周志华《机器学习》 学习笔记
最近开始学习机器学习,参考书籍西瓜书,做点笔记。
第十三章 半监督学习
13.1 未标记样本
让学习器不依赖外界交互、自动的利用未标记样本来提升学习性能,就是半监督学习;
聚类假设:假设数据存在簇结构,同一个簇的样本属于同一个类别;
流形假设:假设数据分布在一个流行结构上,邻近的样本拥有相似的输出值;
半监督学习可进一步分为纯半监督学习和直推学习;
纯半监督学习:假定训练数据中的未标记样本并非待预测的数据,学得的模型能使用与训练过程中未观察到的数据;
直推学习:假定学习过程中所考虑的未标记样本恰是带预测数据,学习过程中观察到的未标记数据进行预测;
13.2 生成式方法
生成式方法是直接基于生成式模型的方法,此类方法假设所有数据都由同一个潜在的模型生成的,无论是否有标记;
未标记数据的标记可以看做模型的缺失参数;
假定样本由高斯混合模型生成,且每个样本对应一个高斯混合成分,概率密度为:;
最大化后验概率:;
其中
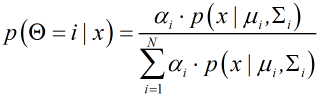
为x由第i个高斯混合成分生成且其类别为j的概率;
可以看出需要样本的标记,而
不需要样本的标记,因此均可利用有标记和无标记的样本,样本数量增加估计更为准确;
通过EM算法可求出高斯混合模型的参数估计,过程见书上;
优点:简单,数据少的情况效果好;缺点:需要模型准确。
13.3 半监督SVM
半监督支持向量机是在支持向量机的基础上推广,思路和SVM一致,即找到穿过数据低密度区域的划分超平面,其中最著名的是TSVM;
TSVM针对二分类问题,对未标记样本金性可能的标记指派,然后用这些结果群找一个所有样本上的间隔最大化的超平面;
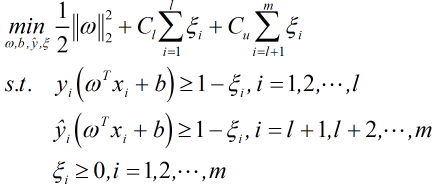
TSVM采用局部搜索来迭代的寻找上式近似解;
步骤:1.利用有标记样本训练出一个SVM;
2.用学得的SVM预测未标记样本;
3.将样本代入上式得到一个超平面;
4.找出两个错误可能大的异分类样本;
5.交换两个样本标记,重新求得超平面;
6.重复上面两步直到参数Cu=Cl;
其中第4步的错误可能大判断标准:一对样本指派标记不同,且对应的松弛变量之和大于2;
13.4 图半监督学习
这一节有点难,理解不是很明白;
13.5 基于分歧的方法
基于分歧的方法使用多学习器,学习器之间的分歧对未标记数据的利用至关重要;
视图:一个数据对象拥有多个属性集,每个属性集就构成了一个视图;
视图相容性:所包含的关于输出空间Y的信息一致,例如Y1表示从图像画面信息判别的标记空间,Y2表示从声音信息判别的标记空间,则相容性为Y=Y1=Y2;
协同训练正式利用了多视图的相容互补性;
充分:每个视图都包含足以产生最优学习器的信息;条件独立:给定类别标记条件下的两个视图独立;
步骤:1.对每个视图上有标记的样本训练出一个分类器;
2.让每个分类器挑选未标记样本,标记伪标记;
3.将未标记样本提供给另一个分类器作为新增的有标记样本用于训练更新;
优点:只需用合适的基分类器;缺点:标记样本很少不容易实现;
13.6 半监督聚类
监督任务类型:必连(样本比属于同一个簇)与勿连(样本必不属于同一个簇)约束、监督信息则是少量的有标记样本;
具体算法分类见书上;
第十三章半监督学习类似于监督学习的扩展,在以前的知识基础上进行扩充,大体思路不变,其中的图半监督学习这一节确实没理解到,可能是知识储备不够吧。总体上来说这一章书上讲解的大部分能理解,在实践操作中再补充相关理论知识。
我的笔记做的比较粗糙,还请见谅。