JML语言的理论基础
前言
jml语言是对于Java程序进行规格化设计的一种表示语言,主要有两种用法:
1)开展规格化设计,使得程序员在实现过程中对目的没有二义性。
2)针对已有的实现代码来书写规格可以提高代码可维护性。
常用&核心要素
- 注释结构
JML注释方式有两种:行注释和块注释。每行均以@开头,其中行注释格式为 //@content,块注释格式为/*@content@*/。一般来讲,JML注释位置为被注释部位的上方。
2.JML表达式
JML表达式是对Java表达式的扩展,表达式中的操作符也存在优先级顺序。需要注意的是JML相对于java新增的表达式成分仅用于JML中断言和其他相关的注释体,JML断言中不可以使用带有赋值语句的操作符,如++,--,+=等。
2.1 原子表达式
\result表达式:表示一个非void类型的方法执行的返回值。
\old(expr)表达式:表示一个表达式在相应方法执行前的取值。需要注意的是:对于对象引用,只能判断引用本身是否发生变化,不能判断引用所指向的对象实体内容是否变化。比如:\old(pList).size()与\old(pList.size())。目的是想对pList进行增删操作后比较前后数组大小。那么\old(pList).size()的数值在pList进行增删等操作情况下是有变化的,如果pList没有重新赋予地址的话,\old(pList)还是指向未改变pList的地址,得到的\old(pList).size()和pList.size()是一致的。但我们原来的想法是现在的变量和之前pList大小进行比较,因此应该将pList.size()整项括起来,表示这个数值。
因此,最好的办法是将要比较的内容全部括起来,最保险。
\not_assigned(x、y……)表达式:表示括号中变量是否在方法执行中被赋值,如果没有被赋值返回值为true,否则为false。一般用于后置条件的约束。
\not_modified(x、y……)表达式:与上述类似,表示括号中变量是否在方法中被修改。
\nonnullelements(container)表达式:表示container对象中存储的对象不会有null。
\type(type)表达式:返回类型type对应的类型。
\typeof(expr)表达式:返回表达式值对应的准确类型。
2.2 量化表达式
\forall表达式:用于给定范围内所有元素均要满足相应约束。
一般写法:(\forall element;sphere;constrain)。
\exists表达式:用于给定范围中存在元素可以满足相应约束。
一般写法:(\exists element;sphere;constrain)。
\sum表达式:返回给定范围中对应表达式的和。
一般写法:(\sum element;sphere;expression)。
\product表达式:返回给定范围中对应表达式相乘的结果。
一般写法:(\product;element;sphere;expression)。
\max表达式:返回给定范围中对应表达式最大值。
一般写法:(\max;element;sphere;expression)。
\min表达式:返回给定范围中对应表达式最小值。
一般写法:(\min element;sphere;expression)。
\num_of表达式:返回给定范围中满足相应条件取值个数。
一般写法:(\num_of element;sphere;condition)。
2.3 集合表达式
集合构造的目的是构造一个容器,比如规格描述中存在中间变量集合,或者返回值为一个集合。
一般形式:new ST {T x | R(x)&&P(x)}。其中R(x)为x的范围,P(x)为对应x的取值约束。
2.4 操作符
操作符包括算术操作符、逻辑运算符、关系运算符,还有新定义的以下四种。
1) E1<:E2.子类型关系操作符,表达式为真当且仅当E1是E2的子类型或者同类型。
2) Expr1<==>Expr2或者Expr1<=!=>Expr2.等价关系操作符,其中Expr1和Expr2均为布尔表达式,与Expr1==Expr2或者Expr1!=Expr2含义一致,但是<==>优先级低于==,<=!=>优先级低于!=。
3) Expr1==>Expr2或者Expr2<==Expr1.推理操作符,对于Expr1==>Expr2表达式为真当且仅当Expr1==false或者Expr1==true&&Expr2==true。
4) 变量引用操作符,\nothing表示空集;\everything表示全集。一般在\assignable句子中使用。
3.方法规格
核心部分为:前置条件、后置条件和副作用约定。
1)前置条件
前置条件作用是确保调用的东西是符合要求的。通过requires P;语句表现。如果方法规格中需要多个前提,可以同时满足多个requires子句;或逻辑为requires P1|| P2.
2)后置条件
后置条件保证方法执行后返回值是符合要求的。通过ensures P;语句表现。使用方法与requires类似。
3)副作用范围限定
表明具体可能会修改的对象。通过assignable或者modifiable实现。
4.类型规格
课程中讲解两类:不变式限制和约束限制。
1)不变式(invariant)
语法为:invariant P;不变式是概括对象状态正确性的核心,也是形式化方法的核心概念。如果不满足不变式要求,对象的任何方法执行结果可能无效。
2)状态变化约束(constraint)
语法为:constraint P;constraint是概括对象状态变化正确性的核心。
3)针对不变式的检查(repOK)
语法为:c.repOK()<==>invariant(c),用于检查对象表示状态是否有效。在是实现类时,repOK应该与不变式在所有方法前实现。
应用工具链情况
目前我只用过OpenJML和SMT Solver,JMLUnitNG暂时没有使用。
OpenJML:用来检查JML规格是否存在问题。
SMT Solver:用来检查代码是否满足规格要求。
JMLUnitNG:相关数据生成的代码生成。
部署JML UnintNG
样例代码
1 public class Main { 2 /*@ public normal_behaviour 3 @ ensures \result == lhs - rhs; 4 */ 5 public static int compare(int lhs, int rhs) { 6 return lhs - rhs; 7 } 8 9 public static void main(String[] args) { 10 compare(114514,1919810); 11 } 12 }
测试结果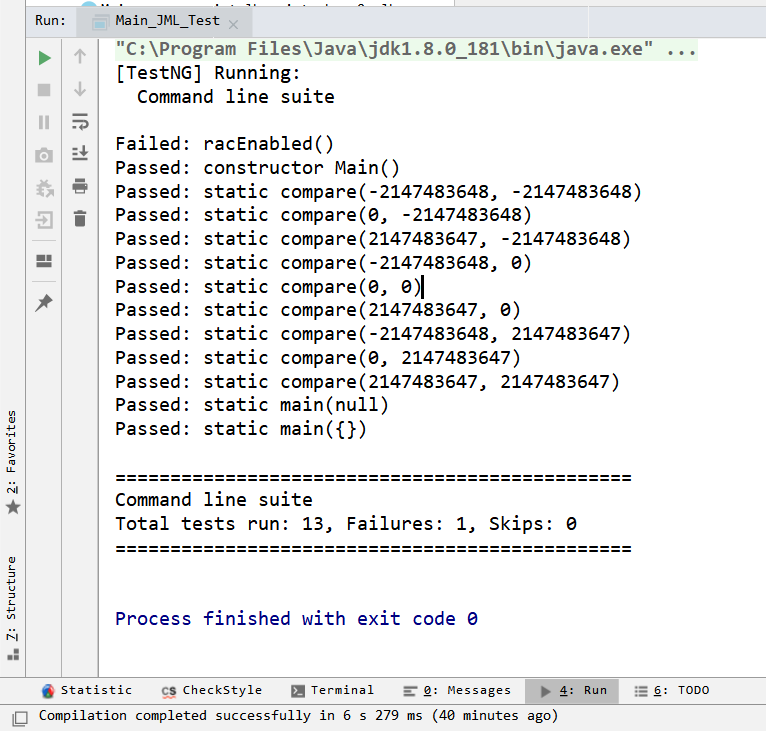
我们可以看到在这个过程中主要是对边界数据、0之间的比较,以及输入的合法性比较。
自己测试path类
所用代码:


1 import java.util.ArrayList; 2 import java.util.HashMap; 3 import java.util.Iterator; 4 5 public class Path { 6 private int[] nodeList = new int[0xffffff]; 7 private int number = 31; 8 //@ public instance model non_null int[] nodes; 9 10 public Path(int... nodeList) { 11 if (nodeList != null) { 12 for (int i = 0; i < nodeList.length; ++i) { 13 this.nodeList[i] = nodeList[i]; 14 number = (number * 17 + nodeList[i]); 15 } 16 } 17 } 18 //@ ensures \result == (nodes.length >= 2); 19 public boolean isValid() { 20 return nodeList.length >= 2; 21 } 22 //@ ensures \result == (\exists int i; 0 <= i && i < nodes.length; nodes[i] == node); 23 public boolean containsNode(int node) { 24 for (int i = 0; i < nodeList.length; ++i) { 25 if (nodeList[i] == node) { 26 return true; 27 } 28 } 29 return false; 30 } 31 32 /*@ ensures (\exists int[] arr; (\forall int i, j; 0 <= i && i < j && j < arr.length; arr[i] != arr[j]); 33 @ (\forall int i; 0 <= i && i < arr.length;this.containsNode(arr[i])) 34 @ && (\forall int node; this.containsNode(node); (\exists int j; 0 <= j && j < arr.length; arr[j] == node)) 35 @ && (\result == arr.length)); 36 @*/ 37 38 public int getDistinctNodeCount() { 39 int[] temp = new int[0xffffff]; 40 for (int i = 0; i < nodeList.length; ++i) { 41 int j; 42 for (j = 0; j < temp.length; ++j) { 43 if (temp[j] == nodeList[i]) { 44 break; 45 } 46 } 47 if (j == temp.length) { 48 temp[temp.length] = nodeList[i]; 49 } 50 } 51 return temp.length; 52 } 53 54 /*@ requires index >= 0 && index < size(); 55 @ assignable \nothing; 56 @ ensures \result == nodes[index]; 57 @*/ 58 59 public /*@pure@*/int getNode(int index) { 60 return nodeList[index]; 61 } 62 63 //@ ensures \result == nodes.length; 64 public /*@pure@*/ int size() { 65 return nodeList.length; 66 } 67 68 public int compareTo(Path o) { 69 int i; 70 if (o != null) { 71 for (i = 0; i < size() && i < o.size(); ++i) { 72 int nodeOne = getNode(i); 73 int nodeTwo = o.getNode(i); 74 if (nodeOne > nodeTwo) { 75 return 1; 76 } else if (nodeOne == nodeTwo) { 77 continue; 78 } else { 79 return -1; 80 } 81 } 82 if (i == size() && i == o.size()) { 83 return 0; 84 } else if (i == size() && i < o.size()) { 85 return -1; 86 } else { 87 return 1; 88 } 89 } 90 return 1; 91 } 92 93 /*@ also 94 @ public normal_behavior 95 @ requires obj != null && obj instanceof Path; 96 @ assignable \nothing; 97 @ ensures \result == (((Path) obj).nodes.length == nodes.length) && 98 @ (\forall int i; 0 <= i && i < nodes.length; nodes[i] == ((Path) obj).nodes[i]); 99 @ also 100 @ public normal_behavior 101 @ requires obj == null || !(obj instanceof Path); 102 @ assignable \nothing; 103 @ ensures \result == false; 104 @*/ 105 106 @Override 107 public boolean equals(Object obj) { 108 if (obj == null) { 109 return false; 110 } else if (!(obj instanceof Path)) { 111 return false; 112 } else { 113 Path path = (Path) obj; 114 if (hashCode() != path.hashCode()) { 115 return false; 116 } 117 if (path.size() != size()) { 118 return false; 119 } 120 for (int i = 0; i < size(); ++i) { 121 if (nodeList[i] != path.getNode(i)) { 122 return false; 123 } 124 } 125 return true; 126 } 127 } 128 129 130 @Override 131 public int hashCode() { 132 return number; 133 } 134 }
测试结果
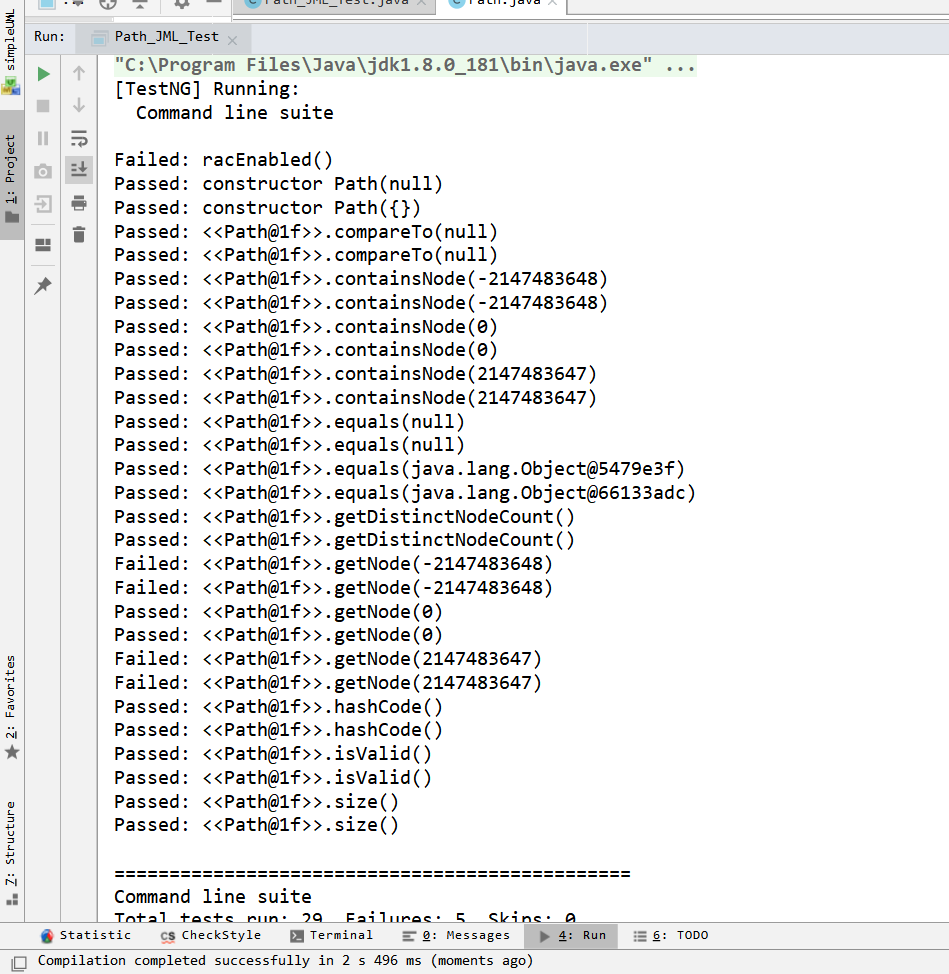
由于测试过程中不知道为什么规格采用数组类型,我用Arraylist他会识别不到,因此只好改成数组类型。与上述例子类似,我们可以看到它在进行测试过程中主要是进行边界测试,比如输入空path程序如何处理,与null的比较得出的数据,是否包含最大最小节点,当然,我觉得getNode它的做法不太合适,因为规格中已经说明前提是下标在0-node.size()之间,我没有开最大数组,对于下标不在范围内的情况也没有考虑,只是按照规格方式写。但是它进行检测的方式还是比较全面的。
架构设计
Project9:
本次作业是jml系列第一次作业,普遍按照规格目的直接实现,没有额外的类别。由于CPU时间的限制,因此不能选取复杂度较高的Arraylist结构莽完全部。需要将计算部分尽可能分摊到各部分,降低复杂度。
本来在MyPath和MyPathcontainer里面全部均采取哈希结构,但是哈希迭代器中并不清楚列举的顺序,担心在path路径生成时内部节点序列被打乱,因此MyPath类中采取Arraylist和HashMap结合的方式。MyPathContainer类中采用两个HashMap相互映射,便于删除。类图如下:

由于并不清楚日后的需求变更,因此没有进行封装节点等做法,架构感觉没有体现出来。但作为对象,我们进行对MyPath类的equal方法和CompareTo方法的改写。以及因为使用Path作为键值,需要对Path的hashCode方法进行改写。
Project10:
jml系列第二次作业,在MyPathContainer基础上进行扩展,对节点之间进行操作。上一次作业基础上增加图结构,全局节点图和最短路径图。由于全局图的出现,因此第一次作业中记录不同节点的hashMap结构取消使用。开始的想法是对图的操作都放在一个单例模式的图结构中,进行增删改查的操作,与MyGraph结构只有数值交互操作,由于当时没有理解清楚这点要求,于是采取单例模式。

MyGraph类中包含了PathContainer中的所有方法,这方面除了删除上一次作业中对不同节点采用HashMap方式记录的结构以外没有对原来的结构进行改变。增加图后在增加路径和删除路径中都需要对图结构进行更改,并且删除之前最短路径的缓存。最短路径采用广度遍历的方式,由于这次作业图权值均为1,因此第一次找到终点节点便是最短路径,降低复杂度。实践证明,使用dijkstra算法也不会超时。
Progect11:
本次作业在第十次作业上继续扩展,从图结构扩展为类似地铁路线图的结构。当然,由于一条路径中存在可重复节点,因此并不完全相同。本次作业需求量加大,但是需求比较相似,最开始的想法是先以构造邻接矩阵的形式一个图的基础类,然后进行继承扩充。
经过思考,我发现最短路径图和最少换乘图类似,最低票价图和最小不满意度图类似,因此我在构造的时候基础图是RailwayGraph和PriceGraph两类,TransGraph继承RailwayGraph,实际上我并没有对此结构进行改写;这类图中具体存放的是邻接矩阵图和最短路径/最少换乘图,自认为直接在结构中就进行对对象的增删改查操作比较合适,因此数据均由RailwaySystem传入,在基础图中进行更改,RailwaySystem中仅进行数据交流。ContentGraph继承PriceGraph,在权值计算时初始化的权值不同,因此改写addConstant和nextTolength方法。由于思路复杂,在此结构中采取多个数据,节点序列:包括节点序号和所在路径;节点序列的邻接矩阵;初始图和加权图;路径和编号构成的图。
对于最短路径和最少换乘的图构造是比较简单的,套用的是第二次jml作业的GraphMap结构,此时发现使用单例模式并不正确,因为有继承需求,因此改写第二次的图结构,重新构造为RailwayGraph。由于评测前采用拆点方法,拆点思路过于复杂,为每两个不同节点(节点序号不同或者节点序号相同路径不同)建立联系,图十分庞大写起来还很辛苦。优化方面,主要是对dijkstra算法进行优化,采用堆排序使得一次使用该算法的时间复杂度为nlog(n)。由于堆排序中需要更改加入的结构,因此新建立Edge类,专门将终点节点和两点间距离作为整体存储,该类在其余地方没有使用。
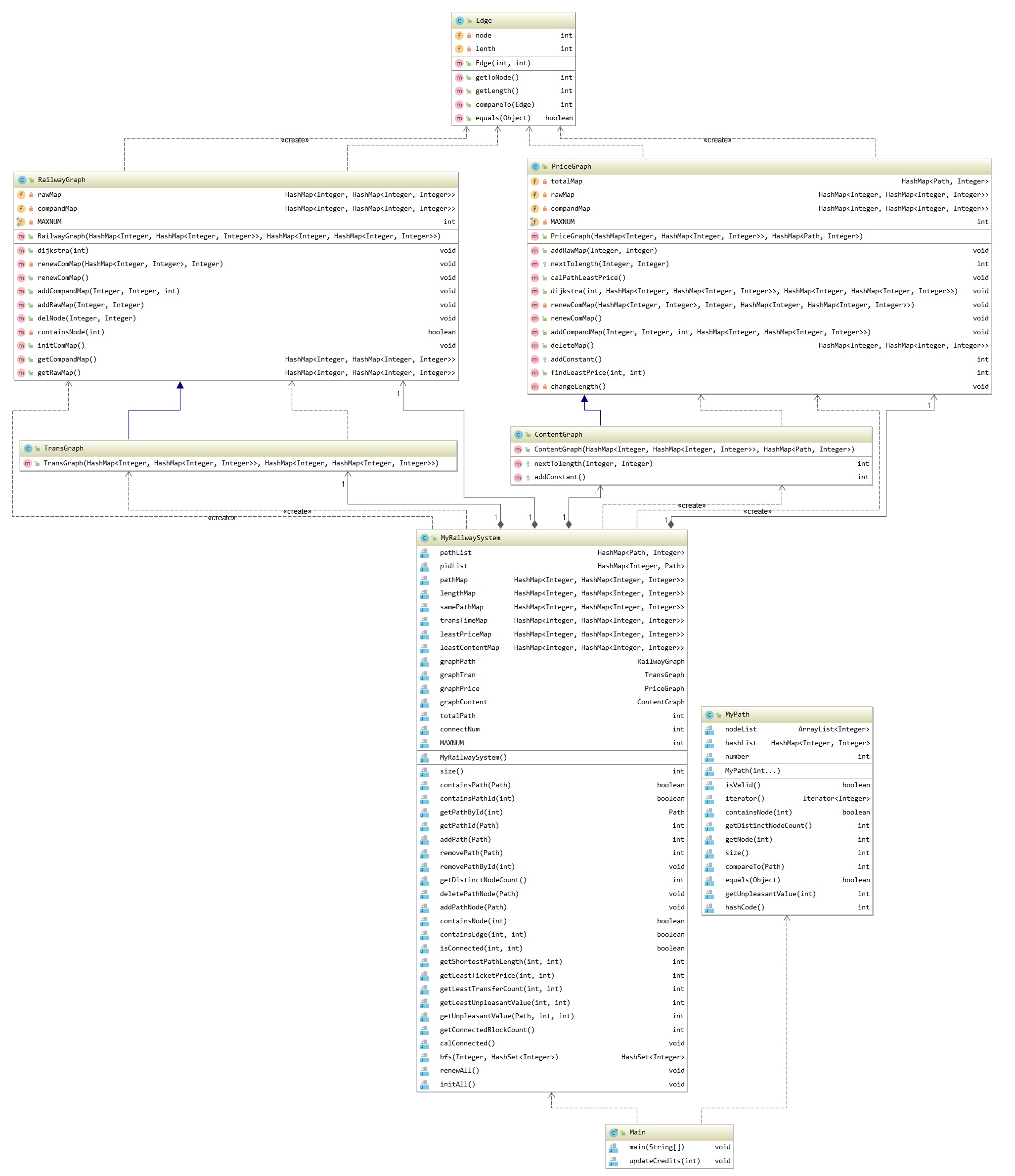
总体概括:
三次作业逐级递进,本来应该是一个在架构方面很好的锻炼机会,开始以为自己写的很有逻辑,但从path->pathContainer->Graph->RailwaySystem的过程中,我发现,最后所有的功能都在RailwaySystem中实现,即自己视野不够开阔,没有很好地做到高内聚低耦合的思想。
BUG&修复
不论是强测还是平时的bug,我觉得都有必要总结一下~
jml第一次作业
在紧急从Arraylist转变为HashMap后,舍友出现输入两条节点完全相同路径会重新添加的情况。我们发现如果没有改写HashMap键值的hashCode的话且不是已有的对象类型,如String、Integer等(对应有自己计算hashcode的方式),那么比较的便是对象的地址。我们知道重新开空间new对象地址肯定是不一样的,因此出现bug。
jml第二次作业
由于初期采用dijkstra算法以及卑微的数据结构基础,在写最短路径过程中不断翻车,bug连连,主要问题是初始化和更新数据方面,由于初期初始化采取在邻接图中存在便加入的思路,后期更新时比较麻烦,不按正常思路走,需要考虑三种情况,已在新构建的最短路径图中或者在之前邻接图中或是中间节点问题。思路较为复杂,还是贴上第三次常规的dijkstra算法好了。
1 public void dijkstra(int fromNode) { 2 HashSet<Integer> visitMap = new HashSet<>(); 3 HashMap<Integer, Integer> tempLen = new HashMap<>(); 4 Iterator iterator = rawMap.entrySet().iterator(); 5 while (iterator.hasNext()) { 6 Map.Entry entry = (Map.Entry) iterator.next(); 7 Integer node = (Integer) entry.getKey(); 8 tempLen.put(node, MAXNUM); 9 } 10 Queue<Edge> queue = new PriorityQueue<>(); 11 Edge nowEdge = new Edge(fromNode, 0); 12 queue.add(nowEdge); 13 tempLen.put(fromNode, 0); 14 while (!queue.isEmpty()) { 15 nowEdge = queue.poll(); 16 Integer toNode = nowEdge.getToNode(); 17 Integer length = nowEdge.getLength(); 18 if (tempLen.get(toNode). 19 compareTo(length) < 0) { 20 continue; 21 } 22 if (visitMap.contains(toNode)) { 23 continue; 24 } 25 visitMap.add(toNode); 26 iterator = rawMap.entrySet().iterator(); 27 while (iterator.hasNext()) { 28 Map.Entry entry = (Map.Entry) iterator.next(); 29 Integer node = (Integer) entry.getKey(); 30 if (!visitMap.contains(node)) { 31 if (compandMap.containsKey(toNode) 32 && compandMap.get(toNode).containsKey(node)) { 33 length = compandMap.get(toNode).get(node); 34 } else { 35 length = MAXNUM; 36 } 37 Integer nowLenth = tempLen.get(toNode) + length; 38 if (nowLenth.compareTo(tempLen.get(node)) < 0) { 39 tempLen.put(node, nowLenth); 40 nowEdge = new Edge(node, nowLenth); 41 queue.add(nowEdge); 42 } 43 } 44 } 45 } 46 renewComMap(tempLen, fromNode); 47 }
更换为bfs算法后倒没出现什么bug,比较顺利。
jml第三次作业
第三次作业写得比较心塞,由于周末忙于冯如杯事情导致周一才开始写,不小心用了很复杂的算法,拆点法的迷失版。由于存在换乘需要额外的权值相加,简单粗暴地将序号相同但路径不同的节点也加入权值图中,他们之间的权值为32或2,这样在寻找的时候就可以将换乘加入。但是在寻找A-B的过程中就必须得将所有序号为A的节点都找一边,寻找最少的路径,这在存在大量换乘站的情况下复杂度是非常高的。意识到问题已是周二下午,但是对不拆点的方法当时又不太了解,强测因此fail,只通过8个点。互测前,我的程序对换乘站相当高以及不断进行查找的数据有10分钟都跑不出来的情况,大家普遍都能在规定时间跑出来,感到因算法失败的心碎。现在已修复强测+互测的bug,不过舍友被hack的数据中我依旧存在不能在规定时间内跑出来的数据,说明我的程序行走在刀尖上,不够稳定。
在互测前我曾出现过一个bug。
1 pathMap = new HashMap<>(); 2 lengthMap = new HashMap<>(); 3 graphPath = new RailwayGraph(pathMap, lengthMap); 4 samePathMap = new HashMap<>(); 5 transTimeMap = new HashMap<>(); 6 graphTran = new TransGraph(samePathMap, transTimeMap); 7 leastPriceMap = new HashMap<>(); 8 graphPrice = new PriceGraph(leastPriceMap, pathList); 9 leastContentMap = new HashMap<>(); 10 graphContent = new ContentGraph(leastContentMap, pathList);
这是我RailwaySystem中的数据,我以为将后续HashMap结构传入后如transTimeMap,在TransGraph中改变后相应在RailwaySystem也会有相应变化,因此我并在TransGraph类中本来有这种方法,后面被我删了。
1 public HashMap<Integer, HashMap<Integer, Integer>> getCompandMap() { 2 return compandMap; 3 }
自信满满删除后出现bug:原因是方法参数传递中对值传递和引用传递理解不深入。常规思路,值传递是int、long等基本数据类型,如果我们是引用类型,自然会改变引用对象的值,因为是在该地址上进行的改变。理论上是这样的。但由于我在自己类中出现这种操作:
1 public void initComMap() { 2 compandMap = new HashMap<>(); 3 }
当我让变量释放、重新申请空间时,再次对copandMap操作,RailwaySystem中相应的传入变量transTimeMap并没有改变,停留在transTimeMap = new HashMap的状态,之后取元素便会抛异常。
因此我们在参数为引用数据类型的时候应当小心,如果调用函数中对该参数进行释放&重新赋地址操作,传入的参数和日后改变的对象就不会是同一个参数了,望三思。
心得体会
本期作业是规格层面上的代码实现,在第一次和第二次作业中,将需求直译为代码还是比较容易的。这时对撰写规格方要求较高,需求简单但不能出错,遗漏相应的前置或者后置条件都有可能造成程序错误。老师谈道,真正优秀的团队是能够很好处理异常情况的团队。第三次作业对实现方要求比较高,即程序员能力。当然,第三次作业让我见识了如何将最少换乘、最低票价和最少不满意度的规格写出来。我觉得这几个规格真的很难写,理解起来也不容易。课上使用openjml对自己所写规格检查,从一堆error到0error真不容易。整个阶段下来,我觉得写规格并不是写过程,具体实现并不用指出,重点是得到的结果。复杂的规格应该采取拆分的方式,构造中间变量是一个比较合适的办法。
jml规格的使用目前对我而言最直接的好处便是需求明朗,无二义性,在一定程度上能够提高写代码的速度,减少走弯路的概率。
当然,我感觉自己对规格的理解还很浅层,目前所写代码也很难体现处规格的明显优势。但我感觉提前写好规格能让自己先想想应该做什么,而不是拍案上手写代码,将需求理解清楚能减少重构的可能性。(虽然感觉自己每次都在重构)不过本期作业完成后,我发现自己对继承有更深的理解,感觉提高了代码的复用程度。看到标程的时候,我觉得自己的代码风格和代码能力真的有待提高,标程高内聚低耦合以及对数据结构的灵活运用都是值得我学习的地方。标程的代码长度普遍不到200行,自己的类仍存在300+行的情况,深深感到能力的缺陷,除了努力别无他法。