机器学习100天系列学习笔记基于机器学习100天(中文翻译版),机器学习100天(英文原版)
所有代码使用iPython Notebook实现
目录
实验综述


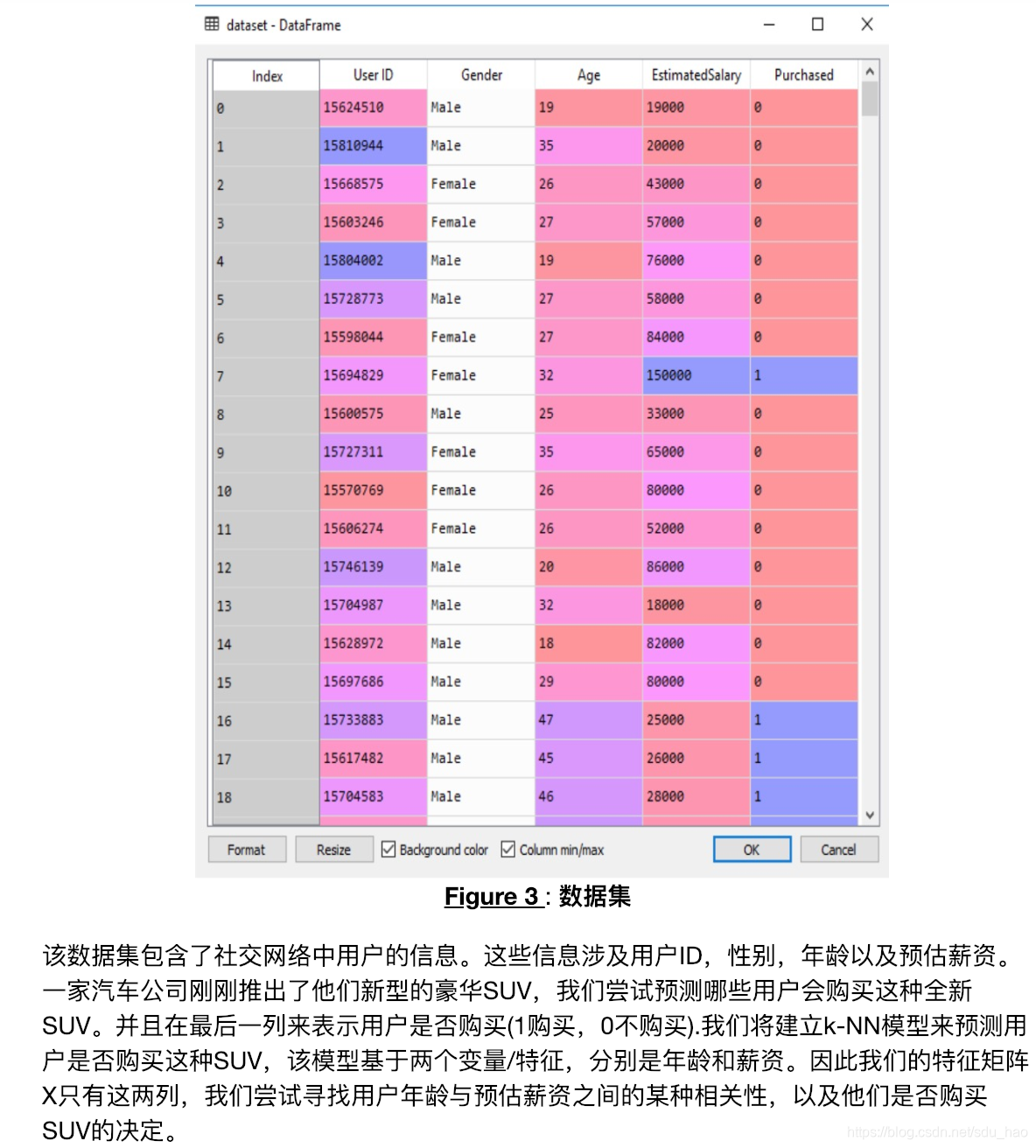
数据集
1.数据预处理

'''1. 导入相关库'''
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
'''2. 导入数据集'''
data = pd.read_csv('Social_Network_Ads.csv')
print(data.head())
#分离特征矩阵X和标签向量Y
X = data.iloc[:,2:-1].values #只使用年龄和预估薪资两个特征
Y = data.iloc[:,-1].values
'''3. 检查缺失数据'''
#没有缺失数据
'''4. 解析分类数据'''
#没有分类数据 不需要数字化/转化one-hot编码
'''5. 避免虚拟变量陷阱'''
#没有虚拟变量
'''6. 分割数据集为训练集和测试集'''
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.25,random_state=0)
'''7. 特征缩放'''
from sklearn.preprocessing import StandardScaler
#实例化StandardScaler类的对象
sc = StandardScaler()
#用对象调用类内的特征缩放方法
X_train = sc.fit_transform(X_train)
X_test = sc.fit_transform(X_test)
2.使用k-NN对训练集进行训练
#导入kNN分类器类
from sklearn.neighbors import KNeighborsClassifier
#实例化类对象 指定k值/距离度量方式
classifier = KNeighborsClassifier(n_neighbors = 5,metric='minkowski',p=2)
#训练
classifier = classifier.fit(X_train,Y_train) #classifier.fit(X_train,Y_train)3.对测试集进行预测
#用训练好的模型在测试集上预测
y_pred = classifier.predict(X_test)4.生成混淆矩阵
#评估模型效果
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(Y_test,y_pred)
print(cm)
#计算准确率
num_correct = np.sum(Y_test==y_pred)
accuracy = float(num_correct)/len(y_pred)
print(accuracy)