先配上官方的图,Shuffle描述着数据从map task输出到reduce task输入的这段过程。
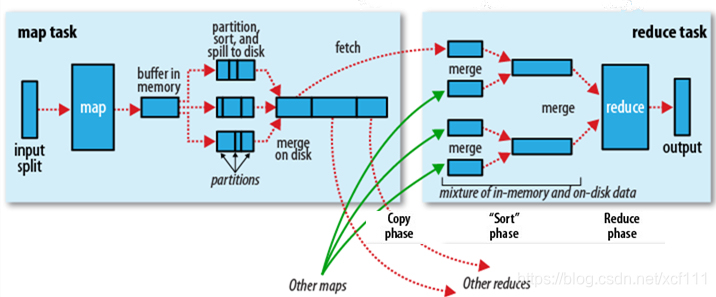
官方图这边是分成2块,我这边是有再对这2块再细分进去,再自己画了2张图。
map task

这边有个环形缓冲区,默认的大小是100M。当缓冲区使用达到80%的时候,这时候就会有个溢写的动作,溢写的比例是spill.percent,默认0.8。也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动。溢写的过程不影响map持续向环形缓冲区写入数据,毕竟还有20%的内存可以写入。
溢写前,会对环形缓冲区里80M的数据会先按照分区编号排序,然后按照键排序,如果这时候客户端有设置combiner操作,那就会执行combiner操作,减少溢写到磁盘的数据量。
每次溢写会在磁盘中生成一个溢写文件,当map task任务结束后,环形缓冲区里的所有数据也都溢写到了磁盘中,这时候就会有个归并操作,将多个溢写文件归并成一个溢写文件。
reduce task
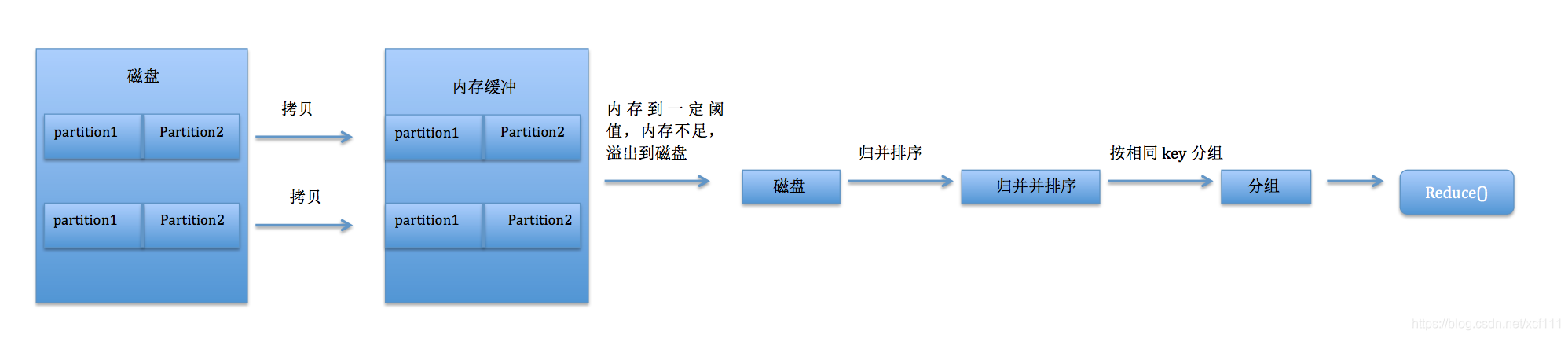 reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果。
reduce task在执行之前的工作就是不断地拉取当前job里每个map task的最终结果。
将数据放入内存缓冲区中,当内存到了一定的阈值(比如内存不足)的时候,就溢写到磁盘中。这边的溢写有3种方式:(1)内存到内存(2)内存到磁盘(3)磁盘到磁盘。使用的方式是内存到磁盘。当内存缓冲区的数据都写入到磁盘后,就启动磁盘到磁盘的方式不断归并成最终文件。最后对这个文件中的键值对按照key进行排序,排序后进行分组,分组后将整个文件交给reduce task处理。