

K-NN(K-nearest neighbor)是一种分类算法,也可以用于回归,它无参数学习,在有监督的情况下,查看当前数据距离k个离它较近的其他数据中,最多的数据类别就是当前数据的类别。所以K-NN也被称为惰性算法,是基于实例的。
1.基于实例的学习
1.不同于我们之前学到的逻辑回归、线性回归,都是在训练集一定的情况下,去模拟真实函数的模型,输入特征对照正确输出。但是基于实例的学习就是讲数据简单的存储了起来。从数据当中逼近真实函数的工作变成了只有分新的数据时,分析这个数据和之前数据之间的关系,然后将数据进行目标函数赋值。
2.基于实例的方法,可以为不同的实例建立不同的目标函数逼近。
3.基于实例方法的不足有,因为模型没有对真实的数据的逼近函数,也就没有了训练好的固定模型可以直接预测新的数据,每一个新的数据都要进行一遍运算,所以开销很大。
2.KNN 原理
K-NN是基于实例学习方法最基本的。所有的实例对应着N维的欧式空间,通过计算一个点与其他所有点之间的距离,取出与该点最近的K个点,然后统计这K个点里面所属分类比例最大的,则这个点属于该分类。
输入:训练数据集T={(x1,y1),(x2,y2),…,(xn,yn)}T={(x1,y1),(x2,y2),…,(xn,yn)},其中xi∈Rn,yi∈{c1,c2,…,cK}xi∈Rn,yi∈{c1,c2,…,cK}和测试数据xx
输出:实例x所属的类别
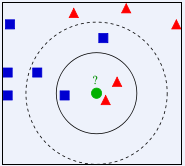
上图中我们可以看到,特征空间内有两种分类,三角形和方形,新进来的数据是圆形,如果k=3,则分为三角形,如果k=5则分成方形。所以KNN中三个要素,第一个是数据集、样本向量化、距离如何计算、K值如何选择。
数据集:带标签的训练集。
样本向量化:样本的特征要使用数值的形式,通过向量表示,是量化的,可以进行比较的。
距离计算:常用的方法有,欧式距离、余弦距离、汉明距离、曼哈顿距离,闵可夫斯基距离。
3.距离度量
闵可夫斯基距离:
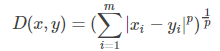
P=2是欧式距离、P=1是曼哈顿距离
4.K的选择
K的选择对模型的影响非常大,在应用中,一般选择较小k并且k是奇数。通常采用交叉验证的方法来选取合适的k值。
5.代码:
import pandas as pd
import numpy as np
1)数据导入
data = pd.read_csv(‘Social_Network_Ads.csv’,encoding=‘utf-8’)
X = data.iloc[ : , [2,3]].values
Y = data.iloc[ : , -1].values
2)缺失值处理
print(data.info())

3)特征缩放
from sklearn.preprocessing import StandardScaler
stand = StandardScaler()
X = stand.fit_transform(X)
4)数据集划分
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test = train_test_split(X,Y,test_size=0.2,random_state= 0)
5)构建模型
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier( n_neighbors=5,metric=‘minkowski’,p = 2)
classifier.fit(X_train,Y_train)
6)测试集
y_pred = classifier.predict(X_test)
7)混淆矩阵生成
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(Y_test,y_pred)
print(cm)