机器学习实战专辑part1——Logistic回归@[适合初学小白超详细!]
作为一个学习过java的热爱代码的研究生也是未来的程序媛,学习python觉得颇为开心,但是一路走来只有自己知道自己的艰辛和不易,从一个小白走到今天不知道入了多少坑走了多少弯路,所以,想把自己曾经不懂还有考虑到超级小白可能不懂得地方都尽力解释得详细且清楚,帮助大家的同时也为自己做好复习笔记,以便不时之需。如有不懂,欢迎提问,如有不对,欢迎指正!
1.Logistic回归基本概念
回归:假设现在有一些数据点,我们用一条直线对这些点进行拟合(该线称为最佳拟合直线),这个拟合过程就称为回归。
线性回归:线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。其表达形式为y = w’x+e,e为误差服从均值为0的正态分布。简单说,就是自变量和因变量之间是线性关系。参数计算方法一般是最小二乘法。
Logistic回归:直接将线性回归的模型扣到Logistic回归中,会造成方程二边取值区间不同和普遍的非直线关系。所以,才引入Logistic回归。Logistic回归实质即发生概率除以没有发生概率再取对数。也就是通过Sigmoid函数将任何连续的数值映射到[0,1]之间。参数计算方法一般是梯度下降法。
举个栗子:借用吴恩达老师讲的癌症的例子

如果我们用线性回归来预测癌症的话,可以想象对于这种分类问题,线性回归很难找到一个完美拟合数据的模型,而且一些特别的数据,也就是噪音会对它的准确率产生很大的影响。

在新加一组数据之后,方程的准确率降低了很多很多,所以线性回归更适合用来预测数据,对于这种分类问题还是需要Logistic回归来解决。
Sigmoid函数:
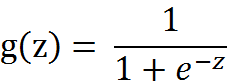
其中: z = w0x0+w1x1+….+wnxn,w为参数, x为特征
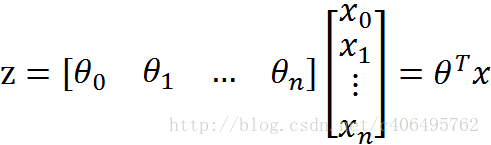
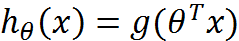
Sigmoid函数的工作原理就是它总能把任意的输入x转变成一个在[0,1]区间的值,有助于我们对输出进行分类,任何属于[0.5,1]的归为1,任何属于[0,0.5]的归为0。
cost function:
在线性回归中,我们的代价函数是根据最小化观察值和估计值的差平方和来计算。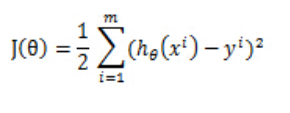
但是对于logistic回归,我们的cost fucntion不能最小化观察值和估计值的差平法和,因为这样我们会发现J(θ)为非凸函数,此时就存在很多局部极值点,就无法用梯度迭代得到最终的参数。
因此我们这里重新定义一种cost function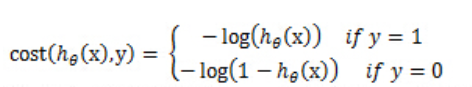
把这个式子进行合并,便可以得到我们logistic回归的代价函数: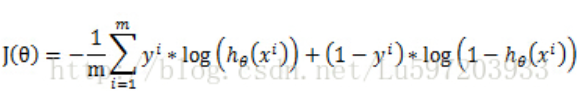
其中,m为样本的总数,y(i)表示第i个样本的类别,x(i)表示第i个样本,需要注意的是θ是多维向量,x(i)也是多维向量。
那么,现在我只要求出J(θ)的偏导,就可以利用梯度上升算法,求解J(θ)的极大值了。
2.梯度上升法
有了以上知识,接下来我们就要寻找最佳回归系数了,也即是向量w,在这里我们使用的梯度上升法。基于的思想是要找到某函数的最大值,最好的方法是沿着该函数的梯度方向探寻。该公式将一直被迭代执行,直到达到某个停止条件为止,比如迭代次数达到某个指定值或者算法达到某个可以允许的误差范围。
那么现在开始求解J(θ)对θ的偏导,求解如下(数学推导):

知道了,梯度上升迭代公式,我们就可以自己编写代码,计算最佳拟合参数了。
3.python3实战代码
https://blog.csdn.net/anneqiqi/article/details/64125186
首先,导入numpy模块,此种导入方式仅适合写小的程序。首先定义便利函数和sigmoid函数。

然后,定义我们的主角,逻辑回归算法函数。此算法用于训练我们的数据集。

此部分为画图部分,定义画图函数

紧紧连接上一张

这样我们的逻辑回归模型已经搭建完毕,接下来,只需要简单的几句测试代码,便可以达到效果。
测试代码如下: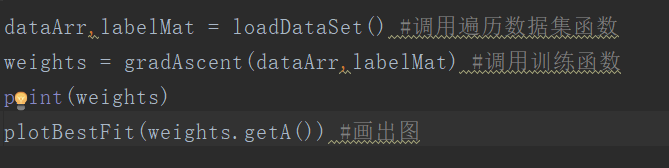
下图便是我们训练出来的结果,这条线就是拟合数据后的分割线。

拓展:梯度上升算法的改进版本
随机梯度上升算法
先上代码:
该算法第一个改进之处在于,alpha在每次迭代的时候都会调整,并且,虽然alpha会随着迭代次数不断减小,但永远不会减小到0,因为这里还存在一个常数项。必须这样做的原因是为了保证在多次迭代之后新数据仍然具有一定的影响。如果需要处理的问题是动态变化的,那么可以适当加大上述常数项,来确保新的值获得更大的回归系数。另一点值得注意的是,在降低alpha的函数中,alpha每次减少1/(j+i),其中j是迭代次数,i是样本点的下标。第二个改进的地方在于跟新回归系数(最优参数)时,只使用一个样本点,并且选择的样本点是随机的,每次迭代不使用已经用过的样本点。这样的方法,就有效地减少了计算量,并保证了回归效果。
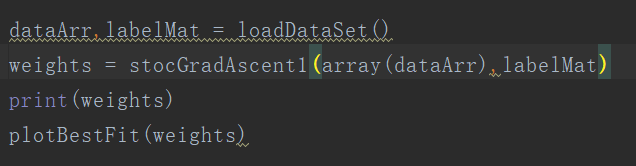
调用代码如上图,得到的结果如下图:

由于改进的随机梯度上升算法,随机选取样本点,所以每次的运行结果是不同的。但是大体趋势是一样的。我们改进的随机梯度上升算法收敛效果更好。为什么这么说呢?让我们分析一下。我们一共有100个样本点,改进的随机梯度上升算法迭代次数为150。
而且看横轴,可以看出随机梯度上升算法收敛的时间也变短了。
4.总结
Logistic回归的优缺点:
优点:实现简单,易于理解和实现;计算代价不高,速度很快,存储资源低。
缺点:容易欠拟合,分类精度可能不高。
作者:小新新
来源:CSDN
版权声明:本文为博主原创文章,转载请附上博文链接!欢迎转载!
参考文献:
[1]《机器学习实战》的第五章内容
[2] 吴恩达机器学习视频
[3]:Python中scatter函数参数详解
https://blog.csdn.net/anneqiqi/article/details/64125186