TensorFlow 入门
TensorFlow实现神经网络
通过 TensorFlow 训练神经网络模型
-
设置神经网络参数的过程就是神经网络的训练过程。只有经过有效训练的神经网络模型才可以真正地解决分类或者回归问题。
-
使用监督学习的方式设置神经网络参数需要有一个标注好的训练数据集。
-
在 Tensorflow 游乐场有两种颜色,一种黄色,一种蓝色。任意一种颜色越深,都代表判断的信心越大。
-
监督学习最重要的思想就是,在己知答案的标注数据集上,模型给出的预测结果要尽量接近真实的答案。通过调整神经网络中的参数对训练数据进行拟合,可以使得模型对未知的样本提供预测的能力。
-
在神经网络优化算法中,最常用的方法是反向传播算法(backpropagation)。
-
神经网络反向传播优化流程图
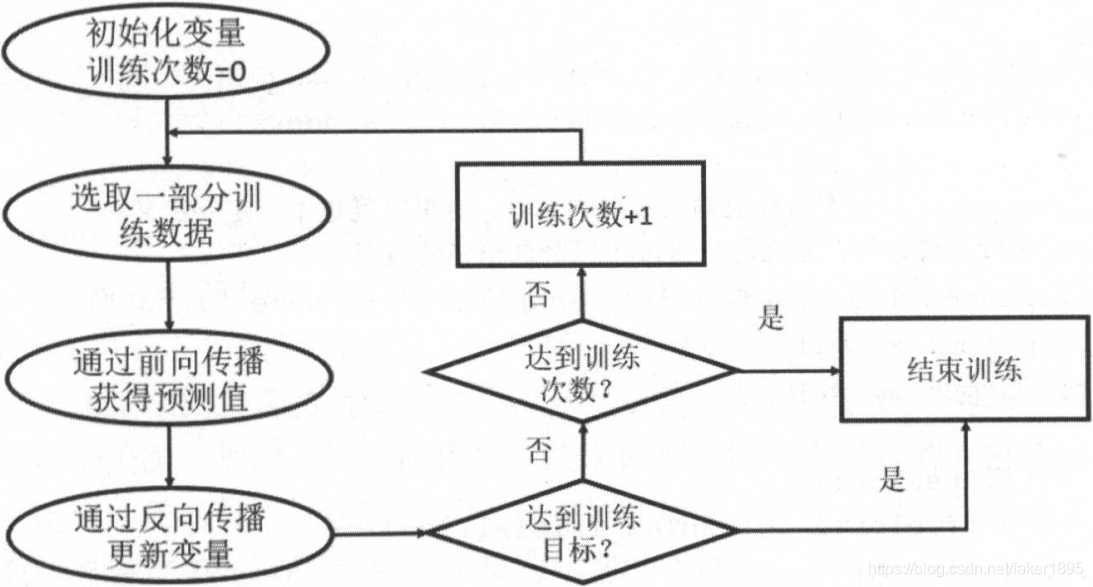
-
反向传播算法实现了 一个迭代的过程。
- 在每次迭代的开始,首先需要选取一小部分训练数据,这一小部分数据叫做一个 batch 。
- 然后,这个 batch 的样例会通过前向传播算法得到神经网络模型的预测结果。
- 因为训练数据都是有正确答案标注的,所以可以计算出当前神经网络模型的预测答案与正确答案之间的差距。
- 最后,基于预测值和真实值之间的差距,反向传播算法会相应更新神经网络参数的取值,使得在这个 batch 上神经网络模型的预测结果和真实答案更加接近。
-
通过 TensorFlow 实现反向传播算法的第一步是使用 TensorFlow 表达一个 batch 的数据。
- 如果每轮迭代中选取的数据都要通过常量来表示,那么 TensorFlow 的计算图将会太大。
- 因为每生成一个常量,TensorFlow 都会在计算图中增加一个节点。
- 一般来说, 一个神经网络的训练过程会需要经过几百万轮甚至几亿轮的迭代,这样计算图就会非常大,而且利用率很低。
- 为了避免这个问题,TensorFlow 提供了 placeholder 机制用于提供输入数据。
- placeholder 相当于定义了 一个位置,这个位置中的数据在程序运行时再指定。
- 这样在程序中就不需要生成大量常量来提供输入数据,而只需要将数据通过placeholder 传入 TensorFlow 计算图。
- 在 placeholder 定义时,这个位置上的数据类型是需要指定的。
- 和其他张量一样,placeholder 的类型也是不可以改变的。
- placeholder 中数据的维度信息可以根据提供的数据推导得出,所以不一定要给出。
-
通过 placeholder 实现前向传播算法
# 计算单个输入batch的前向传播结果。 import tensorflow as tf # 若不加seed=1,每次的输出是不一样的 w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1)) w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1)) """ 定义placeholder作为存放输入数据的地方。 这里维度也不一定要定义,但如果维度是确定的,那么给出维度可以降低出错的概率。 """ x = tf.placeholder(tf.float32, shape=(1, 2), name="input") a = tf.matmul(x, w1) y = tf.matmul(a, w2) sess = tf.Session() init_op = tf.global_variables_initializer() sess.run(init_op) """ 下面一行将报错:InvalidArgumentError (see above for traceback): You must feed a value for placeholder tensor 'input' with dtype float and shape [1,2] [[{{node input}} = Placeholder[dtype=DT_FLOAT, shape=[1,2], _device="/job:localhost/replica:0/task:0/device:GPU:0"]()]] """ # print(sess.run(y)) # 下面一行将会得到输出结果:[[ 3.95757794]] print(sess.run(y, feed_dict={x:[[0.7, 0.9]]})) -
在新的程序中计算前向传播结果时,需要提供一个 feed_dict 来指定 x 的取值。feed_dict 是一个字典(map),在字典中需要给出每个用到的 placeholder 的取值。如果某个需要的 placeholder 没有被指定取值,那么程序在运行时将会报错。
-
在训练神经网络时需要每次提供一个 batch 的训练样例。对于这样的需求,placeholder 也可以很好地支持。如果将输入的 矩阵改为 的矩阵,那么就可以得到 n 个样例的前向传播结果了。其中 的矩阵的每一行为一个样例数据。这样前向传播的结果为 的矩阵,这个矩阵的每一行就代表了一个样例的前向传播结果。
扫描二维码关注公众号,回复: 4899555 查看本文章
# 一次性计算多个样例的前向传播结果。 import tensorflow as tf # 若不加seed=1,每次的输出是不一样的 w1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1)) w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1)) """ 定义placeholder作为存放输入数据的地方。 这里维度也不一定要定义,但如果维度是确定的,那么给出维度可以降低出错的概率。 """ # 输入的维度为n*2,此处n取3 x = tf.placeholder(tf.float32, shape=(3, 2), name="input") a = tf.matmul(x, w1) y = tf.matmul(a, w2) sess = tf.Session() init_op = tf.global_variables_initializer() sess.run(init_op) feed_dict = {x:[[0.7, 0.9], [0.1, 0.4], [0.5, 0.8]]} # 因为x在定义时指定了n为3,所以在运行前向传播过程时需要提供3个样例数据。 # 下面一行将会得到输出结果:[[ 3.95757794], [ 1.15376544], [ 3.16749239]] print(sess.run(y, feed_dict)) -
在得到一个 batch 的前向传播结果之后,需要定义一个损失函数来刻画当前的预测值和真实答案之间的差距,然后通过反向传播算法来调整神经网络参数的取值,使得差距可以被缩小。
# 以下代码定义了 一个简单的损失函数,并通过TensorFlow定义了反向传播算法。 """ 使用sigmoid函数将y转换为0~ 1之间的数值。 转换后y代表预测是正样本的概率。 1-y代表预测是负样本的概率。 """ y = tf.sigmoid(y) # 定义损失函数来刻画预测值与真实值的差距。 # cross_entropy定义了真实值和预测值之间的交叉熵,这是分类问题中一个常用的损失函数。 cross_entropy = -tf.reduce_mean(y*tf.log(tf.clip_by_value(y, 1e-10, 1.0)) + (1-y)*tf.log(tf.clip_by_value(1-y, 1e-10, 1.0)) ) # 定义学习率 learning_rate = 0.001 # 定义反向传播算法来优化神经网络中的参数。 train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy) -
比较常用的优化方法有三种:
- tf.train.GradientDescentOptimizer;
- tf.train.AdamOptimizer;
- tf.train.MomentumOptimizer。
-
在定义了反向传播算法之后,通过运行 sess.run(train_ step)就可以对所有在 GraphKeys.TRAINABLE_VARIABLES 集合中的变量进行优化,使得在当前 batch 下损失函数更小。