
Graph::Graph(int V)
{
this->V = V;
adj = new list<int>[V];
indegree = new int[V]; // 入度全部初始化为0
for(int i=0; i<V; ++i)
indegree[i] = 0;
}
Graph::~Graph()
{
delete [] adj;
delete [] indegree;
}
void Graph::addEdge(int v, int w)
{
adj[v].push_back(w);
++indegree[w];
}
bool Graph::topological_sort()
{
for(int i=0; i<V; ++i)
if(indegree[i] == 0)
q.push(i); // 将所有入度为0的顶点入队
int count = 0; // 计数,记录当前已经输出的顶点数
while(!q.empty())
{
int v = q.front(); // 从队列中取出一个顶点
q.pop();
cout << v << " "; // 输出该顶点
++count;
// 将所有v指向的顶点的入度减1,并将入度减为0的顶点入栈
list<int>::iterator beg = adj[v].begin();
for( ; beg!=adj[v].end(); ++beg)
if(!(--indegree[*beg]))
q.push(*beg); // 若入度为0,则入栈
}
if(count < V)
return false; // 没有输出全部顶点,有向图中有回路
else
return true; // 拓扑排序成功
}测试如下DAG图
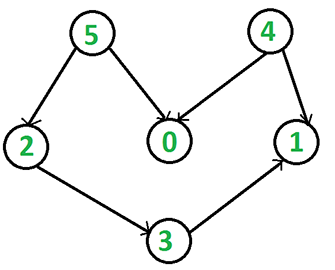
int main()
{
Graph g(6); // 创建图
g.addEdge(5, 2);
g.addEdge(5, 0);
g.addEdge(4, 0);
g.addEdge(4, 1);
g.addEdge(2, 3);
g.addEdge(3, 1);
g.topological_sort();
return 0;
}输出结果是 4, 5, 2, 0, 3, 1。这是该图的拓扑排序序列之一。
每次在入度为0的集合中取顶点,并没有特殊的取出规则,随机取出也行,这里使用的queue。取顶点的顺序不同会得到不同的拓扑排序序列,当然前提是该图存在多个拓扑排序序列。
由于输出每个顶点的同时还要删除以它为起点的边,故上述拓扑排序的时间复杂度为O(V+E)。
双连通域分解
可行算法:DFS树中的叶节点,绝不可能是原图中的关节点。因为此类顶点的删除既不影响DFS的连通性,也不影响原图的连通性。DFS树的根节点若至少拥有两个分支,则必是一个关节点。