项目设计目的
通过一个综合数据分析案例:”金庸的江湖——金庸武侠小说中的人物关系挖掘“,来学习和掌握MapReduce程序设计。通过本项目的学习,可以体会如何使用MapReduce完成一个综合性的数据挖掘任务,包括全流程的数据预处理、数据分析、数据后处理等。
1 任务1 数据预处理
1.1 任务描述
从原始的金庸小说文本中,抽取出与人物互动相关的数据,而屏蔽掉与人物关系无关的文本内容,为后面的基于人物共现的分析做准备。
数据输入:
1.全本的金庸武侠小说文集(未分词);
2. 金庸武侠小说人名列表。 数据输出:分词后,仅保留人名的金庸武侠小说全集。 样例输入: 狄云和戚芳一走到万家大宅之前,瞧见那高墙朱门、挂灯结彩的气派,心中都是暗自嘀咕。戚芳紧紧拉住了父亲的衣袖。戚长发正待向门公询问,忽见卜垣从门里出来,心中一喜,叫道:“卜贤侄,我来啦。”
样例输出:狄云 戚芳 戚芳 戚长发 卜垣
1.2 关键问题
1.2.1 中文分词和人名提取
使用开源的Ansj_seg进行分词。Ansj_seg不仅支持中文分词,还允许用户自定义词典,在分词前,将人名列表到添加用户自定义的词典,可以精确识别金庸武侠小说中的人名。
但实际测试的时候发现,Ansj_seg分词会出现严重的歧义问题,比如“汉子”属于人名列表中的人名(nr),但Ansj_seg可能会错误地将它分类为名词(n)。因此,如果根据词性提取人名,会导致最后提取的人名太少。解决方法是在提取人名的时候,需要在将人名加入用户自定义词典的同时,构造一个包含所有人名的字典,对分词的结果逐个进行测试,如果在字典里,就是人名。
1.2.2 文件传输
使用HDFS传递数据。考虑到人名列表文件已经存放在了HDFS里,所以使用HDFS的方式不需要移动人名列表文件,只需要在Configuration中设置文件在HDFS文件系统中的路径,然后在Mapper的setup()函数里调用HDFS的函数获取文件内容即可。
1.2.3 单词同现算法
两个单词近邻关系的定义:实验要求中已经说明,同现关系为一个段落。
段落划分:非常庆幸的是,小说原文中一个段落就是一行,因此,不需要自己定义FileInputFormat和RecordReader。
1.3 MapReduce设计
1.3.1 Mapper
/**
* 该类做为一个 mapTask 使用。类声名中所使用的四个泛型意义为别为:
*
* KEYIN: 默认情况下,是mr框架所读到的一行文本的起始偏移量,Long,
* 但是在hadoop中有自己的更精简的序列化接口,所以不直接用Long,而用LongWritable
* VALUEIN: 默认情况下,是mr框架所读到的一行文本的内容,String,同上,用Text
* KEYOUT: 是用户自定义逻辑处理完成之后输出数据中的key,在此处是单词,String,同上,用Text
* VALUEOUT:是用户自定义逻辑处理完成之后输出数据中的value,在此处是单词次数,Integer,同上,用IntWritable
*/
public class FirstStepMapper extends Mapper<LongWritable,Text,LongWritable,Text>
{
Set<String> nameSets = new HashSet<String>();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
File file = new File("person/jinyong_all_person.txt");
FileReader fileReader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String line = bufferedReader.readLine();
while (line != null)
{
//process
DicLibrary.insert(DicLibrary.DEFAULT, line);
nameSets.add(line);
line = bufferedReader.readLine();
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
line = line.replace("道","");
Result result = DicAnalysis.parse(line);
List<Term> termList=result.getTerms();
StringBuilder stringBuilder = new StringBuilder();
for(Term term:termList){
if(nameSets.contains(term.getName()))
{
stringBuilder.append(term.getName() + '\t');
}
}
context.write(key,new Text(stringBuilder.toString()));
}
}
1.3.2 Reducer
public class FirstStepReducer extends Reducer<LongWritable,Text,Text,NullWritable>
{
//list()
@Override
protected void reduce(LongWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Text strNameLine = values.iterator().next();
if(!strNameLine.toString().equals(""))
{
context.write(strNameLine,NullWritable.get());
}
}
}
1.3.3 Driver
public class FirstStepDriver {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "root") ;
System.setProperty("hadoop.home.dir", "e:/hadoop-2.8.3");
if (args == null || args.length == 0) {
return;
}
FileUtil.deleteDir(args[1]);
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//jar
job.setJarByClass(FirstStepDriver.class);
job.setMapperClass(FirstStepMapper.class);
job.setReducerClass(FirstStepReducer.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileInputFormat.setMaxInputSplitSize(job, 1024*1024);
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean bResult = job.waitForCompletion(true);
System.out.println("--------------------------------");
System.exit(bResult ? 0 : 1);
}
}
2 任务2 特征抽取:人物同现统计
2.1 任务描述
完成基于单词同现算法的人物同现统计。在人物同现分析中,如果两个人在原文的同一段落中出现,则认为两个人发生了一次同现关系。我们需要对人物之间的同现关系次数进行统计,同现关系次数越多,则说明两人的关系越密切。
数据输入:任务1的输出
数据输出:在金庸的所有武侠小说中,人物之间的同现次数
样例输入:
狄云 戚芳 戚芳 戚长发 卜垣
戚芳 卜垣 卜垣
样例输出:
<狄云,戚芳> 1 <戚长发,狄云 > 1
<狄云,戚长发> 1 <戚长发,戚芳 > 1
<狄云,卜垣> 1 <戚长发,卜垣 > 1
<戚芳,狄云 > 1 <卜垣,狄云> 1
<戚芳,戚长发 > 1 <卜垣,戚芳> 2
<戚芳,卜垣 > 2 <卜垣,戚长发> 1
2.2 关键问题
2.2.1 人名冗余
在同一段中,人名可能多次出现,任务一只负责提取出所有的人名,没有剔除多余的人名,任务必须在输出同现次数之前处理冗余人名。我的做法是在Mapper中创建一个集合,把所有人名放入集合中,集合会自动剔除冗余的人名。
2.2.2 同现次数统计
两个人物之间应该输出两个键值对,如“狄云”和“戚芳”,应该输出“<狄云,戚芳> 1”和“<戚芳,狄云> 1”。多个段落中允许输出相同的键值对,因此,Reducer中需要整合具有相同键的输出,输出总的同现次数。
2.3 MapReduce设计
2.3.1 Mapper
public class SecondStepMapper extends Mapper<LongWritable,Text,Text,LongWritable> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Set<String> set = new HashSet<>();
String[] names = value.toString().split("\t");
for (String name : names) {
set.add(name);
}
for (String name1 : set) {
for (String name2 : set) {
if (!name1.equals(name2)) {
context.write(new Text(name1 + "_" + name2), new LongWritable(1));
}
}
}
}
}
2.3.2 Reducer
public class SecondStepReduce extends Reducer<Text,LongWritable,Text,LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int sum=0;
for ( LongWritable value: values) {
sum+=value.get();
}
context.write(key, new LongWritable(sum));
}
}
3 任务3 特征处理:人物关系图构建与特征归一化
3.1 任务描述
根据任务2人物之间的共现关系,生成人物之间的关系图。人物关系使用邻接表的形式表示,人物是顶点,人物之间关系是边,两个人的关系的密切程度由共现次数体现,共现次数越高,边权重越高。另外需要对共现次数进行归一化处理,确保某个顶点的出边权重和为1。
数据输入:任务2的输出
数据输出:归一化权重后的人物关系图
样例输入:
<狄云,戚芳> 1 <戚长发,狄云 > 1
<狄云,戚长发> 1 <戚长发,戚芳 > 1
<狄云,卜垣> 1 <戚长发,卜垣 > 1
<戚芳,狄云 > 1 <卜垣,狄云> 1
<戚芳,戚长发 > 1 <卜垣,戚芳> 2
<戚芳,卜垣 > 2 <卜垣,戚长发> 1
样例输出:
狄云\t戚芳:0.33333;戚长发:0.333333;卜垣:0.333333
戚芳\t狄云:0.25 ;戚长发:0.25;卜垣:0.5
戚长发\t狄云:0.33333;戚芳:0.333333;卜垣:0.333333
卜垣\t狄云:0.25;戚芳:0.5;戚长发:0.25扫描二维码关注公众号,回复: 5057474 查看本文章
3.2 关键问题
3.2.1 确保人物的所有邻居输出到相同结点处理
在Mapper结点将输入的键值对“<狄云,戚芳> 1”拆分,输出新的键值对“<狄云> 戚芳:1”,“狄云”的所有邻居会被分配给同一个Reducer结点处理。
3.2.2 归一化
在Reducer结点首先统计该人物与所有邻居同现的次数和sum,每个邻居的的同现次数除以sum就得到共现概率。为了提高效率,在第一次遍历邻居的时候,可以把名字和共现次数保存在链表里,避免重复处理字符串。
3.3 MapReduce设计
3.3.1 Mapper
package com.neuedu;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
public class ThirdStepMapper extends Mapper<LongWritable,Text,Text,Text>
{
// 齐元凯_吴应熊 1
// 齐元凯_神照上人 1
// 齐元凯_韦小宝 5
// 齐元凯_鳌拜 1
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] arrs = value.toString().split("\t");
String[] arrs2 = arrs[0].split("_");
String outValue = arrs2[1] + " " + arrs[1];//吴应熊,1
context.write(new Text(arrs2[0]), new Text(outValue));
}
}
3.3.2 Reducer
package com.neuedu;
//<I,1><have,1><a,1><dream,1><a,1><dream,1>
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class ThirdStepReducer extends Reducer<Text,Text,Text,NullWritable>
{
//<齐元凯,List(吴应熊 1,神照上人 1,韦小宝 5,鳌拜 1)>
// 齐元凯\t吴应熊:0.125;神照上人:0.125;韦小宝:0.625;鳌拜:0.125
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
double sum = 0;
List<String> textList = new ArrayList<String>();
for(Text text : values)
{
String[] split = text.toString().split(" ");
long count = Long.parseLong(split[1]);
sum += count;
textList.add(text.toString());
}
//<齐元凯,List(吴应熊 1,神照上人 1,韦小宝 5,鳌拜 1)>
// 齐元凯\t吴应熊:0.125;神照上人:0.125;韦小宝:0.625;鳌拜:0.125
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append(key.toString());
stringBuilder.append("\t");
stringBuilder.append("0.1#");
for(String text : textList)
{
String[] split = text.split(" ");
stringBuilder.append(split[0]);
stringBuilder.append(":");
double rate = Long.parseLong(split[1])/sum;
stringBuilder.append(String.valueOf(rate));
stringBuilder.append(";");
}
String output = stringBuilder.toString();
output = output.substring(0,output.length()-1);
context.write(new Text(output),NullWritable.get());
}
}
4 任务4 数据分析:基于人物关系图的PageRank计算
4.1 任务描述
经过数据预处理并获得任务的关系图之后,就可以对人物关系图作数据分析,其中一个典型的分析任务是:PageRank 值计算。通过计算 PageRank,我们就可以定量地获知金庸武侠江湖中的“主角”们是哪些。
4.2 PageRank原理
PageRank算法由Google的两位创始人佩奇和布林在研究网页排序问题时提出,其核心思想是:如果一个网页被很多其它网页链接到,说明这个网页很重要,它的PageRank值也会相应较高;如果一个PageRank值很高的网页链接到另外某个网页,那么那个网页的PageRank值也会相应地提高。
相应地,PageRank算法应用到人物关系图上可以这么理解:如果一个人物与多个人物存在关系连接,说明这个人物是重要的,其PageRank值响应也会较高;如果一个PageRank值很高的人物与另外一个人物之间有关系连接,那么那个人物的PageRank值也会相应地提高。一个人物的PageRank值越高,他就越可能是小说中的主角。
PageRank有两个比较常用的模型:简单模型和随机浏览模型。由于本次设计考虑的是人物关系而不是网页跳转,因此简单模型比较合适。简单模型的计算公式如下,其中Bi为所有连接到人物i的集合,Lj为认为人物j对外连接边的总数:
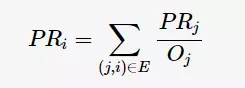
在本次设计的任务3中,已经对每个人物的边权值进行归一化处理,边的权值可以看做是对应连接的人物占总边数的比例。设表示人物i在人物j所有边中所占的权重,则PageRank计算公式可以改写为:
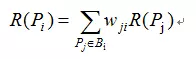
4.3 PageRank在mapreduce上的实现细节
4.3.1 GraphBuilder类
PageRank需要迭代来实现PageRank值的更新,因而需要先给每个人物初始化一个PageRank值以供迭代过程的执行,该部分由GraphBuilder类完成,仅包含一个Map过程。由于算法收敛与初始值无关,所以我们将每个人物的PageRank值都初始化为0.1,以任务3的输出文件作为Map输入,可以得到如下样例格式:
数据输入:任务3的输出
数据输出:人物的PageRank值
样例输入:
一灯大师 完颜萍:0.005037783;小龙女:0.017632242;……
样例输出:
一灯大师 0.1#完颜萍:0.005037783;小龙女:0.017632242;……
4.3.2 PageRanklter类
GraphBuilder将数据处理成可供迭代的格式,PageRank的迭代过程由PageRanklter类实现,包含一个Map和Reduce过程。Map过程产生两种类型的<key,value>:<人物名,PageRrank值>,<人物名,关系链表>。第一个人物名是关系链表中的各个链出人物名,其PR值由计算得到;第二个人物名是本身人物名,目的是为了保存该人物的链出关系,以保证完成迭代过程。以上面的输出为例,则Map过程产生的键值对为<完颜萍, 1.00.005037>,<小龙女, 1.00.017632>,……,<一灯大师, #完颜萍:0.005037783;……>。
Reduce过程将同一人物名的<key,value>汇聚在一起,如果value是PR值,则累加到sum变量;如果value是关系链表则保存为List。遍历完迭代器里所有的元素后输出键值对<人物名,sum#List>,这样就完成了一次迭代过程。
PR值排名不变的比例随迭代次数变化的关系图如下,由于我们考虑的是找出小说中的主角,所以只要关心PR值前100名的人物的排名的变化情况,可以看到迭代次数在10以后,PR值排名不变的比例已经趋于稳定了,所以基于效率考虑,选取10作为PR的迭代次数。
4.3.3 PageRankViewer类
当所有迭代都完成后,我们就可以对所有人物的PageRank值进行排序,该过程由PageRankViewer类完成,包含一个Map和Reduce过程。Map过程只提取迭代过程输出结果中的人物名以及对应的PageRank值,并以PageRank值作为key,人物名作为value输出。为了实现PageRank值从大到小排序,需要实现DescFloatComparator类来重写compare方法以达成逆序排序。由于可能存在PageRank值相同的情况,所以还需要一个reduce过程来把因PageRank值相同而汇聚到一起的人物名拆开并输出。
PageRankMapper
package com.neuedu;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FourStepMapper extends Mapper<LongWritable,Text,Text,Text>
{
//凌霜华 0.1#狄云:0.3333333333333333;丁典:0.3333333333333333;戚芳:0.3333333333333333
//凌霜华 #狄云:0.3333333333333333;丁典:0.3333333333333333;戚芳:0.3333333333333333
//<凌霜华,List(xxx,yyy,zzz,#狄云:0.3333333333333333;丁典:0.3333333333333333;戚芳:0.3333333333333333)
//凌霜华 1.26#狄云:0.3333333333333333;丁典:0.3333333333333333;戚芳:0.3333333333333333
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("#");
String[] split2 = split[0].split("\t");
String mainPeopleName = split2[0];
String mainPeopleRank = split2[1];
String[] split1 = split[1].split(";");
for(String string : split1)
{
String[] split3 = string.split(":");
double relation_value = Double.parseDouble(split3[1]);
context.write(new Text(split3[0]),new Text(String.valueOf(relation_value * Double.parseDouble(mainPeopleRank))));
}
context.write(new Text(mainPeopleName),new Text("#"+split[1]));
}
}
PageRankReducer
package com.neuedu;
//<I,1><have,1><a,1><dream,1><a,1><dream,1>
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class FourStepReducer extends Reducer<Text,Text,Text,Text>
{
//<凌霜华,List(xxx,yyy,zzz,#狄云:0.3333333333333333;丁典:0.3333333333333333;戚芳:0.3333333333333333)
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
double sum = 0;
String tail = "";
// 凌霜华 0.1#狄云:0.3333333333333333;丁典:0.3333333333333333;戚芳:0.3333333333333333
for(Text text : values)
{
if(!text.toString().startsWith("#"))
{
sum+=Double.parseDouble(text.toString());
}
else
{
tail = text.toString();
}
}
context.write(key,new Text(sum + tail));
}
}
Driver类
package com.neuedu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FourStepDriver {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "root") ;
System.setProperty("hadoop.home.dir", "e:/hadoop-2.8.3");
if (args == null || args.length == 0) {
return;
}
// FileUtil.deleteDir(args[1]);
for(int i = 3; i < 13; i++)
{
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//jar
job.setJarByClass(FourStepDriver.class);
job.setMapperClass(FourStepMapper.class);
job.setReducerClass(FourStepReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
String inputPath = "output" + i + "/part-r-00000";
FileInputFormat.setInputPaths(job,new Path(inputPath));
FileInputFormat.setMaxInputSplitSize(job, 1024*1024);
String outputPath = "output" + (i + 1);
FileOutputFormat.setOutputPath(job,new Path(outputPath));
boolean bResult = job.waitForCompletion(true);
System.out.println("--------------------------------");
}
System.exit(0);
}
}
5 任务5 数据分析:基于人物关系图的标签传播
5.1 任务描述
标签传播(Label Propagation)是一种半监督的图分析算法,他能为图上的顶点打标签,进行图顶点的聚类分析,从而在一张类似社交网络图中完成社区发现。在人物关系图中,通过标签传播算法可以将关联度比较大的人物分到同一标签,可以直观地分析人物间的关系。
5.2 标签传播算法原理
标签传播算法(Label Propagation Algorithm,后面简称LPA)是由Zhu等人于2002年提出,它是一种基于图的半监督学习方法,其基本思路是用已标记节点的标签信息去预测未标记节点的标签信息。LPA基本过程为:(1)每个结点初始化一个特定的标签值;(2)逐轮更新所有节点的标签,直到所有节点的标签不再发生变化为止。对于每一轮刷新,节点标签的刷新规则如下:对于某一个节点,考察其所有邻居节点的标签,并进行统计,将出现个数最多的那个标签赋值给当前节点。当个数最多的标签不唯一时,随机选择一个标签赋值给当前节点。
LPA与PageRank算法相似,同样需要通过迭代过程来完成。在标签传播算法中,节点的标签更新通常有同步更新和异步更新两种方法。同步更新是指,节点x在t时刻的更新是基于邻接节点在t-1时刻的标签。异步更新是指,节点x在t时刻更新时,其部分邻接节点是t时刻更新的标签,还有部分的邻接节点是t-1时刻更新的标签。若LPA算法在标签传播过程中采用的是同步更新,则在二分结构网络中,容易出现标签震荡的现象。在本次设计中,我们考虑到了两种更新方法,并进行了比较。
5.3 标签传播算法在mapreduce上的实现细节
5.3.1 LPAInit类
为实现LPA的迭代过程,需要先给每个人物赋予一个独特标签,标签初始化由LPAInit类完成,仅包含一个Map过程。标签由数字表示,Map过程由1开始,为每一个人物名赋予一个独特的标签。为了便于后面的可视化分析,我们需要把PageRank值和标签整合在一起,所以LPAInit的输入文件直接采用PageRank过程的输出文件,格式如下:
数据输入:任务3的输出
数据输出:附带初始标签的输出
样例输入:
一灯大师 完颜萍:0.005037783;小龙女:0.017632242;……
样例输出:
一灯大师# 0.06955 0.1#完颜萍:0.005037783;小龙女:0.017632242;……
5.3.2 LPAIteration类
LPAIteration类完成标签的更新过程,其格式与LPAInit的输出格式一致,包含一个Map和Reduce过程。Map过程对输入的每一行进行切割,输出四种格式的<key,value>:<人物名,关系链表>,<人物名,PageRank值>,<人物名,标签>,<链出人物名,标签#起点人物名>。第四种格式个键值对是为了将该节点的标签传给其所有邻居。
Reduce过程对value值进行识别,识别可以通过Map过程把预先定义好的特殊字符如‘#’、‘@’来实现前缀到value上来实现。由于人物关系图中的各个边都是有权重的,并且代表两个人物的相关程度,所以标签更新过程不是用边数最多的标签而是权重最大标签来更新,我们可以预先把权重最大的若干个保存到一个链表中,如果存在多个权重相同的标签,则随机选取一个作为该人名新的标签。异步方法更新标签需要使用一个哈希表来存储已经更新标签的人物名和它们的新标签,并且在更新标签时使用该哈希表里面的标签。同步方法更新标签则不需要存储已更新的标签。
本次设计中比较了同步和异步更新两种方法,下图为标签不变的比例随迭代次数的变化。可以发现,异步收敛速度更快,只要6次迭代即可完全收敛,且标签不变的比例可达100%。而同步更新方法则不能达到100%,说明人物关系图中存在子图是二部子图。
5.3.3 LPAReorganize类
LPA算法迭代收敛后,所有人物名的标签不再变化,但是此时的标签排列是散乱的,需要把同一标签的人物名整合在一起。该过程由LPAReorganize类完成,包含一个Map和Reduce过程。Map过程对输入的每一行进行切割,以<标签,人物名#PageRank值#关系链表>格式输出。Reduce过程中,同一标签的人物名汇聚在一起,然后根据每个标签人物集合的大小从大到小排序,重新赋予标签(从1开始)。这样输出文件中同一标签的人物名就会聚集在一起。最后的输出格式如下:
数据输入:LPAInit的输出
数据输出:人物的标签信息和PR值
样例输入:
一灯大师#0.06955 1#完颜萍:0.005037783;小龙女:0.017632242;……
样例输出:
1#一灯大师#0.06955 完颜萍:0.005037783;小龙女:0.017632242;……
5.3.2 LPAMapper类
LPAIteration类完成标签的更新过程,其格式与LPAInit的输出格式一致,包含一个Map和Reduce过程。Map过程对输入的每一行进行切割,输出四种格式的<key,value>:<人物名,关系链表>,<人物名,PageRank值>,<人物名,标签>,<链出人物名,标签#起点人物名>。第四种格式个键值对是为了将该节点的标签传给其所有邻居。
package com.neuedu;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FiveStepMapper extends Mapper<LongWritable,Text,Text,Text>
{
//1#一灯大师 0.16643123198477025#完颜萍:0.004662004662004662;小龙女:0.018648018648018648;尹克西:0.002331002331002331;尼摩星:0.006993006993006993;张无忌:0.004662004662004662;无色:0.002331002331002331;明月:0.002331002331002331;朱九真:0.004662004662004662;朱子柳:0.027972027972027972;朱长龄:0.002331002331002331;李莫愁:0.009324009324009324;杨康:0.006993006993006993;杨过:0.07692307692307693;柯镇恶:0.004662004662004662;梅超风:0.002331002331002331;樵子:0.02097902097902098;欧阳克:0.006993006993006993;武三娘:0.004662004662004662;武三通:0.030303030303030304;武修文:0.006993006993006993;武敦儒:0.004662004662004662;洪七公:0.023310023310023312;渔人:0.02564102564102564;潇湘子:0.002331002331002331;点苍渔隐:0.006993006993006993;王处一:0.004662004662004662;琴儿:0.002331002331002331;穆念慈:0.002331002331002331;老头子:0.002331002331002331;耶律燕:0.006993006993006993;耶律齐:0.011655011655011656;裘千丈:0.002331002331002331;裘千仞:0.030303030303030304;上官:0.002331002331002331;裘千尺:0.013986013986013986;觉远:0.002331002331002331;觉远大师:0.002331002331002331;说不得:0.002331002331002331;达尔巴:0.004662004662004662;郝大通:0.004662004662004662;郭芙:0.009324009324009324;郭襄:0.039627039627039624;郭靖:0.11655011655011654;金轮法王:0.009324009324009324;陆乘风:0.002331002331002331;陆无双:0.016317016317016316;霍都:0.006993006993006993;马钰:0.004662004662004662;鲁有脚:0.009324009324009324;黄药师:0.03263403263403263;黄蓉:0.16783216783216784;小沙弥:0.006993006993006993;丘处机:0.011655011655011656;乔寨主:0.002331002331002331;书生:0.03496503496503497;农夫:0.037296037296037296;华筝:0.002331002331002331;卫璧:0.004662004662004662;吕文德:0.002331002331002331;周伯通:0.06060606060606061;哑巴:0.002331002331002331;哑梢公:0.002331002331002331;大汉:0.002331002331002331;天竺僧:0.002331002331002331;天竺僧人:0.006993006993006993
//<完颜萍,1#一灯大师>
//<小龙女,1#一灯大师>
// ...
//<天竺僧人,1#一灯大师>
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("\t");
String[] split1 = split[0].split("#");
String mainPeople = split1[1];
String[] split2 = split[1].split("#");
//<一灯大师,#完颜萍:0.004662004662004662;小龙女:0.018648018648018648;尹克西:0.002331002331002331;尼摩星:0.006993006993006993;张无忌:0.004662004662004662;无色:0.002331002331002331;明月:0.002331002331002331;朱九真:0.004662004662004662;朱子柳:0.027972027972027972;朱长龄:0.002331002331002331;李莫愁:0.009324009324009324;杨康:0.006993006993006993;杨过:0.07692307692307693;柯镇恶:0.004662004662004662;梅超风:0.002331002331002331;樵子:0.02097902097902098;欧阳克:0.006993006993006993;武三娘:0.004662004662004662;武三通:0.030303030303030304;武修文:0.006993006993006993;武敦儒:0.004662004662004662;洪七公:0.023310023310023312;渔人:0.02564102564102564;潇湘子:0.002331002331002331;点苍渔隐:0.006993006993006993;王处一:0.004662004662004662;琴儿:0.002331002331002331;穆念慈:0.002331002331002331;老头子:0.002331002331002331;耶律燕:0.006993006993006993;耶律齐:0.011655011655011656;裘千丈:0.002331002331002331;裘千仞:0.030303030303030304;上官:0.002331002331002331;裘千尺:0.013986013986013986;觉远:0.002331002331002331;觉远大师:0.002331002331002331;说不得:0.002331002331002331;达尔巴:0.004662004662004662;郝大通:0.004662004662004662;郭芙:0.009324009324009324;郭襄:0.039627039627039624;郭靖:0.11655011655011654;金轮法王:0.009324009324009324;陆乘风:0.002331002331002331;陆无双:0.016317016317016316;霍都:0.006993006993006993;马钰:0.004662004662004662;鲁有脚:0.009324009324009324;黄药师:0.03263403263403263;黄蓉:0.16783216783216784;小沙弥:0.006993006993006993;丘处机:0.011655011655011656;乔寨主:0.002331002331002331;书生:0.03496503496503497;农夫:0.037296037296037296;华筝:0.002331002331002331;卫璧:0.004662004662004662;吕文德:0.002331002331002331;周伯通:0.06060606060606061;哑巴:0.002331002331002331;哑梢公:0.002331002331002331;大汉:0.002331002331002331;天竺僧:0.002331002331002331;天竺僧人:0.006993006993006993>
context.write(new Text(mainPeople),new Text("#" + split2[1]));
context.write(new Text(mainPeople),new Text("@" + split2[0]));
String[] split3 = split2[1].split(";");
//<完颜萍,1#一灯大师>
//<小龙女,1#一灯大师>
// ...
//<天竺僧人,1#一灯大师>
for(String string : split3)
{
String[] split4 = string.split(":");
context.write(new Text(split4[0]),new Text(split[0]));
}
}
}
5.3.2 LPAReducer类
Reduce过程对value值进行识别,识别可以通过Map过程把预先定义好的特殊字符如‘#’、‘@’来实现前缀到value上来实现。由于人物关系图中的各个边都是有权重的,并且代表两个人物的相关程度,所以标签更新过程不是用边数最多的标签而是权重最大标签来更新,我们可以预先把权重最大的若干个保存到一个链表中,如果存在多个权重相同的标签,则随机选取一个作为该人名新的标签。异步方法更新标签需要使用一个哈希表来存储已经更新标签的人物名和它们的新标签,并且在更新标签时使用该哈希表里面的标签。同步方法更新标签则不需要存储已更新的标签。
package com.neuedu;
//<I,1><have,1><a,1><dream,1><a,1><dream,1>
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class FiveStepReducer extends Reducer<Text,Text,Text,Text>
{
Map<String,String> mapGlobalName2Label = new HashMap<>();
//<一灯大师,#完颜萍:0.004662004662004662;小龙女:0.018648018648018648;尹克西:0.002331002331002331;尼摩星:0.006993006993006993;张无忌:0.004662004662004662;无色:0.002331002331002331;明月:0.002331002331002331;朱九真:0.004662004662004662;朱子柳:0.027972027972027972;朱长龄:0.002331002331002331;李莫愁:0.009324009324009324;杨康:0.006993006993006993;杨过:0.07692307692307693;柯镇恶:0.004662004662004662;梅超风:0.002331002331002331;樵子:0.02097902097902098;欧阳克:0.006993006993006993;武三娘:0.004662004662004662;武三通:0.030303030303030304;武修文:0.006993006993006993;武敦儒:0.004662004662004662;洪七公:0.023310023310023312;渔人:0.02564102564102564;潇湘子:0.002331002331002331;点苍渔隐:0.006993006993006993;王处一:0.004662004662004662;琴儿:0.002331002331002331;穆念慈:0.002331002331002331;老头子:0.002331002331002331;耶律燕:0.006993006993006993;耶律齐:0.011655011655011656;裘千丈:0.002331002331002331;裘千仞:0.030303030303030304;上官:0.002331002331002331;裘千尺:0.013986013986013986;觉远:0.002331002331002331;觉远大师:0.002331002331002331;说不得:0.002331002331002331;达尔巴:0.004662004662004662;郝大通:0.004662004662004662;郭芙:0.009324009324009324;郭襄:0.039627039627039624;郭靖:0.11655011655011654;金轮法王:0.009324009324009324;陆乘风:0.002331002331002331;陆无双:0.016317016317016316;霍都:0.006993006993006993;马钰:0.004662004662004662;鲁有脚:0.009324009324009324;黄药师:0.03263403263403263;黄蓉:0.16783216783216784;小沙弥:0.006993006993006993;丘处机:0.011655011655011656;乔寨主:0.002331002331002331;书生:0.03496503496503497;农夫:0.037296037296037296;华筝:0.002331002331002331;卫璧:0.004662004662004662;吕文德:0.002331002331002331;周伯通:0.06060606060606061;哑巴:0.002331002331002331;哑梢公:0.002331002331002331;大汉:0.002331002331002331;天竺僧:0.002331002331002331;天竺僧人:0.006993006993006993>
//<一灯大师,100#尹克西>
//<一灯大师,250#完颜萍>
// ...
//<一灯大师,List[100#尹克西,250#完颜萍,#完颜萍:0.004662004662004662;小龙女:0.018648018648018648;尹克西:0.002331002331002331;尼摩星:0.006993006993006993;张无忌:0.004662004662004662;无色:0.002331002331002331;明月:0.002331002331002331;朱九真:0.004662004662004662;朱子柳:0.027972027972027972;朱长龄:0.002331002331002331;李莫愁:0.009324009324009324;杨康:0.006993006993006993;杨过:0.07692307692307693;柯镇恶:0.004662004662004662;梅超风:0.002331002331002331;樵子:0.02097902097902098;欧阳克:0.006993006993006993;武三娘:0.004662004662004662;武三通:0.030303030303030304;武修文:0.006993006993006993;武敦儒:0.004662004662004662;洪七公:0.023310023310023312;渔人:0.02564102564102564;潇湘子:0.002331002331002331;点苍渔隐:0.006993006993006993;王处一:0.004662004662004662;琴儿:0.002331002331002331;穆念慈:0.002331002331002331;老头子:0.002331002331002331;耶律燕:0.006993006993006993;耶律齐:0.011655011655011656;裘千丈:0.002331002331002331;裘千仞:0.030303030303030304;上官:0.002331002331002331;裘千尺:0.013986013986013986;觉远:0.002331002331002331;觉远大师:0.002331002331002331;说不得:0.002331002331002331;达尔巴:0.004662004662004662;郝大通:0.004662004662004662;郭芙:0.009324009324009324;郭襄:0.039627039627039624;郭靖:0.11655011655011654;金轮法王:0.009324009324009324;陆乘风:0.002331002331002331;陆无双:0.016317016317016316;霍都:0.006993006993006993;马钰:0.004662004662004662;鲁有脚:0.009324009324009324;黄药师:0.03263403263403263;黄蓉:0.16783216783216784;小沙弥:0.006993006993006993;丘处机:0.011655011655011656;乔寨主:0.002331002331002331;书生:0.03496503496503497;农夫:0.037296037296037296;华筝:0.002331002331002331;卫璧:0.004662004662004662;吕文德:0.002331002331002331;周伯通:0.06060606060606061;哑巴:0.002331002331002331;哑梢公:0.002331002331002331;大汉:0.002331002331002331;天竺僧:0.002331002331002331;天竺僧人:0.006993006993006993>]
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
Map<String,Double> mapName2Weight = new HashMap<>();
Map<String,String> mapName2Label = new HashMap<>();
String peopleRelation = "";
String peoplePR = "";
List<String> labelPeopleNameList = new ArrayList<>();
for(Text text : values)
{
String content = text.toString();
if(content.startsWith("#"))
{
peopleRelation = content.replace("#","");
}
else if(content.startsWith("@"))
{
peoplePR = content.replace("@","");
}
else
{
//List[100#尹克西,250#完颜萍]
labelPeopleNameList.add(content);
}
}
String[] arrNameWeight = peopleRelation.split(";");
for(String string : arrNameWeight)
{
//小龙女:0.018648018648018648
String[] split = string.split(":");
mapName2Weight.put(split[0],Double.parseDouble(split[1]));
}
Map<String,Double> mapLabel2Weight = new HashMap<>();
for(String string : labelPeopleNameList)
{
//100#尹克西
String[] split = string.split("#");
mapName2Label.put(split[1],split[0]);
// 7 zhangsan 0.3
// 7 wangwu 0.4
String label = split[0];
if(mapGlobalName2Label.containsKey(split[1]))
{
label = mapGlobalName2Label.get(split[1]);
}
if(!mapLabel2Weight.containsKey(label))
{
mapLabel2Weight.put(label,mapName2Weight.get(split[1]));
}
else
{
Double weight = mapLabel2Weight.get(label);
weight += mapName2Weight.get(split[1]);
mapLabel2Weight.put(label,weight);
}
}
//比较主要人物周围的人,找到关系最密切的那个,将主要人物的标签label更新成那个人的label
double maxWeight = 0;
// String peopleMax = "";
String newLabel = "";
for(Map.Entry<String,Double> entry : mapLabel2Weight.entrySet())
{
double weight = entry.getValue();
if(maxWeight < weight)
{
maxWeight = weight;
newLabel = entry.getKey();
}
}
// String newLabel = mapName2Label.get(peopleMax);
mapGlobalName2Label.put(key.toString(),newLabel);
Text keyWrite = new Text(newLabel + "#" + key.toString());
Text valueWrite = new Text(peoplePR + "#" + peopleRelation);
context.write(keyWrite,valueWrite);
}
}
Driver类
package com.neuedu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FiveStepDriver {
public static void main(String[] args) throws Exception {
System.setProperty("HADOOP_USER_NAME", "root") ;
System.setProperty("hadoop.home.dir", "e:/hadoop-2.8.3");
// if (args == null || args.length == 0) {
// return;
// }
// FileUtil.deleteDir(args[1]);
for(int i = 14; i < 24; i++)
{
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
//jar
job.setJarByClass(FiveStepDriver.class);
job.setMapperClass(FiveStepMapper.class);
job.setReducerClass(FiveStepReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
String inputPath = "output" + i + "/part-r-00000";
FileInputFormat.setInputPaths(job,new Path(inputPath));
FileInputFormat.setMaxInputSplitSize(job, 1024*1024);
String outputPath = "output" + (i + 1);
FileOutputFormat.setOutputPath(job,new Path(outputPath));
boolean bResult = job.waitForCompletion(true);
System.out.println("--------------------------------");
}
System.exit(0);
}
}
6 数据可视化
6.1 可视化工具Gephi
Gephi是一款开源的跨平台的基于JVM的复杂网络分析软件。把PageRank和LPA的结果,转化为gexf格式,在Gephi中绘制图像并分析大数据实验结果,更加直观、易于理解。
gexf实际上是一种特殊的XML文件,python的gexf库提供了接口方便我们编辑和生成gexf文件,因此我们选择使用python处理PageRank和LPA的结果。顶点有两种属性,LPA生成的标签和PageRank计算的PR值,每条边的权重是PageRank计算出的值。在可视化的时候,标签决定顶点显示的颜色,PR值决定标签的
6.2 可视化预处理
编写一个python程序transform2xml.py,将数据分析部分得到的PR值,标签以及点连接关系处理成一个可供Gephi读取的gexf文件。
6.3 可视化结果


7 输出结果截图

7.2 同现次数统计
7.3 归一化输出

7.4 PageRank

7.5 LPA输出结果

生成gexf文件
package com.neuedu;
import it.uniroma1.dis.wsngroup.gexf4j.core.*;
import it.uniroma1.dis.wsngroup.gexf4j.core.data.Attribute;
import it.uniroma1.dis.wsngroup.gexf4j.core.data.AttributeClass;
import it.uniroma1.dis.wsngroup.gexf4j.core.data.AttributeList;
import it.uniroma1.dis.wsngroup.gexf4j.core.data.AttributeType;
import it.uniroma1.dis.wsngroup.gexf4j.core.impl.GexfImpl;
import it.uniroma1.dis.wsngroup.gexf4j.core.impl.StaxGraphWriter;
import it.uniroma1.dis.wsngroup.gexf4j.core.impl.data.AttributeListImpl;
import java.io.*;
import java.util.Calendar;
import java.util.HashMap;
import java.util.Map;
public class App5 {
public static void main(String[] args) throws IOException {
Gexf gexf = new GexfImpl();
Calendar date = Calendar.getInstance();
gexf.getMetadata()
.setLastModified(date.getTime())
.setCreator("Gephi.org")
.setDescription("A Web network");
gexf.setVisualization(true);
Graph graph = gexf.getGraph();
graph.setDefaultEdgeType(EdgeType.UNDIRECTED).setMode(Mode.STATIC);
AttributeList attrList = new AttributeListImpl(AttributeClass.NODE);
graph.getAttributeLists().add(attrList);
Attribute attUrl = attrList.createAttribute("class", AttributeType.INTEGER, "Class");
Attribute attIndegree = attrList.createAttribute("pageranks", AttributeType.DOUBLE, "PageRank");
File file = new File("output25/part-r-00000");
FileReader fileReader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(fileReader);
String line = bufferedReader.readLine();
Map<String,Node> name2Node = new HashMap<>();
//农夫 0.0020768966450448022#丁典:0.5;狄云:0.5
// Map<农夫_丁典,0.5>
Map<String,Double> namePair2Weight = new HashMap<>();
Integer nodeId = 0;
while(line != null)
{
String[] split = line.split("\t");
String[] split1 = split[1].split("#");
//农夫 0.0020768966450448022#丁典:0.5;狄云:0.5
String[] split2 = split1[1].split(";");
//1#zhangsan
String[] arr = split[0].split("#");
for(String string : split2)
{
//丁典:0.5
String[] split3 = string.split(":");
namePair2Weight.put(arr[1] + "_" + split3[0], Double.parseDouble(split3[1]));
}
Node node = graph.createNode(nodeId.toString());
nodeId++;
node.setLabel(arr[1])
.getAttributeValues()
.addValue(attUrl, arr[0])
.addValue(attIndegree, split1[0]);
name2Node.put(arr[1],node);
line = bufferedReader.readLine();
}
int edgeID = 0;
for(Map.Entry<String,Double> entry : namePair2Weight.entrySet())
{
//农夫_丁典
String namePair = entry.getKey();
String[] split = namePair.split("_");
Node node1 = name2Node.get(split[0]);
Node node2 = name2Node.get(split[1]);
node1.connectTo(String.valueOf(edgeID++),node2).setWeight(Float.parseFloat(entry.getValue().toString()));
}
StaxGraphWriter graphWriter = new StaxGraphWriter();
File f = new File("static_graph_sample.gexf");
Writer out;
try {
out = new FileWriter(f, false);
graphWriter.writeToStream(gexf, out, "UTF-8");
System.out.println(f.getAbsolutePath());
} catch (IOException e) {
e.printStackTrace();
}
}
}