神经网络都干了些什么?
分类的理解:
首先我们需要了解一下,分类的过程究竟干了些什么?
一个数据,m维features,最后给这个数组一个类别class,其中class的数目是远远小于features的数目的。
从这个角度来说,分类过程就是提炼或者成为简化features的过程。
从这个角度再看神经网络:
input_layer --> NN -->output_layer,输入N个数据,输出K个类别,那么NN都干了些什么?
我们知道NN就是在训练W,W为(input_dim, output_dim),也可以写成(feature_dim,class_dim),其中feature_dim>>class_dim,也就是啥NN干的就是提纯features的活,说提纯也是不准确,最后是为了提纯,但是过程中可能会稀释,多层NN就是不断伸缩变换features的过程,每一层神经元的个数就是当前层features的数目。
需要提出的是我们输入的都是低级的靠近物理的features,NN会不断的高级化抽象化features。在这里手工特征工程不再重要,这是非常令人振奋人心的。
再次提醒一下:W是features和features的map。我们把W看成features的权重,我们每次喂给NN的是features,千万不要混淆。
神经网络实现:
求∂L/∂w1,∂L/∂w2:
∂L/∂w2使用公式1,∂L/∂w1使用公式1和反向传递的误差
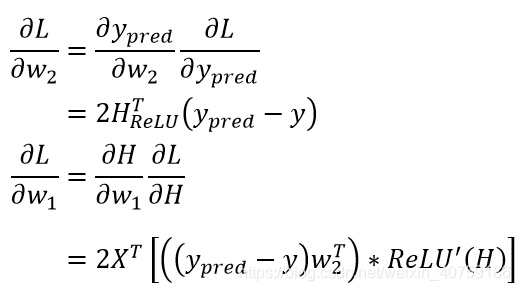
实现代码:
class NaiveNN:
def __init__(self, ws=None):
self._ws = ws
@staticmethod
def relu(x):
return np.maximum(0,x)
# hidden_dim is the hidden units m
def fit(self, x, y, hidden_dim=4, lr=1e-3, epoch=1000):
input_dim, output_dim = x.shape[1], y.shape[1]
if self._ws is None:
self._ws = [
np.random.random([input_dim, hidden_dim]),
np.random.random([hidden_dim, output_dim])]
losses = []
for _ in range(epoch):
# forward pass
h = x.dot(self._ws[0])
h_relu = NaiveNN.relu(h)
y_pred = h_relu.dot(self._ws[1])
# np.linalg.norm(求范数)
losses.append(np.linalg.norm(y_pred-y,ord="fro"))
# backford pass
# ∂L/∂y_pred
d1 = 2*(y_pred-y)
# ∂L/∂w2 = ∂y_pred/∂w2* ∂L/∂y_pred
# ∂y_pred/∂w2= h_relu.T
dw2 = h_relu.T.dot(d1)
# ∂L/∂w2 = ∂H/∂w2* ∂L/∂H
# ∂L/∂H = ∂L/∂y_pred * w2^T * relu'
dw1 = x.T.dot(d1.dot(self._ws[1].T)*(h_relu != 0))
# uodate w
self._ws[0] -= lr*dw1
self._ws[1] -= lr*dw2
return losses
def predict(self,x):
h = x.dot(self._ws[0])
h_relu = NaiveNN.relu(h)
y_pred = h_relu.dot(self._ws[1])
return np.argmax(y_pred, axis=1)
测试代码:
x, y = gen_five_clusters()
label = np.argmax(y, axis=1)
nn = NaiveNN()
losses = nn.fit(x, y, 32, 1e-5)
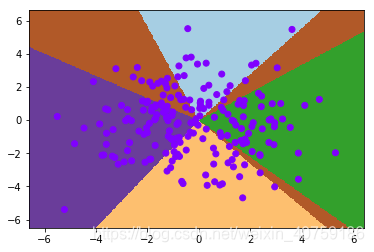
visualize2d(nn, x, label, draw_background=True)
print("准确率:{:8.6} %".format((nn.predict(x) == label).mean() * 100))
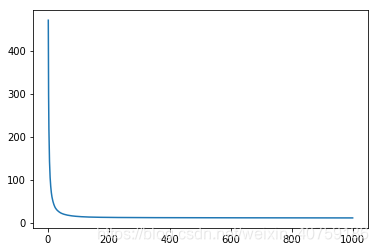
plt.figure()
plt.plot(np.arange(1, len(losses)+1), losses)
plt.show()