
Shuffle本意为洗牌,HADOOP 中意为将数据进行整理(核心机制:对数据进行分区,排序,缓存)
--------------------------------------------小二上草图-----------------------------------------------------------
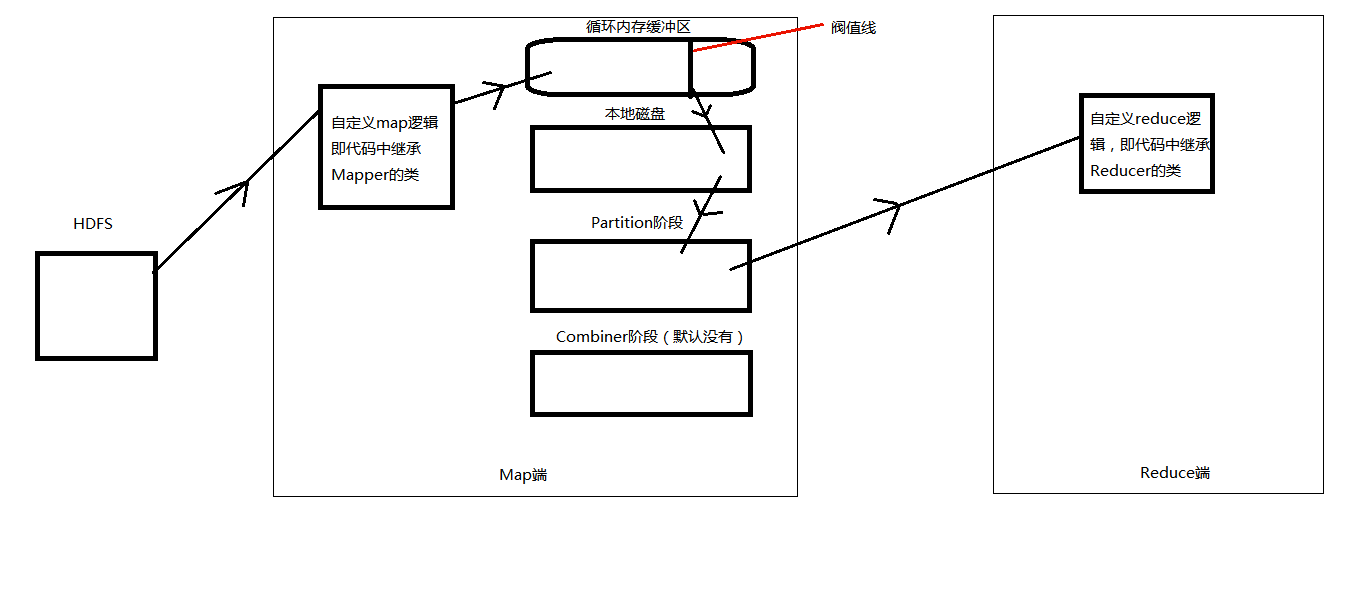
客官:此图如此之草
小二:大爷,路就是这么走,详情听我慢慢道来
客官:速度,简单,大爷以后还会来玩
小二:得嘞
---------------------------------------------二逼青年分割线-----------------------------------------------------------
(1)shuffle 的由来
通过Map端处理的数据是如何到达我们的Reduce端的,这就需要一个中间过程,这个过程就是Shuffle。
本人理解的Shuffle为从Map自定义逻辑出来到Reduce自定义逻辑之间的这个阶段为Shuffle
(2)MapReduce原理
客官:是不是跑题了
小二:大爷,没有,因为shuffle位于MapReduce中间,所以需要把握一下MapReduce原理
客官:继续
1、我们的数据存放在HDFS中,并且是按照数据块的类型存储,而我们的Map端读取数据时,并不是按照数据块的类型进行读取,而是按照逻辑片的类型进行读取,即会在数据块的基础上进行一次逻辑上的划分(默认逻辑片的大小与数据块的大小相同,这样可以避免跨数据块读取数据,减少了带宽,提高了运行效率)
2 、从HDFS中读取数据的这一过程可以称为InputFormat阶段,此过程有一个格式化的过程,默认以文本类型进行格式化(即采用FileInputFormat这个类进行,数据是按照一行一行进入到我们自定义的map逻辑中进行处理的)。
3、从Map函数出来以后就到了我们的Shuffle阶段,Map函数产生的结果不是直接写入文件的,而是先写入它的循环内存缓冲区中,当这个缓冲区中的内容达到阀值时(缓冲区的80%)才会启动后台线程将内容溢写到本地磁盘,此时Map函数还可以继续输出结果,当循环内存缓冲区中的内容写满了,Map函数就会被阻塞,直到缓冲区的内容全部写完,才会启动。
4、接着到达Partition阶段(分区阶段)上图:

5,从partition阶段出来(如果设置了Combiner阶段会进入,默认没有),reduce端就会将分区的文件进行拷贝,并在进入reduce函数前会再一次对数据的key进行规约排序,然后数据按照一组一组进入到map函数中进行我们自定义的逻辑。
6,Reduce函数出来到HDFS中这个阶段可以称为OutputFormat阶段,其中也有一个格式化的过程,默认以FileInputformat格式输出。至此我们的数据就通过MapReduce处理后结果文件存储到我们的HDFS中
(3)补充
map任务数是和我们的逻辑片数有关,有几个逻辑片就有几个map任务,而我们的reduce任务是和我们的分区数相关,有几个分区就对应几个reduce任务。