破解有道翻译反爬虫机制
web端的有道翻译,在之前是直接可以爬的。也就是说只要获取到了他的接口,你就可以肆无忌惮的使用他的接口进行翻译而不需要支付任何费用。那么自从有道翻译推出他的API服务的时候,就对这个接口做一个反爬虫机制(如果大家都能免费使用到他的翻译接口,那他的API服务怎么赚钱)。这个反爬虫机制在爬虫领域算是一个非常经典的技术手段。那么他的反爬虫机制原理是什么?如何破解?接下来带大家一探究竟。
一、正常爬取一个网站的步骤
如果你要爬取他的翻译接口,这个流程还是不能少的。首先我们打开有道翻译的链接:http://fanyi.youdao.com/。然后在页面中右键->检查->Network项。这时候就来到了网络监听窗口,以后你在这个页面中发送的所有网络请求,都会在Network这个地方显示出来。接着我们在翻译的窗口输入我们需要翻译的文字,比如输入hello。然后点击自动翻译按钮,那么接下来在下面就可以看到浏览器给有道发送的请求,这里截个图看看:
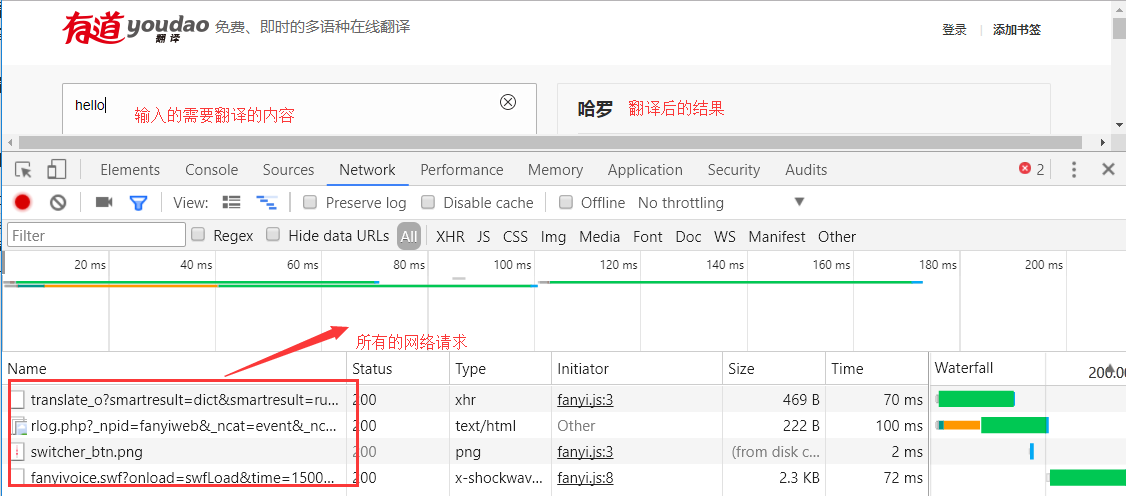
在上图,我们可以看到发送了很多的网络请求,这里我们点击第一个网络POST请求进行查看:
可以看到与一个Request URL,这个url是请求链接地址

查看服务器的回复包Response

并且,现在我们再回到Headers的地方,然后滚动到最下面,可以看到有一个Form Data的地方,这个下面展示了许多的数据,这些数据就是你在点击翻译的时候浏览器给服务器发送的数据:
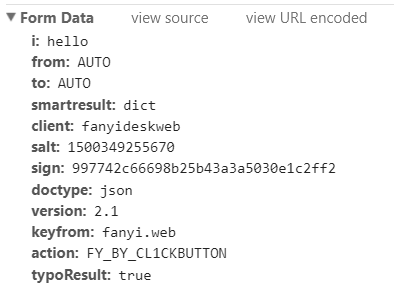

当然现在的Header 里的From Data数据内容不止这些,还多了tv等字段
对其中几个比较重要的数据进行解释:
i:需要进行翻译的字符串,这个地方我们输入的是hello。salt:加密用到的盐。这个是我们破解有道反爬虫机制的关键点。sign:签名字符串。也是破解反爬虫机制的关键点- 其他的数据类型暂时就不怎么重要了,都是固定写法,我们后面写代码的时候直接鞋子就可以了。到现在为止,我们就可以写一个简单的爬虫,去调用有道翻译的接口了。这里我们使用的网络请求库是
Python3自带的urllib,相关代码如下:
1 # 导入需要的库
2 import urllib.request
3 import urllib.parse
4 import json
5
6 # 等待用户输入需要翻译的单词
7 content = input('请输入需要翻译的单词:')
8
9 # 有道翻译的url链接
10 url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule&sessionFrom=null'
11
12 # 发送给有道服务器的数据
13 data = {}
14
15 # 需要翻译的文字
16 data['i'] = content
17 # 下面这些都先按照我们之前抓包获取到的数据
18 data['from'] = 'AUTO'
19 data['to'] = 'AUTO'
20 data['smartresult'] = 'dict'
21 data['client'] = 'fanyideskweb'
22 data['salt'] = '1500349255670'
23 data['sign'] = '997742c66698b25b43a3a5030e1c2ff2'
24 data['doctype'] = 'json'
25 data['version'] = '2.1'
26 data['keyfrom'] = 'fanyi.web'
27 data['action'] = 'FY_BY_CLICKBUTTON'
28 data['typoResult'] = 'true'
29
30 # 对数据进行编码处理
31 data = urllib.parse.urlencode(data).encode('utf-8')
32
33 # 创建一个Request对象,把url和data传进去,并且需要注意的使用的是POST请求
34 request = urllib.request.Request(url=self.url, data=data, method='POST')
35 # 打开这个请求
36 response = urllib.request.urlopen(request)
37 # 读取返回来的数据
38 result_str = response.read().decode('utf-8')
39 # 把返回来的json字符串解析成字典
40 result_dict = json.loads(result_str)
41
42 # 获取翻译结果
43 print('翻译的结果是:%s' % result_dict)
只是为了显示作用----学习基本爬虫流程。
我们运行这个文件后,当我们输入的是hello的时候,我们可以得到哈罗的这个正确的翻译结果。而当我们输入其他需要翻译的字符串的时候,比如输入i love you,那么就会得到一个错误代码{"errorCode":50}。这就奇怪了,有道词典不可能只能翻译一个英文单词吧(开始变的贪得无厌 --)。而这个,就是有道词典的反爬虫机制。接下来我们就来破解有道词典的反爬虫机制。
二、破解反爬虫机制:
我们可以多次的进行翻译,并且每次翻译后都去查看翻译的时候发送的这个网络请求,比较每次翻译时候发送的Form Data的值。我们注意到,Form Data在每次发送网络请求的时候,只有i和salt以及sign这三个是不同的,其他的数据都是一样的,这里我用hello和world两个单词翻译时候Form Data的数据进行比较: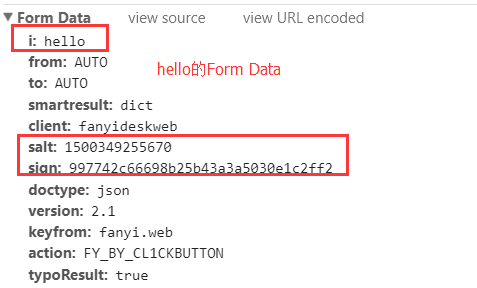
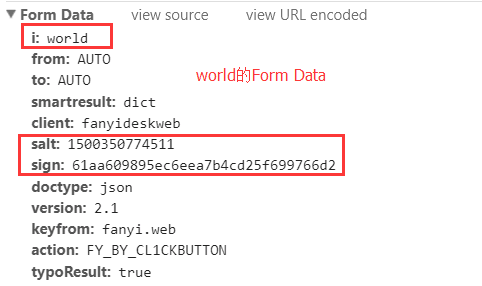
图中的Form Data也证实了我刚刚所说的,就是除了i、salt以及sign是不一样的。其余都是一样的。而i不一样是很正常的。因为i代表的是要翻译的字符串,这个不同是很正常。而salt和sign这两个东西不一样,是怎么产生的呢?这里我们可以分析一下,这两个值在每次请求的时候都不一样,只有两种情况:第一是每次翻译的时候,浏览器会从有道服务器获取一下这两个值(返回包里面是否有GET到??)。这样可以达到每次翻译的时候值不同的需求。第二是在本地,用JS代码按照一定的规则生成的。那么我们首先来看第一个情况,我们可以看到在每次发送翻译请求的时候,并没有一个请求是专门用来获取这两个值的:
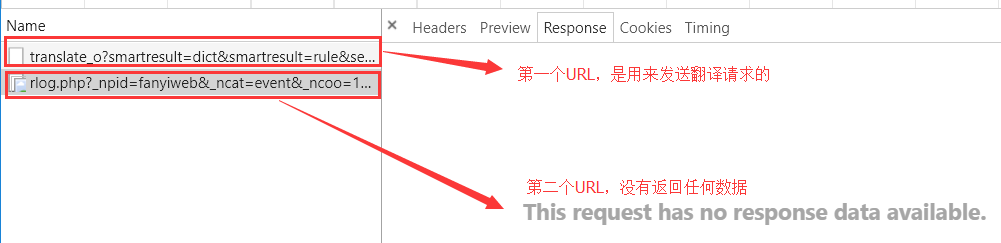
第一种情况凉凉...不慌,我们还有法二 hh
所以就可以排除第一种情况。就只剩下一种可能,那就是在本地自己生成的,如果是在本地自己生成的,那么规则是什么呢?这里我们点击网页,查看网页源代码,查找所有的JS文件,我们找到那个fanyi.js:(现在的有道代码会用各种混淆的词汇来掩饰这个js源代码,还不是为了不让你爬数据,不过认真找还是能找到的)

然后点击这个文件,跳转到这个源文件中,然后全选所有的代码,复制下来,再打开站长工具:http://tool.chinaz.com/Tools/jsformat.aspx。把代码复制进去后,点击格式化:
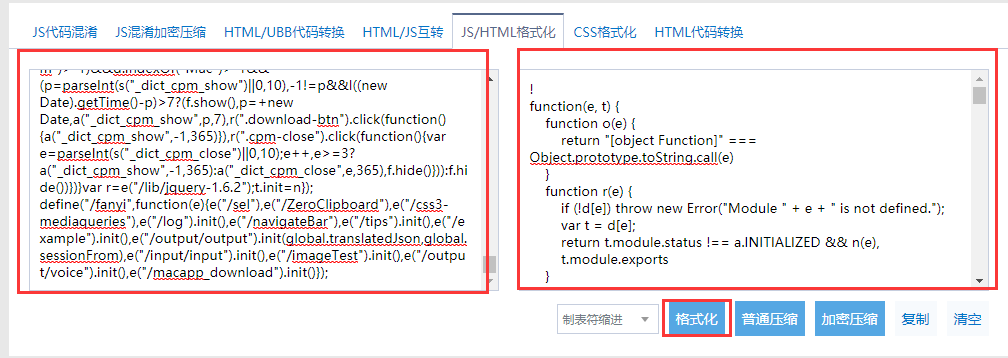
将数据拷贝到notepad++ 或 sublime,打开,然后搜索salt,可以找到相关的代码:
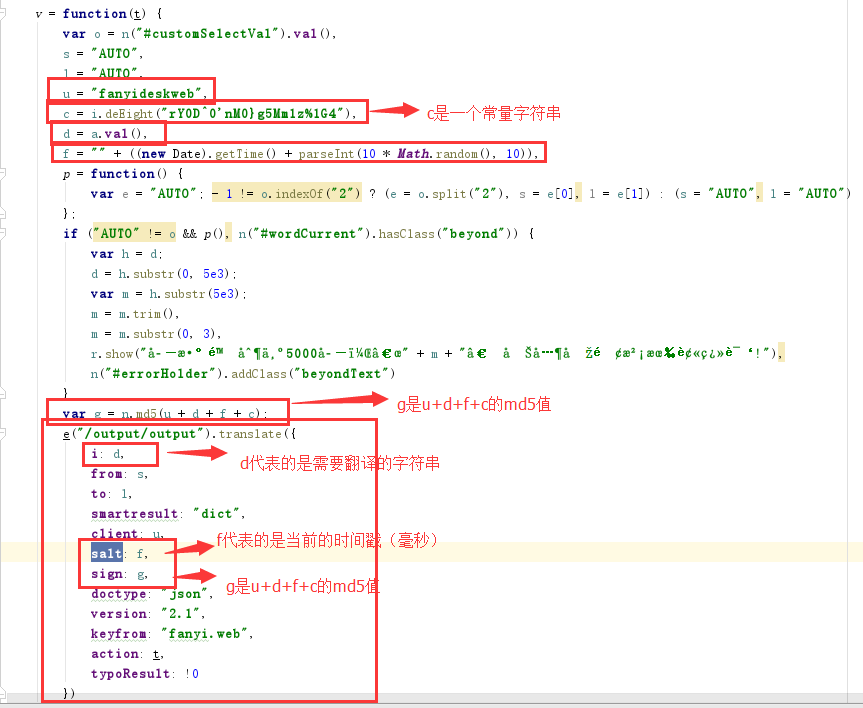
这里我们就可以发现所有的值的生成原理了。这里来做个简介:
d:代表的是需要翻译的字符串。
f:当前时间的时间戳加上0-10的随机字符串。
u:一个常量——fanyideskweb。
c:一个常量——rY0D^0'nM0}g5Mm1z%1G4。
salt:就是f变量,时间戳。
sign:使用的是u + d + f + c的md5的值。
知道salt和sign的生成原理后,我们就可以写Python代码,来对接他的接口了,以下是相关代码:
1 import urllib.request
2
3 import urllib.parse
4 import json
5 import time
6 import random
7 import hashlib
8
9 content = input('请输入需要翻译的句子:')
10
11 url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule&sessionFrom=https://www.google.com/'
12
13 data = {}
14
15 u = 'fanyideskweb'
16 d = content
17 f = str(int(time.time()*1000) + random.randint(1,10))
18 c = 'rY0D^0\'nM0}g5Mm1z%1G4'
19
20 sign = hashlib.md5((u + d + f + c).encode('utf-8')).hexdigest()
21
22 data['i'] = content
23 data['from'] = 'AUTO'
24 data['to'] = 'AUTO'
25 data['smartresult'] = 'dict'
26 data['client'] = 'fanyideskweb'
27 data['salt'] = f
28 data['sign'] = sign
29 data['doctype'] = 'json'
30 data['version'] = '2.1'
31 data['keyfrom'] = 'fanyi.web'
32 data['action'] = 'FY_BY_CLICKBUTTON'
33 data['typoResult'] = 'true'
34
35 data = urllib.parse.urlencode(data).encode('utf-8')
36 request = urllib.request.Request(url=url,data=data,method='POST')
37 response = urllib.request.urlopen(request)
38print(response.read().decode('utf-8'))
现在的js代码
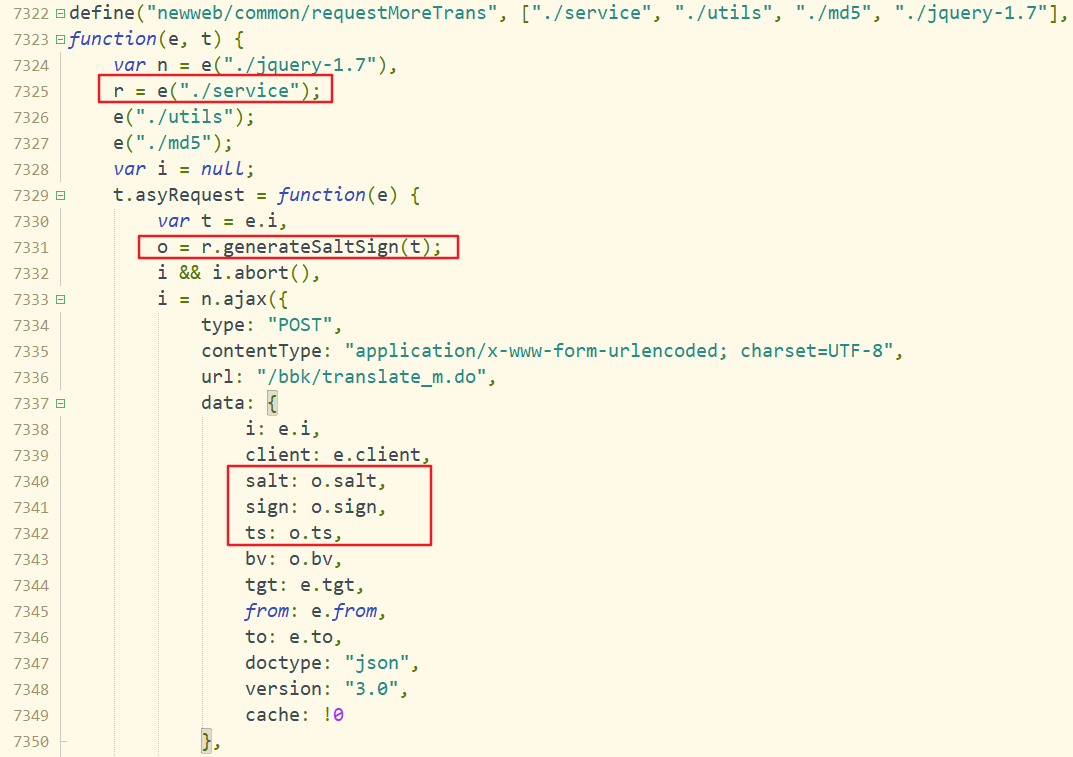
还在学习破解中...希望有大佬破解出来可以分享分享
写在最后:
像以上这种,通过用JS在本地生成随机字符串的反爬虫机制,在爬虫的时候是经常会遇到的一个问题。主要学习的是一种思路。以后再碰到这种问题的时候知道该如何解决。这样本篇文章的目的也就达到了。
另外说明一下现在的有道就连爬取一个单纯单词用这个方法都不行了 ,有道使用了更为复杂的反爬虫机制,等待学习中...
最后附上大佬的博客地址:https://blog.csdn.net/nunchakushuang/article/details/75294947