1 Hbase 的各种数据结构.
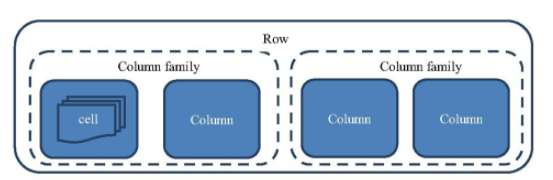
最基本的存储单位是列(column),一个列或者多个列形成一行 (row)。
传统数据库是严格的行列对齐。比如这行有三个列a、b、c, 下一行肯定也有三个列a、b、c。
而在HBase中,这一行有三个列 a、b、 c,下一个行也许是有 4 个列a、e、f、g。在HBase 中,行跟行的列可以完全不一样,这个行的数据跟另外一个行的数据也可以存储在不同的机 器上,甚至同一行内的列也可以存储在完全不同的机器上!
每个行(row)都拥有唯一的行键(row key)来标定这个行的唯一性。每个列都有多个版本,多个版本的值存储在单元格(cell)中。
若干个列又可以被归类为一个列族。
2 行键(row key)
row key 有点类似于 Mysql, Oracla 等关系型数据库中的主键, 但是又比他们简单的多.
Hbase 中的 row key 完全是由用户指定的一串不重复的字符串,没有规则, 只要不重复就行了.
row key 决定了这个 row 在 Hbase 中的存储位置.
1) 排序
HBase 中无法根据某个column来排序 系统永远是根据 rowkey 来排序的。
因此,rowkey 就是决定 row 存储顺序的唯一凭证。
而这个排序也很简单:根据字典排序。
比如,以下三个 rowkey:
row-1
row-2
row-11
根据字典排序结果:
row-1
row-11
row-2
2)检索
与 nosql 数据库们一样,RowKey 是用来检索记录的主键。
访问 HBASE table 中的行,只有三种方式:
-
通过单个RowKey访问
-
通过RowKey的range(正则)
-
全表扫描
RowKey 可以是任意字符串(最大长度是64KB,实际应用中长度一般为 10-100bytes),
在 HBASE 内部,RowKey 保存为字节数组。
存储时,数据按照 RowKey 的字典序(byte order)排序存储。
设计RowKey时,要充分排序存储这个特性,将经常一起读取的行存储放到一起。(位置相关性)
3)更新数据
如果你插入 HBase 的时候,不小心用了之前已经存在的 rowkey 呢?
那你就会把之前存在的那个row 更新掉。
之前已经存在的值呢?
会被放到这个单元格的历史记录里面,并不会丢掉,只是你需要带上版本参数才可以找到这个值。
什么是单元格(cell)呢?
一个列上可以存储多个版本的单元格。单元格就是数据存储的最小单元。
3 列族(column family)和列
在 HBase 中,若干列可以组成列族(column family)。列族是表的 schema 的一部分(而列不是),必须在使用表之前定义。列名都以列族作为前缀。例如 courses:history,courses:math都属于courses 这个列族
在 Hbase 中, 列族是一个比列更加重要的概念.
建表的时候是不需要指定列的,因为列是可变的,它非常灵活,唯一需要确定的就是列族。
这就是为什么说一个表有几个列族是一开始就定好的。
此外,表的很多属性,比如过期时间、数据块缓存以及是否压缩等都是定义在列族上,而不是定义在表上或者列上。
这一点做法跟以往的数据库有很大的区别。
同一个表里的不同列族可以有完全不同的属性配置,但是同一个列族内的所有列都会有相同的属性,因为他们都在一个列族里面,而属性都是定义在列族上的。
一个没有列族的表是没有意义的,因为列必须依赖列族而存在。
必须有了列族才能有列.
在 HBase 中一个列的名称前面总是带着它所属的列族。
列名称的规范是列族:列名,比如brother:age、brother:name、parent:age、 parent:name。
列族存在的意义:
HBase会把相同列族的列尽量放在同一台机器 上,所以说,如果想让某几个列被放到一起,你就给他们定义相同的列族。
4 单元格(Cell)
你以为行键:列族:列就能唯一地确定一个值了吗?
错!虽然列已经是 HBase 的最基本单位了,但是,一个列上可以存储多个版本的值,多 个版本的值被存储在多个单元格里面,多个版本之间用版本号(Version)来区分。
所以,唯一确定一条结果的表达式应该是行键:列族:列:版本号(rowkey:column family:column:version)。
Cell中的数据是没有类型的,全部是字节码形式存贮。
关键字:无类型、字节码
不过,版本号是可以省略的。
如果你不写版本号,HBase 默认获取最后一个版本的数据返回给你。
每个列或者单元格的值都被赋予一个时间戳。
这个时间戳默认是由系统制定的,也可以由用户显示指定。
5 Time Stamp(时间戳)
每个 Cell 都保存着同一份数据的一个版本。
版本通过时间戳来索引。时间戳的类型是 64位整型。
时间戳可以由 Habse(在数据写入时自动 )赋值,此时时间戳是精确到毫秒的当前系统时间。
时间戳也可以由客户显式赋值。如果应用程序要避免数据版本冲突,就必须自己生成具有唯一性的时间戳。
每个 cell 中,不同版本的数据按照时间倒序排序,即最新的数据排在最前面。
为了避免数据存在过多版本造成的的管理 (包括存贮和索引)负担,HBASE提供了两种数据版本回收方式。一是保存数据的最后n个版本,二是保存最近一段时间内的版本(比如最近七天)。
用户可以针对每个列族进行设置。
6 命名空间

-
Table:表,所有的表都是命名空间的成员,即表必属于某个命名空间,如果没有指定,则在 default 默认的命名空间中。
-
RegionServer group:一个命名空间包含了默认的RegionServer Group。
-
Permission:权限,命名空间能够让我们来定义访问控制列表ACL(Access Control List)。例如,创建表,读取表,删除,更新等等操作。
-
Quota:限额,可以强制一个命名空间可包含的region的数量。
命名空间其实就是类似于传统数据库中的数据库
表命名空间的作用
表命名空间主要是用于对表分组,那么我们对表分组有啥用呢?
命名空间可以填补 HBase 无法在一个实例上分库的缺憾。
通过命名空间我们可以像关系型数据库一样将表分组,对于不同的组进行不同的环境设 定,比如配额管理、安全管理等。
命名空间的一些操作
-
创建命名空间
create_namespace 'big'创建一个名字叫
big的命名空间 -
在指定的命名空间下创建表
create 'big:stu', "cf" - 显示所有命名空间
list_namespace - 列出指定命名空间下的所有的表
list_namespace_tables 'big' - 删除命名空间
drop_namespace 'big'
7 Rigion 和行的关系
之前提到了 Region 的概念,后来我们又提到了行的概念,那么他们之间的关系是什么呢?
其实很简单,一个 Region 就是多个行的集合。在 Region 中行的排序按照行键(rowkey)字典排序。