Java7 中实现的 ConcurrentHashMap 说实话还是比较复杂的,Java8 对 ConcurrentHashMap 进行了比较大的改动。建议读者可以参考 Java8 中 HashMap 相对于 Java7 HashMap 的改动,对于 ConcurrentHashMap,Java8 也引入了红黑树。
说实话,Java8 ConcurrentHashMap 源码真心不简单,最难的在于扩容,数据迁移操作不容易看懂。
我们先用一个示意图来描述下其结构:
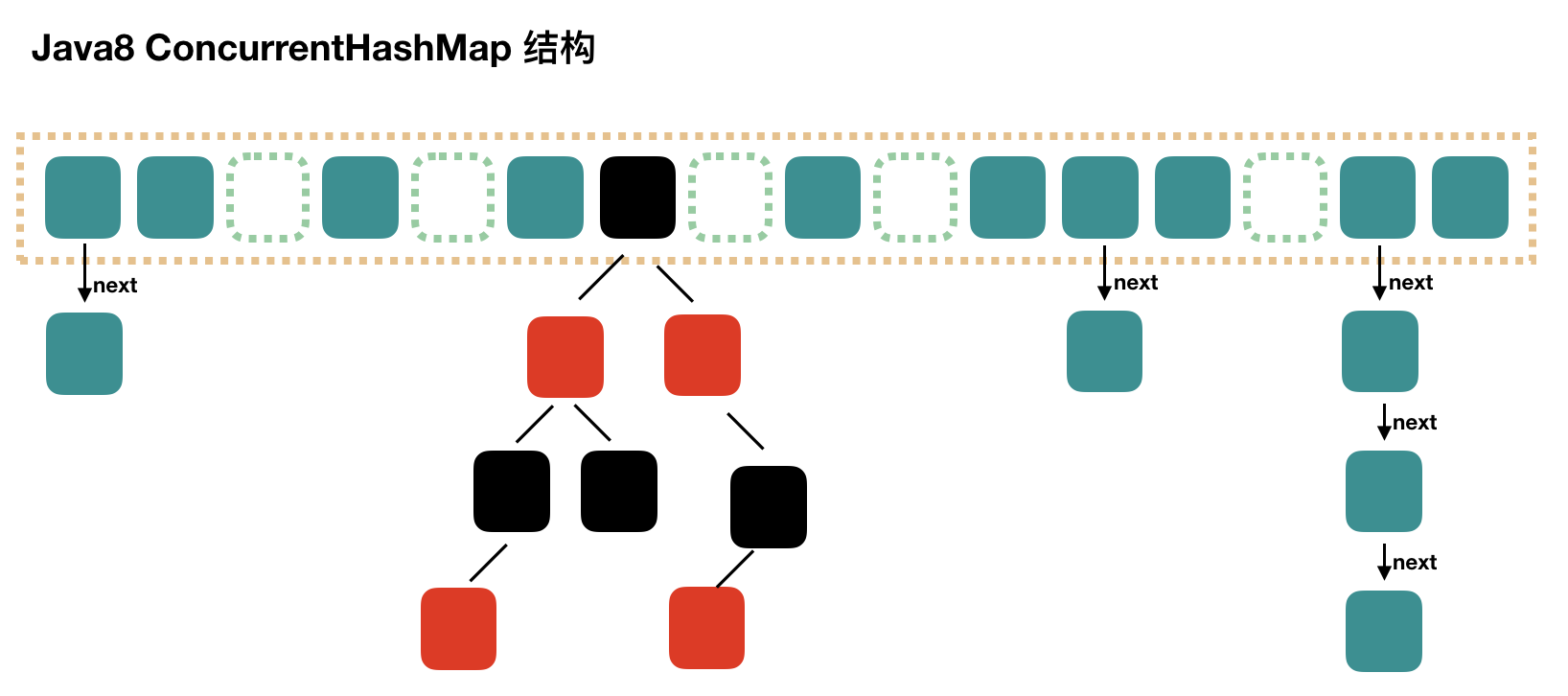
结构上和 Java8 的 HashMap 基本上一样,不过它要保证线程安全性,所以在源码上确实要复杂一些。
初始化
| 1 2 3 4 5 6 7 8 9 10 11 |
|
这个初始化方法有点意思,通过提供初始容量,计算了 sizeCtl,sizeCtl = 【 (1.5 * initialCapacity + 1),然后向上取最近的 2 的 n 次方】。如 initialCapacity 为 10,那么得到 sizeCtl 为 16,如果 initialCapacity 为 11,得到 sizeCtl 为 32。
sizeCtl 这个属性使用的场景很多,不过只要跟着文章的思路来,就不会被它搞晕了。
如果你爱折腾,也可以看下另一个有三个参数的构造方法,这里我就不说了,大部分时候,我们会使用无参构造函数进行实例化,我们也按照这个思路来进行源码分析吧。
put 过程分析
仔细地一行一行代码看下去:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
|
put 的主流程看完了,但是至少留下了几个问题,第一个是初始化,第二个是扩容,第三个是帮助数据迁移,这些我们都会在后面进行一一介绍。
初始化数组:initTable
这个比较简单,主要就是初始化一个合适大小的数组,然后会设置 sizeCtl。
初始化方法中的并发问题是通过对 sizeCtl 进行一个 CAS 操作来控制的。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
|
链表转红黑树: treeifyBin
前面我们在 put 源码分析也说过,treeifyBin 不一定就会进行红黑树转换,也可能是仅仅做数组扩容。我们还是进行源码分析吧。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
|
扩容:tryPresize
如果说 Java8 ConcurrentHashMap 的源码不简单,那么说的就是扩容操作和迁移操作。
这个方法要完完全全看懂还需要看之后的 transfer 方法,读者应该提前知道这点。
这里的扩容也是做翻倍扩容的,扩容后数组容量为原来的 2 倍。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
|
这个方法的核心在于 sizeCtl 值的操作,首先将其设置为一个负数,然后执行 transfer(tab, null),再下一个循环将 sizeCtl 加 1,并执行 transfer(tab, nt),之后可能是继续 sizeCtl 加 1,并执行 transfer(tab, nt)。
所以,可能的操作就是执行 1 次 transfer(tab, null) + 多次 transfer(tab, nt),这里怎么结束循环的需要看完 transfer 源码才清楚。
数据迁移:transfer
下面这个方法很点长,将原来的 tab 数组的元素迁移到新的 nextTab 数组中。
虽然我们之前说的 tryPresize 方法中多次调用 transfer 不涉及多线程,但是这个 transfer 方法可以在其他地方被调用,典型地,我们之前在说 put 方法的时候就说过了,请往上看 put 方法,是不是有个地方调用了 helpTransfer 方法,helpTransfer 方法会调用 transfer 方法的。
此方法支持多线程执行,外围调用此方法的时候,会保证第一个发起数据迁移的线程,nextTab 参数为 null,之后再调用此方法的时候,nextTab 不会为 null。
阅读源码之前,先要理解并发操作的机制。原数组长度为 n,所以我们有 n 个迁移任务,让每个线程每次负责一个小任务是最简单的,每做完一个任务再检测是否有其他没做完的任务,帮助迁移就可以了,而 Doug Lea 使用了一个 stride,简单理解就是步长,每个线程每次负责迁移其中的一部分,如每次迁移 16 个小任务。所以,我们就需要一个全局的调度者来安排哪个线程执行哪几个任务,这个就是属性 transferIndex 的作用。
第一个发起数据迁移的线程会将 transferIndex 指向原数组最后的位置,然后从后往前的 stride 个任务属于第一个线程,然后将 transferIndex 指向新的位置,再往前的 stride 个任务属于第二个线程,依此类推。当然,这里说的第二个线程不是真的一定指代了第二个线程,也可以是同一个线程,这个读者应该能理解吧。其实就是将一个大的迁移任务分为了一个个任务包。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 |
|
说到底,transfer 这个方法并没有实现所有的迁移任务,每次调用这个方法只实现了 transferIndex 往前 stride 个位置的迁移工作,其他的需要由外围来控制。
这个时候,再回去仔细看 tryPresize 方法可能就会更加清晰一些了。
get 过程分析
get 方法从来都是最简单的,这里也不例外:
- 计算 hash 值
- 根据 hash 值找到数组对应位置: (n – 1) & h
- 根据该位置处结点性质进行相应查找
- 如果该位置为 null,那么直接返回 null 就可以了
- 如果该位置处的节点刚好就是我们需要的,返回该节点的值即可
- 如果该位置节点的 hash 值小于 0,说明正在扩容,或者是红黑树,后面我们再介绍 find 方法
- 如果以上 3 条都不满足,那就是链表,进行遍历比对即可
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
|
简单说一句,此方法的大部分内容都很简单,只有正好碰到扩容的情况,ForwardingNode.find(int h, Object k) 稍微复杂一些,不过在了解了数据迁移的过程后,这个也就不难了,所以限于篇幅这里也不展开说了。
总结
其实也不是很难嘛,虽然没有像之前的 AQS 和线程池一样一行一行源码进行分析,但还是把所有初学者可能会糊涂的地方都进行了深入的介绍,只要是稍微有点基础的读者,应该是很容易就能看懂 HashMap 和 ConcurrentHashMap 源码了。
看源码不算是目的吧,深入地了解 Doug Lea 的设计思路,我觉得还挺有趣的,大师就是大师,代码写得真的是好啊。
我发现很多人都以为我写博客主要是源码分析,说真的,我对于源码分析没有那么大热情,主要都是为了用源码说事罢了,可能之后的文章还是会有比较多的源码分析成分,大家该怎么看就怎么看吧。
不要脸地自以为本文的质量还是挺高的,信息量比较大,如果你觉得有写得不好的地方,或者说看完本文你还是没看懂它们,那么请提出来~~~