总目录:

文档笔记见:百度网盘/大数据资料
1.1 软件准备说明
所需软件如下图所示:

大数据插架都在于此:http://archive.apache.org/dist
Hadoop3.1.0的地址:http://archive.apache.org/dist/hadoop/core/hadoop-3.1.0/
Jdk:https://download.csdn.net/download/micholas_net/10488056
或者百度网盘:”开发用到的工具/”这个目录下
1.2 预备工作
1.2.1 关闭防火墙
Centos6.5 防火墙的命令:
只用root用户才能对防火墙进行操作:
Service iptables status
Service iptables stop;
Service iptables restart;
对于centos7自带的防火墙的相关指令:
systemctl stop firewalld.service #停止firewall
systemctl disable firewalld.service #禁止firewall开机启动
systemctl status firewalld.service #查看firewall的状态
1.2.2 修改主机名
Vim /etc/sysconfig/network #修改主机名
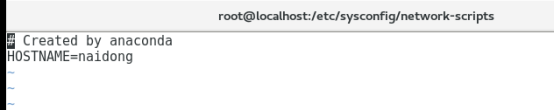
Centos7 特有的修改主机的方式:
hostnamectl set-hostname naidong #永久性,并且立即生效
如图:

1.2.3 修改主机ip
BOOTPROTO的方式有:none 不设置;dhcp 动态获取;static 静态配置
- dhcp动态获取方式
Vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="dhcp"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="faae9218-1e5c-41c2-be4d-954e08f47970"
DEVICE="ens33"
ONBOOT="yes"
- 不指定方式
Vim /etc/sysconfig/network-scripts/ifcfg-eth0 #修改ip
DEVICE=eth0
TYPE=Ethernet
UUID=53bf9bda-633b-480f-b006-a43e0a3ce113
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=none #none不指定,dhcp,动态获取,static静态获取
#BOOTPROTO=static
IPADDR=192.168.2.121
NETMASK=255.255.255.0
DNS1=192.168.2.1
BROADCAST=192.168.2.1
ARPCHECK=no
#GATEWAY=192.168.2.255
PREFIX=24
DEFROUTE=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
NAME="System eth0"
HWADDR=00:22:68:17:03:C9
GATEWAY=192.168.2.1
LAST_CONNECT=1461421962
1.2.4 ip与主机名之间的映射
Vim /etc/hosts #修改主机名和ip的关联映射

查看主机名:

还是没有改变,重新启动系统,输入:reboot
root@localhost ~]# hostname
naidong
[root@localhost ~]#
注意:以上操作配置完成后,需要重新启动机器,让配置生效!!!
1.3 环境的配置
1.3.1 将安装包上传到指定的文件夹下
1.将 hadoop-3.1.0.tar.gz 放到/usr/local/hadoop (hadoop目录自己创建)
2.将jdk1.8 放到/usr/local/java目录下(java目录自己创建)
3.解压命令为:tar -zxvf xxxx.tar.gz
1.3.2 jdk,hadoop环境变量的配置
Vim /etc/profile
#jdk
export JAVA_HOME=/usr/local/java/jdk1.8.0_171
export JRE_HOME=/usr/local/java/jdk1.8.0_171/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HONE/lib/:$CLASSPATH
export PATH=$JAVA_HOME/bin/:$PATH
#hadoop
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
配置完成后,让其立即生效: sourc /etc/profile
1.3.3 验证jdk安装是否成功
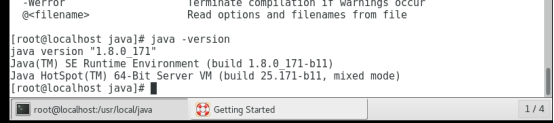
1.3.4 验证hadoop的环境变量是否成功
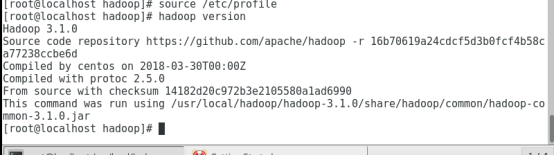
1.4 ssh免密码登陆
1.4.1 unbuntu版本的配置
安装ssh命令: sudo apt-get install ssh #centos系统不支持apt-get命令
安装完成后,生成密钥,ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1、创建ssh-key,,这里我们采用rsa方式
ssh-keygen -t rsa -P "" //(P是要大写的,后面跟"")

(注:回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的)
2、进入~/.ssh/目录下,将id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的,执行下面的命令自动生成
Cd ~/.ssh
cat id_rsa.pub >> authorized_keys

验证是否成功:Ssh localhost
可以看到不用再输入密码了,即配置成功!
1.4.2 centos版本的配置
1进入root的的主目录: cd ~;

2进入到root主目录下,查看.shh文件夹: ls -la
注意:centos7 是没有.ssh文件夹的,需要自己创建.ssh文件夹;而centos6.5默认是存在的

3执行生成公钥私钥文件的命令:
ssh-keygen -t rsa #输入该命令后,紧接着让输入一些东西,选择忽略,敲回车就行,可以看到生成了两个文件:id_rsa, id_rsa.pub;

4将id_rsa.pub文件的内容追加到authorized_keys文件中:
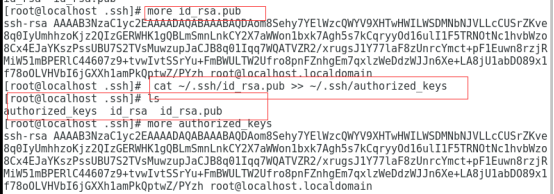
5执行ssh 测试

提示是否建立连结:选择yes
再次执行:ssh localhost
![]()
1.5 hadoop配置文件
进入$HADOOP_HOME/etc/hadoop目录,配置 hadoop-env.sh等。涉及的配置文件如下:
Core-site.xml,hdfs-site.xml,mapred-site.xml,yarn-site.xml 的配置均配置在<configuration></configuration>标签中。
1.5.1 hadoop-env.sh
export JAVA_HOME=/usr/local/java/jdk1.8.0_171

1.5.2 core-site.xml
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.10.90:9000</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/hadoop_tmp</value>
</property>
如图:

1.5.3 hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/namedir/</value>
</property>
<!-- Configurations for DataNode: -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/datadir/</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
如图:

1.5.4 mapred-site.xml
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name> <value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
如图:

1.5.5 yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
如图:

1.6 格式化文件系统
root@ubuntu:/usr/local/hadoop/hadoop-3.1.0/bin# hdfs namenode -format

当看到xxxx has been successfully formatted;格式化成功!
1.7 启动hadoop
1.root@ubuntu:/usr/local/hadoop/hadoop-3.1.0/sbin# ./start-all.sh
如果运行脚本报如下错误,
ERROR: Attempting to launch hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting launch.
Starting datanodes
ERROR: Attempting to launch hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting launch.
Starting secondary namenodes [localhost.localdomain]
ERROR: Attempting to launch hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting launch.
需要在start-dfs.sh 和stop-dfs.sh的开头处,在顶部空白处添加内容:
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
在start-yarn.sh和stop-yarn.sh的顶部空白处添加内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
最后执行:./start-all.sh
Unbutun版本:

Centos 07版本:

从以上可以看出启动顺序为:1.namenode;2.datanode;3.secondary namenode;4.resource manager;5.nodemanager
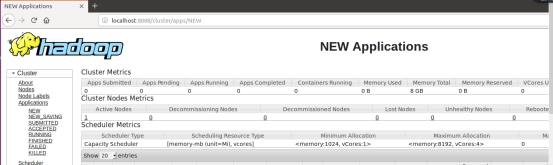
2.输入地址:http://localhost:8088/cluster/apps/NEW
3.输入地址:http://localhost:9870/

注意:第一次格式化文件系统后,第二次格式化文件系统,容易造成启动后datanode没有进程
解决办法为:删除hdfs-site.xml中指定的name和data的文件夹,重新启动hadoop
hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/namedir/</value>
</property>
<!-- Configurations for DataNode: -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/datadir/</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>