深度学习笔记2-激活函数
目前激活函数有sigmoid、Tanh、ReLU、LeakyReLU、ELU。
-
Sigmoid函数
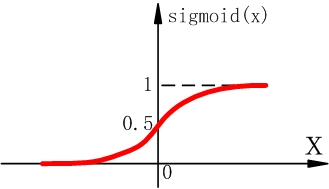
Sigmoid函数表达式 Sigmoid函数在远离坐标原点的时候,函数梯度非常小,在梯度反向传播时,会造成梯度消失(梯度弥散),无法更新参数,即无法学习。另外,Sigmoid函数的输出不是以零为中心的,这会导致后层的神经元的输入是非0均值的信号。那么对于后层的神经元,其局部梯度 永远为正,假设更深层的神经元的梯度反向传递到这为 。根据链式法则,此时后层神经元的全局梯度为 。当 为正时,对于所有的连接权 ,其都往“负”方向修正(因为 为正,要往负梯度方向修正);而当 为负时,对于所有的连接权 ,其都往“正”方向修正。所以,如果想让 中的 往正方向修正的同时, 往负方向修正是做不到的。对于 会造成一种捆绑的效果,使得收敛很慢。如果是按batch来训练的话,不同的batch会得到不同的符号,能缓和一下这个问题。
由于以上两个缺点,sigmoid函数已经很少用了。 -
Tanh函数
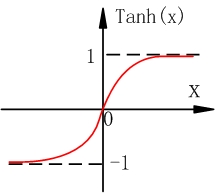
Tanh函数的表达式
Tanh函数能解决sigmoid函数输出不是零均值的问题,但和sigmoid函数一样,Tanh函数还是会存在很大的梯度弥散问题。 -
ReLU函数
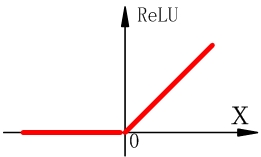
ReLU函数表达式为
ReLU函数在输入为正的时候,不存在梯度弥散的问题,对梯度下降的收敛有巨大加速作用。同时由于它只是一个矩阵进行阈值计算,计算很简单。但它也有两个缺点,一个是当输入x小于零时,梯度为零,ReLU神经元完全不会被激活,导致相应参数永远不会被更新;另一个和sigmoid一样,输出不是零均值的。 -
LeakyReLU函数
为了解决ReLU函数在输入小于零神经元无法激活的问题,人们提出了LeakyReLU函数。
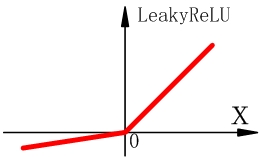
该函数在输入小于零时,给了一个小的梯度(斜率,比如0.01)。因此就算初始化到输入x小于零,也能够被优化。其表达式为 , 为斜率。当把 作为参数训练时,激活函数就会变为PReLU。LeakyReLU以其优越的性能得到了广泛的使用。 -
ELU函数
ELU函数也是ReLU函数的一个变形,也是为了解决输入小于零神经元无法激活的问题。
与LeakyReLU不同的是,当 时, 。
在tensorflow和pytorch中,都已经集成了这些激活函数,可以拿来直接用。详见:
http://www.tensorfly.cn/tfdoc/api_docs/python/nn.html#AUTOGENERATED-activation-functions
https://pytorch.org/docs/stable/nn.html#non-linear-activation-functions