在上一章的伪分布式集群搭建中,我们使用start-dfs.sh脚本启动了集群环境,并且上传了一个文件到HDFS上,还使用了mapreduce程序对HDFS上的这个文件进行了单词统计。今天我们就来简单了解一下启动脚本的相关内容和HDFS的一些重要的默认配置属性。
一、启动脚本
hadoop的脚本/指令目录,就两个,一个是bin/,一个是sbin/。现在,就来看看几个比较重要的脚本/指令。
1、sbin/start-all.sh
# Start all hadoop daemons. Run this on master node.
# 开启所有的hadoop守护进程,在主节点上运行
echo "This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh"
#这个脚本已经被弃用,使用start-dfs.sh和start-yarn.sh替代
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh
#运行libexe/hadoop-config.sh指令,加载配置文件
# start hdfs daemons if hdfs is present
if [ -f "${HADOOP_HDFS_HOME}"/sbin/start-dfs.sh ]; then
"${HADOOP_HDFS_HOME}"/sbin/start-dfs.sh --config $HADOOP_CONF_DIR
#运行 sbin/start-dfs.sh指令
fi
# start yarn daemons if yarn is present
if [ -f "${HADOOP_YARN_HOME}"/sbin/start-yarn.sh ]; then
"${HADOOP_YARN_HOME}"/sbin/start-yarn.sh --config $HADOOP_CONF_DIR
#运行 sbin/start-yarn.sh指令
fi我们可以看到,这个脚本的内容不多,实际上被弃用了,只不过是在这个start-all.sh脚本中,先执行hadoop-config.sh指令加载hadoop的一些环境变量,然后再分别执行start-dfs.sh脚本和start-yarn.sh脚本。
从此可以看出,我们也可以直接执行start-dfs.sh脚本来启动hadoop集群,无需执行start-all.sh脚本而已。(如果配置了yarn,再执行start-yarn.sh脚本)。
2、libexec/hadoop-config.sh
this="${BASH_SOURCE-$0}"
common_bin=$(cd -P -- "$(dirname -- "$this")" && pwd -P)
script="$(basename -- "$this")"
this="$common_bin/$script"
[ -f "$common_bin/hadoop-layout.sh" ] && . "$common_bin/hadoop-layout.sh"
HADOOP_COMMON_DIR=${HADOOP_COMMON_DIR:-"share/hadoop/common"}
HADOOP_COMMON_LIB_JARS_DIR=${HADOOP_COMMON_LIB_JARS_DIR:-"share/hadoop/common/lib"}
HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_COMMON_LIB_NATIVE_DIR:-"lib/native"}
HDFS_DIR=${HDFS_DIR:-"share/hadoop/hdfs"}
HDFS_LIB_JARS_DIR=${HDFS_LIB_JARS_DIR:-"share/hadoop/hdfs/lib"}
YARN_DIR=${YARN_DIR:-"share/hadoop/yarn"}
YARN_LIB_JARS_DIR=${YARN_LIB_JARS_DIR:-"share/hadoop/yarn/lib"}
MAPRED_DIR=${MAPRED_DIR:-"share/hadoop/mapreduce"}
MAPRED_LIB_JARS_DIR=${MAPRED_LIB_JARS_DIR:-"share/hadoop/mapreduce/lib"}
# the root of the Hadoop installation
# See HADOOP-6255 for directory structure layout
HADOOP_DEFAULT_PREFIX=$(cd -P -- "$common_bin"/.. && pwd -P)
HADOOP_PREFIX=${HADOOP_PREFIX:-$HADOOP_DEFAULT_PREFIX}
export HADOOP_PREFIX
............................
...........省略细节,看重点..............
....................................
# 调用 hadoop-env.sh加载其他环境变量
if [ -f "${HADOOP_CONF_DIR}/hadoop-env.sh" ]; then
. "${HADOOP_CONF_DIR}/hadoop-env.sh"
fi这个脚本的作用,其实就是配置了一些hadoop集群的所需要的环境变量而已,内部还执行了hadoop-env.sh脚本,加载其他的比较重要的环境变量,如jdk等等
3、sbin/start-dfs.sh
# Start hadoop dfs daemons. #开启HDFS的相关守护线程
# Optinally upgrade or rollback dfs state. #可选升级或回滚DFS状态
# Run this on master node. #在主节点上运行这个脚本
#这是start-dfs.sh的用法 单独启动一个clusterId
usage="Usage: start-dfs.sh [-upgrade|-rollback] [other options such as -clusterId]"
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
#使用hdfs-config.sh加载环境变量
. $HADOOP_LIBEXEC_DIR/hdfs-config.sh
# get arguments
if [[ $# -ge 1 ]]; then
startOpt="$1"
shift
case "$startOpt" in
-upgrade)
nameStartOpt="$startOpt"
;;
-rollback)
dataStartOpt="$startOpt"
;;
*)
echo $usage
exit 1
;;
esac
fi
#Add other possible options
nameStartOpt="$nameStartOpt $@"
#---------------------------------------------------------
# namenodes
NAMENODES=$($HADOOP_PREFIX/bin/hdfs getconf -namenodes)
echo "Starting namenodes on [$NAMENODES]"
#执行hadoop-daemons.sh 调用bin/hdfs指令 启动namenode守护线程
"$HADOOP_PREFIX/sbin/hadoop-daemons.sh" \
--config "$HADOOP_CONF_DIR" \
--hostnames "$NAMENODES" \
--script "$bin/hdfs" start namenode $nameStartOpt
#---------------------------------------------------------
# datanodes (using default slaves file)
if [ -n "$HADOOP_SECURE_DN_USER" ]; then
echo \
"Attempting to start secure cluster, skipping datanodes. " \
"Run start-secure-dns.sh as root to complete startup."
else
#执行hadoop-daemons.sh 调用bin/hdfs指令 启动datanode守护线程
"$HADOOP_PREFIX/sbin/hadoop-daemons.sh" \
--config "$HADOOP_CONF_DIR" \
--script "$bin/hdfs" start datanode $dataStartOpt
fi
#---------------------------------------------------------
# secondary namenodes (if any)
SECONDARY_NAMENODES=$($HADOOP_PREFIX/bin/hdfs getconf -secondarynamenodes 2>/dev/null)
if [ -n "$SECONDARY_NAMENODES" ]; then
echo "Starting secondary namenodes [$SECONDARY_NAMENODES]"
#执行hadoop-daemons.sh 调用bin/hdfs指令 启动secondarynamenode守护线程
"$HADOOP_PREFIX/sbin/hadoop-daemons.sh" \
--config "$HADOOP_CONF_DIR" \
--hostnames "$SECONDARY_NAMENODES" \
--script "$bin/hdfs" start secondarynamenode
fi
...................................
............省略细节.................
...................................
# eof在start-dfs.sh脚本中,先执行hdfs-config.sh脚本加载环境变量,然后通过hadoop-daemons.sh脚本又调用bin/hdfs指令来分别开启namenode、datanode以及secondarynamenode等守护进程。
如此我们也能发现,其实直接执行hadoop-daemons.sh脚本,配合其用法,也应该可以启动HDFS等相关守护进程。
4、sbin/hadoop-daemons.sh
# 在所有的从节点上运行hadoop指令
# Run a Hadoop command on all slave hosts.
#hadoop-daemons.sh脚本的用法,
usage="Usage: hadoop-daemons.sh [--config confdir] [--hosts hostlistfile] [start|stop] command args..."
# if no args specified, show usage
if [ $# -le 1 ]; then
echo $usage
exit 1
fi
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
#调用hadoop-config.sh加载环境比那里
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh
#调用sbin/slaves.sh脚本 加载配置文件,然后使用hadoop-daemon.sh脚本读取配置文件
exec "$bin/slaves.sh" --config $HADOOP_CONF_DIR cd "$HADOOP_PREFIX" \; "$bin/hadoop-daemon.sh" --config $HADOOP_CONF_DIR "$@"
参考hadoop-daemons.sh的使用方法,不难发现直接使用hadoop-daemons.sh脚本,然后配合指令,就可以启动相关守护线程,如:
hadoop-daemons.sh start namenode #启动主节点
hadoop-daemons.sh start datanode #启动从节点
hadoop-daemons.sh start secondarynamenode #启动第二主节点
在这个脚本中,我们可以看到内部执行了slaves.sh脚本读取环境变量,然后再调用了hadoop-daemon.sh脚本读取相关配置信息并执行了hadoop指令。
5、sbin/slaves.sh
# Run a shell command on all slave hosts.
#
# Environment Variables
#
# HADOOP_SLAVES File naming remote hosts.
# Default is ${HADOOP_CONF_DIR}/slaves.
# HADOOP_CONF_DIR Alternate conf dir. Default is ${HADOOP_PREFIX}/conf.
# HADOOP_SLAVE_SLEEP Seconds to sleep between spawning remote commands.
# HADOOP_SSH_OPTS Options passed to ssh when running remote commands.
##
# 使用方法
usage="Usage: slaves.sh [--config confdir] command..."
# if no args specified, show usage
if [ $# -le 0 ]; then
echo $usage
exit 1
fi
bin=`dirname "${BASH_SOURCE-$0}"`
bin=`cd "$bin"; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh #读取环境变量
if [ -f "${HADOOP_CONF_DIR}/hadoop-env.sh" ]; then
. "${HADOOP_CONF_DIR}/hadoop-env.sh" #读取环境变量
fi
# Where to start the script, see hadoop-config.sh
# (it set up the variables based on command line options)
if [ "$HADOOP_SLAVE_NAMES" != '' ] ; then
SLAVE_NAMES=$HADOOP_SLAVE_NAMES
else
SLAVE_FILE=${HADOOP_SLAVES:-${HADOOP_CONF_DIR}/slaves}
SLAVE_NAMES=$(cat "$SLAVE_FILE" | sed 's/#.*$//;/^$/d')
fi
# start the daemons
for slave in $SLAVE_NAMES ; do
ssh $HADOOP_SSH_OPTS $slave $"${@// /\\ }" \
2>&1 | sed "s/^/$slave: /" &
if [ "$HADOOP_SLAVE_SLEEP" != "" ]; then
sleep $HADOOP_SLAVE_SLEEP
fi
done这个脚本也就是加载环境变量,然后通过ssh连接从节点。
6、sbin/hadoop-daemon.sh
#!/usr/bin/env bash
# Runs a Hadoop command as a daemon. 以守护进程的形式运行hadoop命令
.....................
.....................、
# 使用方法 command就是hadoop指令,下面有判读
usage="Usage: hadoop-daemon.sh [--config <conf-dir>] [--hosts hostlistfile] [--script script] (start|stop) <hadoop-command> <args...>"
.....................
.....................
#使用hadoop-config.sh加载环境变量
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hadoop-config.sh
#使用hadoop-env.sh加载环境变量
if [ -f "${HADOOP_CONF_DIR}/hadoop-env.sh" ]; then
. "${HADOOP_CONF_DIR}/hadoop-env.sh"
fi
.....................
.....................
case $startStop in
(start)
[ -w "$HADOOP_PID_DIR" ] || mkdir -p "$HADOOP_PID_DIR"
if [ -f $pid ]; then
if kill -0 `cat $pid` > /dev/null 2>&1; then
echo $command running as process `cat $pid`. Stop it first.
exit 1
fi
fi
if [ "$HADOOP_MASTER" != "" ]; then
echo rsync from $HADOOP_MASTER
rsync -a -e ssh --delete --exclude=.svn --exclude='logs/*' --exclude='contrib/hod/logs/*' $HADOOP_MASTER/ "$HADOOP_PREFIX"
fi
hadoop_rotate_log $log
echo starting $command, logging to $log
cd "$HADOOP_PREFIX"
#判断command是什么指令,然后调用bin/hdfs指令 读取配置文件,执行相关指令
case $command in
namenode|secondarynamenode|datanode|journalnode|dfs|dfsadmin|fsck|balancer|zkfc)
if [ -z "$HADOOP_HDFS_HOME" ]; then
hdfsScript="$HADOOP_PREFIX"/bin/hdfs
else
hdfsScript="$HADOOP_HDFS_HOME"/bin/hdfs
fi
nohup nice -n $HADOOP_NICENESS $hdfsScript --config $HADOOP_CONF_DIR $command "$@" > "$log" 2>&1 < /dev/null &
;;
(*)
nohup nice -n $HADOOP_NICENESS $hadoopScript --config $HADOOP_CONF_DIR $command "$@" > "$log" 2>&1 < /dev/null &
;;
esac
........................
........................
esac
在hadoop-daemon.sh脚本中,同样读取了环境变量,然后依据传入的参数$@(上一个脚本中)来判断要启动的hadoop的守护线程($command),最后调用bin/hdfs指令 读取配置信息 并启动hadoop的守护线程。
7、bin/hdfs
这是一个指令,而非shell脚本。我们可以发现,在启动hadoop集群时,不管使用什么脚本,最终都指向了bin/hdfs这个指令,那么这个指令里到底是什么呢,我们来看一下,就明白了。
bin=`which $0`
bin=`dirname ${bin}`
bin=`cd "$bin" > /dev/null; pwd`
DEFAULT_LIBEXEC_DIR="$bin"/../libexec
HADOOP_LIBEXEC_DIR=${HADOOP_LIBEXEC_DIR:-$DEFAULT_LIBEXEC_DIR}
. $HADOOP_LIBEXEC_DIR/hdfs-config.sh
#除了上面继续加载环境变化外,这个函数其实就是提示我们在使用什么
#比如namenode -format 是格式化DFS filesystem
#再比如 namenode 说的是运行一个DFS namenode
# 我们往下看
function print_usage(){
echo "Usage: hdfs [--config confdir] [--loglevel loglevel] COMMAND"
echo " where COMMAND is one of:"
echo " dfs run a filesystem command on the file systems supported in Hadoop."
echo " classpath prints the classpath"
echo " namenode -format format the DFS filesystem"
echo " secondarynamenode run the DFS secondary namenode"
echo " namenode run the DFS namenode"
echo " journalnode run the DFS journalnode"
echo " zkfc run the ZK Failover Controller daemon"
echo " datanode run a DFS datanode"
echo " dfsadmin run a DFS admin client"
echo " haadmin run a DFS HA admin client"
echo " fsck run a DFS filesystem checking utility"
echo " balancer run a cluster balancing utility"
echo " jmxget get JMX exported values from NameNode or DataNode."
echo " mover run a utility to move block replicas across"
echo " storage types"
echo " oiv apply the offline fsimage viewer to an fsimage"
echo " oiv_legacy apply the offline fsimage viewer to an legacy fsimage"
echo " oev apply the offline edits viewer to an edits file"
echo " fetchdt fetch a delegation token from the NameNode"
echo " getconf get config values from configuration"
echo " groups get the groups which users belong to"
echo " snapshotDiff diff two snapshots of a directory or diff the"
echo " current directory contents with a snapshot"
echo " lsSnapshottableDir list all snapshottable dirs owned by the current user"
echo " Use -help to see options"
echo " portmap run a portmap service"
echo " nfs3 run an NFS version 3 gateway"
echo " cacheadmin configure the HDFS cache"
echo " crypto configure HDFS encryption zones"
echo " storagepolicies list/get/set block storage policies"
echo " version print the version"
echo ""
echo "Most commands print help when invoked w/o parameters."
# There are also debug commands, but they don't show up in this listing.
}
if [ $# = 0 ]; then
print_usage
exit
fi
COMMAND=$1
shift
case $COMMAND in
# usage flags
--help|-help|-h)
print_usage
exit
;;
esac
# Determine if we're starting a secure datanode, and if so, redefine appropriate variables
if [ "$COMMAND" == "datanode" ] && [ "$EUID" -eq 0 ] && [ -n "$HADOOP_SECURE_DN_USER" ]; then
if [ -n "$JSVC_HOME" ]; then
if [ -n "$HADOOP_SECURE_DN_PID_DIR" ]; then
HADOOP_PID_DIR=$HADOOP_SECURE_DN_PID_DIR
fi
if [ -n "$HADOOP_SECURE_DN_LOG_DIR" ]; then
HADOOP_LOG_DIR=$HADOOP_SECURE_DN_LOG_DIR
HADOOP_OPTS="$HADOOP_OPTS -Dhadoop.log.dir=$HADOOP_LOG_DIR"
fi
HADOOP_IDENT_STRING=$HADOOP_SECURE_DN_USER
HADOOP_OPTS="$HADOOP_OPTS -Dhadoop.id.str=$HADOOP_IDENT_STRING"
starting_secure_dn="true"
else
echo "It looks like you're trying to start a secure DN, but \$JSVC_HOME"\
"isn't set. Falling back to starting insecure DN."
fi
fi
# Determine if we're starting a privileged NFS daemon, and if so, redefine appropriate variables
if [ "$COMMAND" == "nfs3" ] && [ "$EUID" -eq 0 ] && [ -n "$HADOOP_PRIVILEGED_NFS_USER" ]; then
if [ -n "$JSVC_HOME" ]; then
if [ -n "$HADOOP_PRIVILEGED_NFS_PID_DIR" ]; then
HADOOP_PID_DIR=$HADOOP_PRIVILEGED_NFS_PID_DIR
fi
if [ -n "$HADOOP_PRIVILEGED_NFS_LOG_DIR" ]; then
HADOOP_LOG_DIR=$HADOOP_PRIVILEGED_NFS_LOG_DIR
HADOOP_OPTS="$HADOOP_OPTS -Dhadoop.log.dir=$HADOOP_LOG_DIR"
fi
HADOOP_IDENT_STRING=$HADOOP_PRIVILEGED_NFS_USER
HADOOP_OPTS="$HADOOP_OPTS -Dhadoop.id.str=$HADOOP_IDENT_STRING"
starting_privileged_nfs="true"
else
echo "It looks like you're trying to start a privileged NFS server, but"\
"\$JSVC_HOME isn't set. Falling back to starting unprivileged NFS server."
fi
fi
# 停停停,对就是这
# 我们可以看到,通过相应的hadoop指令,在加载相应的class文件
# 然后在jvm运行此程序。别忘记了,hadoop是用java语言开发的
if [ "$COMMAND" = "namenode" ] ; then
CLASS='org.apache.hadoop.hdfs.server.namenode.NameNode' #namenode守护线程对应的CLASS字节码
HADOOP_OPTS="$HADOOP_OPTS $HADOOP_NAMENODE_OPTS"
elif [ "$COMMAND" = "zkfc" ] ; then
CLASS='org.apache.hadoop.hdfs.tools.DFSZKFailoverController'
HADOOP_OPTS="$HADOOP_OPTS $HADOOP_ZKFC_OPTS"
elif [ "$COMMAND" = "secondarynamenode" ] ; then
CLASS='org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode' #SecondaryNameNode守护线程对应的CLASS字节码
HADOOP_OPTS="$HADOOP_OPTS $HADOOP_SECONDARYNAMENODE_OPTS"
elif [ "$COMMAND" = "datanode" ] ; then
CLASS='org.apache.hadoop.hdfs.server.datanode.DataNode' #DataNode守护线程对应的CLASS字节码
if [ "$starting_secure_dn" = "true" ]; then
HADOOP_OPTS="$HADOOP_OPTS -jvm server $HADOOP_DATANODE_OPTS"
else
HADOOP_OPTS="$HADOOP_OPTS -server $HADOOP_DATANODE_OPTS"
fi
elif [ "$COMMAND" = "journalnode" ] ; then
CLASS='org.apache.hadoop.hdfs.qjournal.server.JournalNode'
HADOOP_OPTS="$HADOOP_OPTS $HADOOP_JOURNALNODE_OPTS"
.......................................
...............省略很多..............
.......................................
# Check to see if we should start a secure datanode
if [ "$starting_secure_dn" = "true" ]; then
if [ "$HADOOP_PID_DIR" = "" ]; then
HADOOP_SECURE_DN_PID="/tmp/hadoop_secure_dn.pid"
else
HADOOP_SECURE_DN_PID="$HADOOP_PID_DIR/hadoop_secure_dn.pid"
fi
JSVC=$JSVC_HOME/jsvc
if [ ! -f $JSVC ]; then
echo "JSVC_HOME is not set correctly so jsvc cannot be found. jsvc is required to run secure datanodes. "
echo "Please download and install jsvc from http://archive.apache.org/dist/commons/daemon/binaries/ "\
"and set JSVC_HOME to the directory containing the jsvc binary."
exit
fi
if [[ ! $JSVC_OUTFILE ]]; then
JSVC_OUTFILE="$HADOOP_LOG_DIR/jsvc.out"
fi
if [[ ! $JSVC_ERRFILE ]]; then
JSVC_ERRFILE="$HADOOP_LOG_DIR/jsvc.err"
fi
#运行 java字节码文件
exec "$JSVC" \
-Dproc_$COMMAND -outfile "$JSVC_OUTFILE" \
-errfile "$JSVC_ERRFILE" \
-pidfile "$HADOOP_SECURE_DN_PID" \
-nodetach \
-user "$HADOOP_SECURE_DN_USER" \
-cp "$CLASSPATH" \
$JAVA_HEAP_MAX $HADOOP_OPTS \
org.apache.hadoop.hdfs.server.datanode.SecureDataNodeStarter "$@"
elif [ "$starting_privileged_nfs" = "true" ] ; then
if [ "$HADOOP_PID_DIR" = "" ]; then
HADOOP_PRIVILEGED_NFS_PID="/tmp/hadoop_privileged_nfs3.pid"
else
HADOOP_PRIVILEGED_NFS_PID="$HADOOP_PID_DIR/hadoop_privileged_nfs3.pid"
fi
JSVC=$JSVC_HOME/jsvc
if [ ! -f $JSVC ]; then
echo "JSVC_HOME is not set correctly so jsvc cannot be found. jsvc is required to run privileged NFS gateways. "
echo "Please download and install jsvc from http://archive.apache.org/dist/commons/daemon/binaries/ "\
"and set JSVC_HOME to the directory containing the jsvc binary."
exit
fi
if [[ ! $JSVC_OUTFILE ]]; then
JSVC_OUTFILE="$HADOOP_LOG_DIR/nfs3_jsvc.out"
fi
if [[ ! $JSVC_ERRFILE ]]; then
JSVC_ERRFILE="$HADOOP_LOG_DIR/nfs3_jsvc.err"
fi
#运行 java字节码文件
exec "$JSVC" \
-Dproc_$COMMAND -outfile "$JSVC_OUTFILE" \
-errfile "$JSVC_ERRFILE" \
-pidfile "$HADOOP_PRIVILEGED_NFS_PID" \
-nodetach \
-user "$HADOOP_PRIVILEGED_NFS_USER" \
-cp "$CLASSPATH" \
$JAVA_HEAP_MAX $HADOOP_OPTS \
org.apache.hadoop.hdfs.nfs.nfs3.PrivilegedNfsGatewayStarter "$@"
else
#运行 java字节码文件
# run it
exec "$JAVA" -Dproc_$COMMAND $JAVA_HEAP_MAX $HADOOP_OPTS $CLASS "$@"
fi
看完懂了吗?在这个指令中,加载了各个守护线程对应的CLASS字节码文件,然后在JVM上来运行相应的守护线程。
hadoop的另一个指令bin/hadoop,内部也调用了bin/hdfs指令,感兴趣的话,可以自己看看,我就不展示出来了。至于跟yarn有关的脚本和指令也是相同的逻辑关系,我也不一一展示了。
使用图片重写整理了一下启动脚本的执行先后顺序:
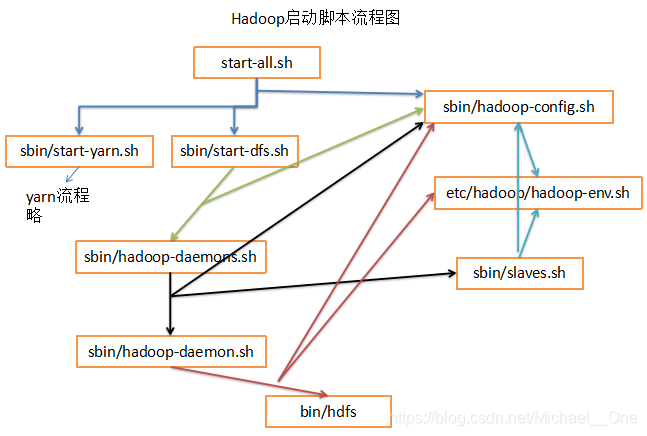
使用文字再次整理一下:
#一个脚本启动所有线程
start-all.sh #执行此脚本可以启动所有线程
1. hadoop-config.sh
a. hadoop-env.sh
2. start-dfs.sh #执行此脚本可以启动HDFS相关线程
a.hadoop-config.sh
b.hadoop-daemons.sh hdfs namenode
hadoop-daemons.sh hdfs datanode
hadoop-daemons.sh hdfs secondarynamenode
3. start-yarn.sh #执行此脚本可以启动YARN相关线程#启动单个线程
#方法1:
hadoop-daemons.sh --config [start|stop] command
1. hadoop-config.sh
a. hadoop-env.sh
2. slaves.sh
a. hadoop-config.sh
b. hadoop-env.sh
3. hadoop-daemon.sh --config [start|stop] command
a.hdfs $command
#方法2:
hadoop-daemon.sh --config [start|stop] command
1. hadoop-config.sh
a. hadoop-env.sh
2. hdfs $command
二、底层源码查看
我们通过捋顺启动脚本发现,启动namenode对应的字节码文件是:org.apache.hadoop.hdfs.server.namenode.NameNode。启动datanode对应的字节码文件是:org.apache.hadoop.hdfs.server.datanode.DataNode。而启动secondarynamenode对应的字节码文件是:org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode。
这些源码所在的har包:hadoop-hdfs-2.7.3-sources.jar
1、namenode的源码
package org.apache.hadoop.hdfs.server.namenode;
.......................
import org.apache.hadoop.hdfs.HdfsConfiguration;
..........................
@InterfaceAudience.Private
public class NameNode implements NameNodeStatusMXBean {
static{ //静态块
HdfsConfiguration.init(); //调用HdfsConfiguration的init方法,进行读取配置文件
}
...................
public static void main(String argv[]) throws Exception {
if (DFSUtil.parseHelpArgument(argv, NameNode.USAGE, System.out, true)) {
System.exit(0);
}
try {
StringUtils.startupShutdownMessage(NameNode.class, argv, LOG);
NameNode namenode = createNameNode(argv, null); //创建namenode
if (namenode != null) {
namenode.join(); //启动namenode线程
}
} catch (Throwable e) {
LOG.error("Failed to start namenode.", e);
terminate(1, e);
}
}
...........
}看一下HdfsConfiguration类
package org.apache.hadoop.hdfs;
/**
* Adds deprecated keys into the configuration.
*/
@InterfaceAudience.Private
public class HdfsConfiguration extends Configuration {
static { //静态块
addDeprecatedKeys();
// adds the default resources
Configuration.addDefaultResource("hdfs-default.xml"); //取默认配置文件
Configuration.addDefaultResource("hdfs-site.xml"); //读取个人设置文件
}
public static void init() {}
private static void addDeprecatedKeys() {}
public static void main(String[] args) {
init();
Configuration.dumpDeprecatedKeys();
}
}2、datanode源码
package org.apache.hadoop.hdfs.server.datanode;
..............
import org.apache.hadoop.hdfs.HdfsConfiguration;
..............
@InterfaceAudience.Private
public class DataNode extends ReconfigurableBase
implements InterDatanodeProtocol, ClientDatanodeProtocol,
TraceAdminProtocol, DataNodeMXBean {
public static final Log LOG = LogFactory.getLog(DataNode.class);
static{
HdfsConfiguration.init(); //同样在静态块中调用了HdfsConfiguration类,用于加载配置文件
}
}---------------------------------------如有疑问,敬请留言------------------------------------------