版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/fragrant_no1/article/details/86309767
订单数据:
订单编号,商品编号,金额
10000,p1,100
10000,p2,230
10001,p1,120
10001,p2,650
10001,p3,101
10002,p1,102
分析
-
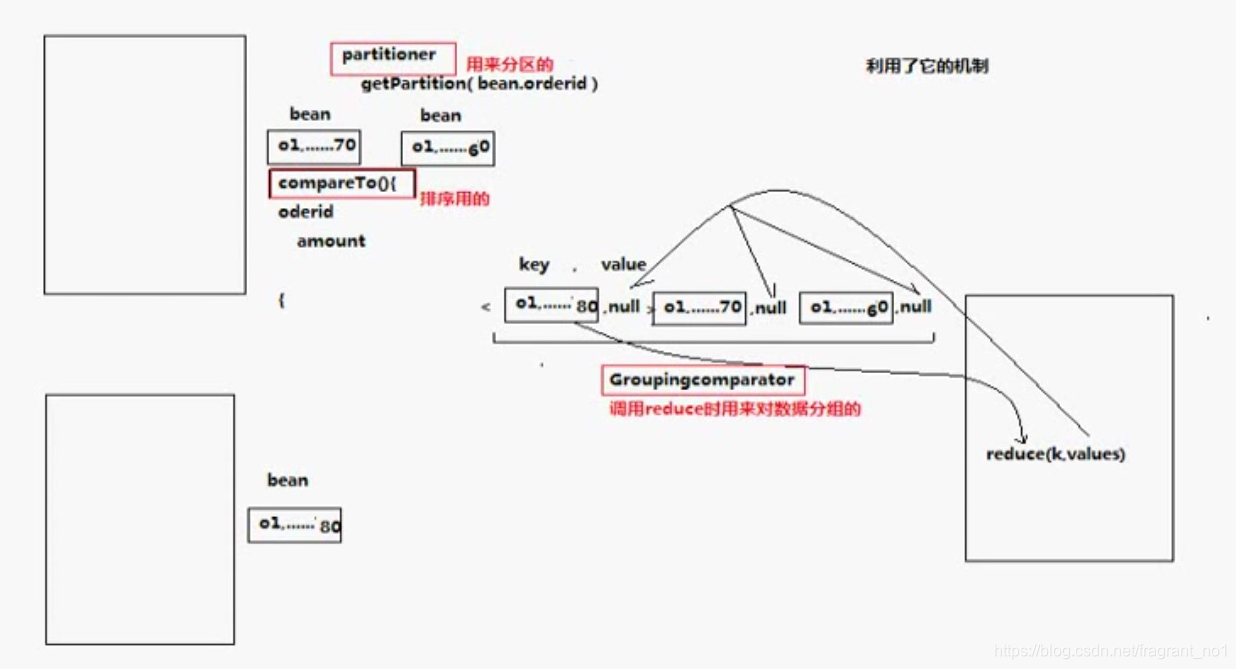
订单的排序问题
从高效的方面出发,最好用框架以有的功能来实现,maptask自带排序功能,但是默认的排序不满足需求,所以需要自定义comparaTo,按照订单号,统一订单下的金额来排序。 -
分区问题
因为默认分区是按照key的hashCode值来分区的,但是不同对象的hashCode值是不同的,不能按照订单号相同来分区,所以需要自定义分区规则,这里使用partitioner,按照订单号的hashCode来进行分区。 -
分组问题
reducetask中会对数据按照key进行分组,但是如果封装成对象是无法按照订单号来默认分组的,因为不同对象是不同的组,所以需要自定义分组规则,这里使用GroupingComparator,自定义按照订单号来分组。
代码实现
package com.example.demo.ordermax;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Partitioner;
/**
* maptask中的分区组件
*/
public class OrderPartitioner extends Partitioner<OrderBean,NullWritable> {
//根据订单号的hashCode值对reduce个数取模,这样可以保证相同订单号的对象被分配到同一个reduce中去
@Override
public int getPartition(OrderBean orderBean, NullWritable nullWritable, int reduceTasks) {
//&操作是截取位/长度
//相同id的订单bean,会发往相同的partition,而且,产生的分区数,是会跟用户设置的reduce task数保持一致
return (orderBean.getOrderId().hashCode() & Integer.MAX_VALUE) % reduceTasks;
}
}
package com.example.demo.ordermax;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
/**
* reducetask 中用于分组的
* 自定义实现将一组bean(订单号相同的)看成相同的key
*/
public class OrderGroupingComparet extends WritableComparator {
//传入作为key的bean的class类型,以及制定需要让框架做反射获取实例对象然后比较-这个方法必须要有,不然无法自定义分组
protected OrderGroupingComparet() {
super(OrderBean.class, true);
}
/**
* 用于实际比较分组的方法
* WritableComparable 就是反序列化之后的对象
*/
@Override
public int compare(WritableComparable a, WritableComparable b) {
OrderBean a1 = (OrderBean) a;
OrderBean b1 = (OrderBean) b;
//比较两个bean时,指定只比较bean中的orderid
return a1.getOrderId().compareTo(b1.getOrderId());
}
}
package com.example.demo.ordermax;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Objects;
public class OrderBean implements WritableComparable<OrderBean> {
private String orderId;
private String pid;
private int sumMoney;
//反序列化的时候使用
public OrderBean() {
}
public void set(String orderId, String pid, int sumMoney) {
this.orderId = orderId;
this.pid = pid;
this.sumMoney = sumMoney;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getPid() {
return pid;
}
public void setPid(String pid) {
this.pid = pid;
}
public int getSumMoney() {
return sumMoney;
}
public void setSumMoney(int sumMoney) {
this.sumMoney = sumMoney;
}
/**
* 返回>0 的值代表用升序排列,反之用降序排列
* 溢出,溢出的小文件合并,reducetask分组 这个过程中都会通过key进行排序
*/
@Override
public int compareTo(OrderBean o) {
//先订单比较,升序
String orderId = o.getOrderId();
int flag = this.orderId.compareTo(orderId);
//订单相同后金额比较,降序
if(flag == 0){
flag = this.sumMoney > o.getSumMoney() ? -1 : 1;
}
return flag;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(orderId);
dataOutput.writeUTF(pid);
dataOutput.writeInt(sumMoney);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
this.orderId = dataInput.readUTF();
this.pid = dataInput.readUTF();
this.sumMoney = dataInput.readInt();
}
@Override
public String toString() {
return "OrderBean{" +
"orderId='" + orderId + '\'' +
", pid='" + pid + '\'' +
", sumMoney=" + sumMoney +
'}';
}
}
package com.example.demo.ordermax;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* 效率上考虑
* 高(能让框架做的,那么效率就高)
* 低(自己写逻辑mapreduce的相对低)
*/
public class OrderMax {
static class OrderMaxMap extends Mapper<LongWritable,Text,OrderBean,NullWritable>{
private OrderBean bean = new OrderBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
bean.set(split[0], split[1], Integer.parseInt(split[2]));
context.write(bean,NullWritable.get());
}
}
static class OrderMaxReduce extends Reducer<OrderBean,NullWritable,OrderBean,NullWritable>{
//到达reduce时,相同orderId的所有bean已经被看成一组,且金额最大的那个一排在第一位
@Override
protected void reduce(OrderBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key,NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(OrderMax.class);
job.setMapperClass(OrderMaxMap.class);
job.setReducerClass(OrderMaxReduce.class);
job.setMapOutputKeyClass(OrderBean.class);
job.setMapOutputValueClass(NullWritable.class);
job.setOutputKeyClass(OrderBean.class);
job.setOutputValueClass(NullWritable.class);
//数据源目录
FileInputFormat.setInputPaths(job,new Path("E:/abc"));
//结果输出目录
FileOutputFormat.setOutputPath(job,new Path("E:/abc/output"));
//在此设置自定义的Groupingcomparator类
job.setGroupingComparatorClass(OrderGroupingComparet.class);
//在此设置自定义的partitioner类
job.setPartitionerClass(OrderPartitioner.class);
//自定义reducetask个数
job.setNumReduceTasks(2);
boolean b = job.waitForCompletion(true);
System.exit(b?0:1);
}
}
说明:
这里跑的是本地模式而不是集群模式