线性回归梳理
机器学习的基本概念:
定义:
机器学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析,简单点来说就是在历史数据中找出一定的规律,对其规律建立相应的数学模型,当输入新的数据时,通过模型的的计算输出期望的结果。
分类:
监督学习:
(supervised learning)监督式学习算法由一个目标变量(因变量)和用来预测目标变量的预测变量(自变量)。通过这些变量构建一个模型,输入一个任意变量,可以得到对应的预测变量。不断重复训练这个模型,调整参数,在训练数据集上达到较高的准确度。
属于监督式学习的算法有:回归模型,决策树,随机森林,K邻近算法,逻辑回归等。
无监督学习:
(unsupervised learning)与监督学习不同的是,无监督学习中我们没有需要预测或估计的目标变量。无监督式学习是用来对总体对象进行分类的。
属于无监督学习的算法有:关联规则,K-means聚类算法等。
其他概念介绍:
泛化能力:(generalization ability)是指学习得到的模型对未知数据的预测能力,是学习方法本质上重要的性质,现实中采用最多的方法是通过测试误差来评价学习方法的泛化能力
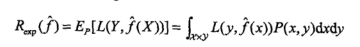
实际上,泛化误差就是所学习到的模型的期望风险
过拟合和欠拟合: 一味最追求提高对数据的预测能力,所选模型的复杂度则往往会比真的模型高,这种现象称为过拟合,一般的解决办法为(增加数据量和或则降低复杂度);相反,预测的数据与实际的数据相差甚多的现象为欠拟合,解决方法有(增加特征因子,增加多项式特征)
交叉验证: 将训练数据随机分成三部分,分别为训练集(training set)、验证集(validation set)和测试集(test set),训练集用来训练模型,验证集用来模型选择,而测试集用于对学习方法的评估。具体分为三种方法:简单交叉验证、S折交叉验证、留一交叉验证
线性回归的原理
线性回归假设特征和结果满足线性关系。通过一个映射函数将特征变量与预测结果形成关系。这样就可以表达特征与结果之间的非线性关系。在Andrew Ng老师视频课程中用预测房价作为例子,比如x1=房间的面积,x2=房间的朝向,等等,这样可以写出一个估计函数:
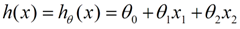
其中θ为权重参数,具体含义为所点成的特征变量在整个变量中所占的比重,比重越大,该特征的影响力越大,在实际应用中越值得考虑。
线性回归涉及的定义函数
损失函数和代价函数: :这两个概念可以一起理解,区别在于损失函数是针对某个样本的误差计算,代价函数只针对整个数据集求平均,简单理解就是实际值与预测值的差值,用函数式表达为:
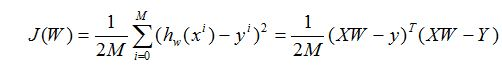
目标函数: :即为最优化后的参数方程:
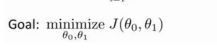
优化方法(主要介绍两种)
梯度度下降:
梯度下降法是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数就J (θ)的最小值。
梯度下降背后的思想是:开始时我们随机选择一个参数的组合,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到到到一个局部最小值(local minimum),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum),选择不同的初始参数组合,可能会找到不同的局部最小值。
具体步骤入下:
①对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量
②改变θ的值,使得J(θ)按梯度下降的方向进行减少。
梯度方向由J(θ)对θ的偏导数确定,由于求的是极小值,因此梯度方向是偏导数的反方向。结果为:
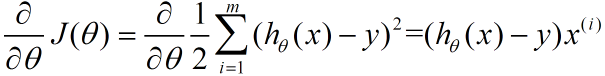

③更新θ,继续计算:
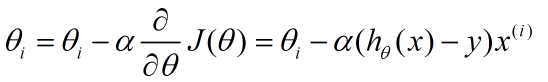
正规方程:
另一种较为直接的方法为最小二乘法:(矩阵可逆)
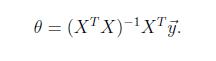
线性回归的评估指标
MSE: Mean Squared Error
均方误差是指参数估计值与参数真值之差平方的期望值;
MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。
RMSE
均方误差:均方根误差是均方误差的算术平方根
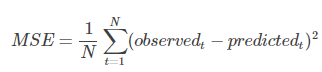
MAE :Mean Absolute Error
平均绝对误差是绝对误差的平均值
平均绝对误差能更好地反映预测值误差的实际情况.
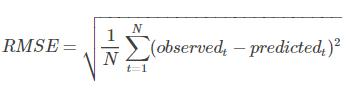
Sklearn参数详解
调用sklearn.linear_model.LinearRegression()所需参数:
- fit_intercept : 布尔型参数,表示是否计算该模型截距。可选参数。
- normalize :normalize : 布尔型参数,若为True,则X在回归前进行归一化。可选参数。默认值为False。
- copy_X :copy_X : 布尔型参数,若为True,则X将被复制;否则将被覆盖。 可选参数。默认值为True。
- n_jobs :n_jobs : 整型参数,表示用于计算的作业数量;若为-1,则用所有的CPU。可选参数。默认值为1。 线性回归fit函数用于拟合输入输出数据,调用形式为model.fit(X,y, sample_weight=None):
- X: X为训练向量;
- y : y为相对于X的目标向量;
- sample_weight : 分配给各个样本的权重数组,一般不需要使用,可省略。