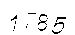继续刚才的说,刚才的pytesseract的安装目录通常都在python或者anaconda目录下的Lib\site-packages\pytesseract目录下。配置完之后就可以用了,用下面的代码就行验证码的保存和识别。
driver.save_screenshot('f://aa.png') # 截取当前网页,该网页有我们需要的验证码
imgelement = driver.find_element_by_xpath('//img[@id="myCode"]') #定位验证码
location = imgelement.location #获取验证码x,y轴坐标
size = imgelement.size #获取验证码的长宽
rangle = (int(location['x']),int(location['y']),int(location['x']+size['width']),int(location['y']+size['height'])) #写成我们需要截取的位置坐标
i = Image.open("f://aa.png") # 打开截图
frame4 = i.crop(rangle) # 使用Image的crop函数,从截图中再次截取我们需要的区域
frame4.save('f://frame4.png')
qq = Image.open('f://frame4.png')
# 图片二值化
# 模式L”为灰色图像,它的每个像素用8个bit表示,0表示黑,255表示白,其他数字表示不同的灰度。
Img = qq.convert('L')
# 自定义灰度界限,大于这个值为黑色,小于这个值为白色
threshold = 50
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
# 图片二值化
photo = Img.point(table, '1')
photo.save('f://frame5.png')
qq2 = Image.open('f://frame5.png')
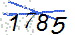
text = pytesseract.image_to_string(qq2,lang='chi_sim').strip() # 使用image_to_string识别验证码转换后的验证码图形大概是下面这样:(可以看出不太好辨认,有兴趣的可以对图形进行各种加工,多下载点验证码进行训练)