Pandas
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
>>> from pandas import Series, DataFrame
>>> import pandas as pd
A.pandas
A.1 pandas常用函数
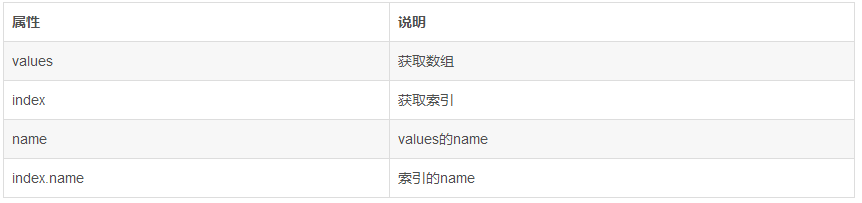
B.Series
Series可以运用ndarray或字典的几乎所有索引操作和函数,融合了字典和ndarray的优点。
B.1 Series常用属性
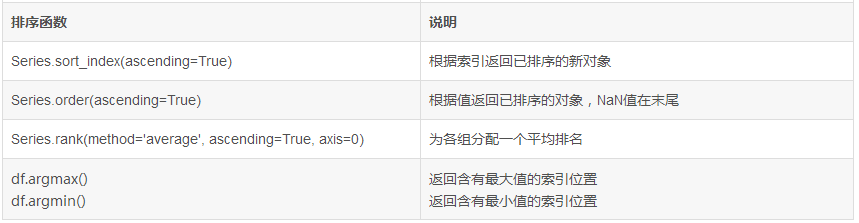
B.2 Series常用函数
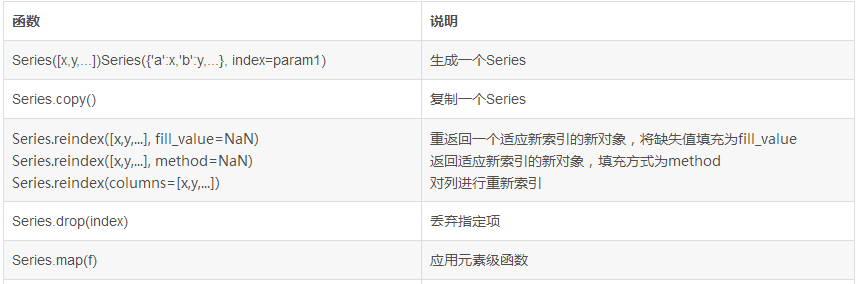
reindex的method选项:
ffill, bfill 向前填充/向后填充
pad, backfill 向前搬运,向后搬运
rank的method选项
'average' 在相等分组中,为各个值分配平均排名
'max','min' 使用整个分组中的最小排名
'first' 按值在原始数据中出现的顺序排名
C.DataFrame
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
DataFrame可以通过类似字典的方式或者.columnname的方式将列获取为一个Series。行也可以通过位置或名称的方式进行获取。
为不存在的列赋值会创建新列。
>>> del frame['xxx'] # 删除列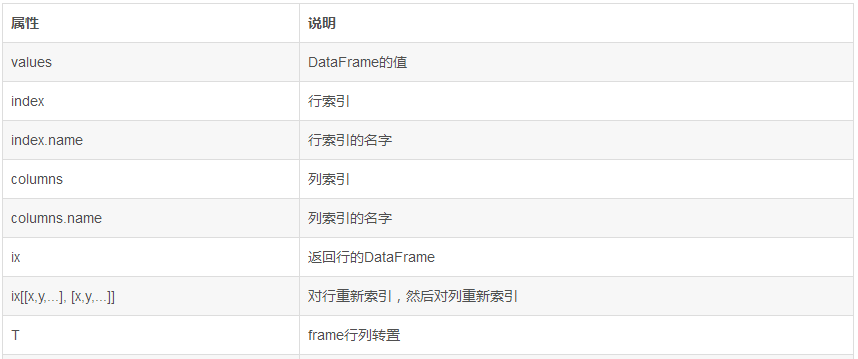
C.1 DataFrame常用属性
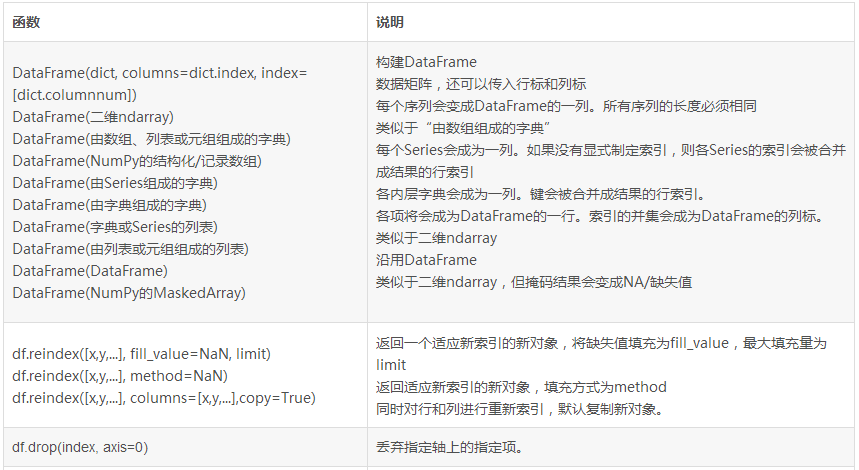


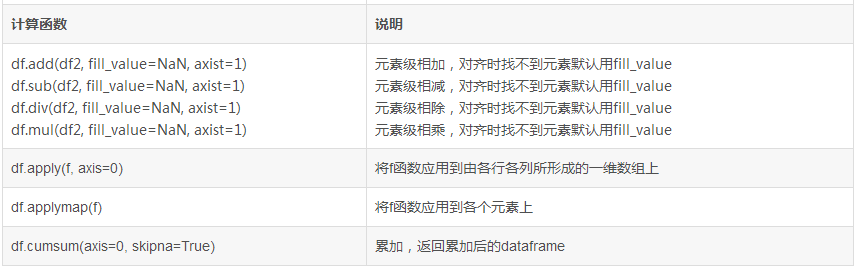
C.2 Dataframe常用函数
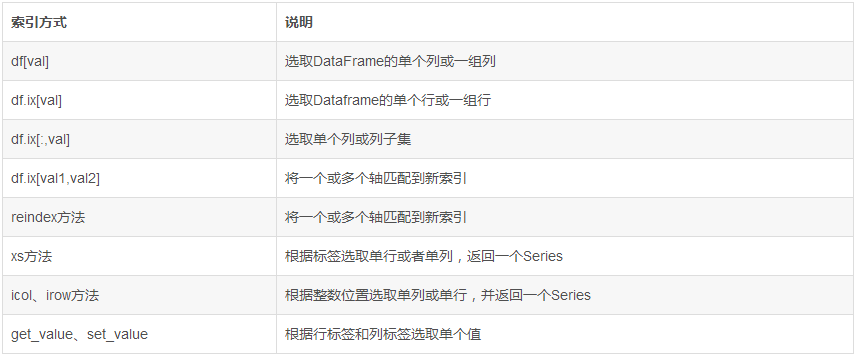
C.3 Dataframe常用索引方式
运算:
默认情况下,Dataframe和Series之间的算术运算会将Series的索引匹配到的Dataframe的列,沿着列一直向下传播。若索引找不到,则会重新索引产生并集。
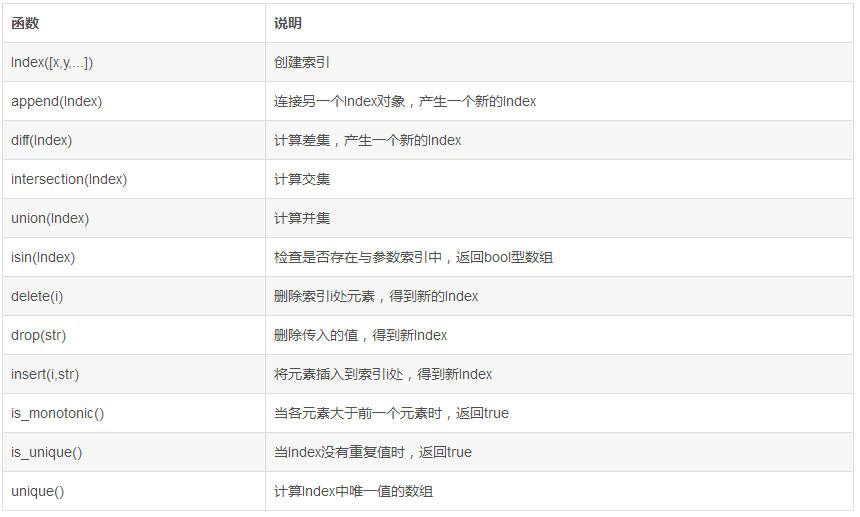
D.Index
pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index。Index对象不可修改,从而在多个数据结构之间安全共享。
D.1 主要的Index属性