【解读】全卷积网络 Fully Convolutional Networks
该论文包含了当下CNN的三个思潮
-
不含全连接层(fc)的全卷积(fully conv)网络。可适应任意尺寸输入。
-
增大数据尺寸的反卷积(deconv)层。能够输出精细的结果。
-
结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
一些重点:
-
损失函数是在最后一层的 spatial map上的 pixel 的 loss 之和,在每一个 pixel 使用 softmax loss
-
8s使用 skip 结构融合多层(3层)输出,底层网络应该可以预测更多的位置信息,因为他的感受野小可以看到小的 pixels
-
上采样 lower-resolution layers 时,如果采样后的图因为 padding 等原因和前面的图大小不同,使用 crop ,当裁剪成大小相同的,spatially aligned ,使用 concat 操作融合两个层
CNN 与 FCN
通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述(概率),比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率(softmax归一化)。
栗子:下图中的猫, 输入AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高。

FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。下图是Longjon用于语义分割所采用的全卷积网络(FCN)的结构示意图:

FCN将传统CNN中的全连接层转化成一个个的卷积层。如下图所示,在传统的CNN结构中,前5层是卷积层,第6层和第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别的概率。FCN将这3层表示为卷积层,卷积核的大小(通道数,宽,高)分别为(4096,1,1)、(4096,1,1)、(1000,1,1)。所有的层都是卷积层,故称为全卷积网络。
简单的来说,FCN与CNN的区域在把于CNN最后的全连接层换成卷积层,输出的是一张已经Label好的图片。

其实,CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部区域的特征;较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于识别性能的提高。下图CNN分类网络的示意图:

这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体,但是因为丢失了一些物体的细节,不能很好地给出物体的具体轮廓、指出每个像素具体属于哪个物体,因此做到精确的分割就很有难度。
传统的基于CNN的分割方法:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法有几个缺点:一是存储开销很大。例如对每个像素使用的图像块的大小为15x15,然后不断滑动窗口,每次滑动的窗口给CNN进行判别分类,因此则所需的存储空间根据滑动窗口的次数和大小急剧上升。二是计算效率低下。相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。三是像素块大小的限制了感知区域的大小。通常像素块的大小比整幅图像的大小小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。
而全卷积网络(FCN)则是从抽象的特征中恢复出每个像素所属的类别。即从图像级别的分类进一步延伸到像素级别的分类。
网络结构如下。输入可为任意尺寸图像彩色图像;输出与输入尺寸相同,深度为:20类目标+背景=21。 (在PASCAL数据集上进行的,PASCAL一共20类).

虚线上半部分为全卷积网络。(蓝:卷积,绿:max pooling)。对于不同尺寸的输入图像,各层数据的尺寸(height,width)相应变化,深度(channel)不变。
这部分由深度学习分类问题中经典网络AlexNet修改而来。只不过,把最后两个全连接层(fc)改成了卷积层。
全连接层 -> 全卷积层
全连接层和卷积层之间唯一的不同就是卷积层中的神经元只与输入数据中的一个局部区域连接,并且在卷积列中的神经元共享参数。然而在两类层中,神经元都是计算点积,所以它们的函数形式是一样的。因此,将此两者相互转化是可能的:
-
对于任一个卷积层,都存在一个能实现和它一样的前向传播函数的全连接层。权重矩阵是一个巨大的矩阵,除了某些特定块,其余部分都是零。而在其中大部分块中,元素都是相等的。
-
相反,任何全连接层都可以被转化为卷积层。比如,一个 K=4096 的全连接层,输入数据体的尺寸是 7∗7∗512,这个全连接层可以被等效地看做一个 F=7,P=0,S=1,K=4096 的卷积层。换句话说,就是将滤波器的尺寸设置为和输入数据体的尺寸一致了。因为只有一个单独的深度列覆盖并滑过输入数据体,所以输出将变成 1∗1∗4096,这个结果就和使用初始的那个全连接层一样了。
全连接层转化为卷积层:在两种变换中,将全连接层转化为卷积层在实际运用中更加有用。假设一个卷积神经网络的输入是 224x224x3 的图像,一系列的卷积层和下采样层将图像数据变为尺寸为 7x7x512 的激活数据体。AlexNet使用了两个尺寸为4096的全连接层,最后一个有1000个神经元的全连接层用于计算分类评分。我们可以将这3个全连接层中的任意一个转化为卷积层:
-
针对第一个连接区域是[7x7x512]的全连接层,令其滤波器尺寸为F=7,这样输出数据体就为[1x1x4096]了。
-
针对第二个全连接层,令其滤波器尺寸为F=1,这样输出数据体为[1x1x4096]。
-
对最后一个全连接层也做类似的,令其F=1,最终输出为[1x1x1000]
实际操作中,每次这样的变换都需要把全连接层的权重W重塑成卷积层的滤波器。那么这样的转化有什么作用呢?它在下面的情况下可以更高效:让卷积网络在一张更大的输入图片上滑动,得到多个输出,这样的转化可以让我们在单个向前传播的过程中完成上述的操作。
举个栗子:如果我们想让224×224尺寸的浮窗,以步长为32在384×384的图片上滑动,把每个经停的位置都带入卷积网络,最后得到6×6个位置的类别得分。上述的把全连接层转换成卷积层的做法会更简便。如果224×224的输入图片经过卷积层和下采样层之后得到了[7x7x512]的数组,那么,384×384的大图片直接经过同样的卷积层和下采样层之后会得到[12x12x512]的数组。然后再经过上面由3个全连接层转化得到的3个卷积层,最终得到[6x6x1000]的输出((12 – 7)/1 + 1 = 6)。这个结果正是浮窗在原图经停的6×6个位置的得分!
面对384×384的图像,让(含全连接层)的初始卷积神经网络以32像素的步长独立对图像中的224×224块进行多次评价,其效果和使用把全连接层变换为卷积层后的卷积神经网络进行一次前向传播是一样的。
Evaluating the original ConvNet (with FC layers) independently across 224x224 crops of the 384x384 image in strides of 32 pixels gives an identical result to forwarding the converted ConvNet one time.
训练过程
训练过程分为四个阶段,也体现了作者的设计思路,值得研究,下图以在pascal-voc数据集上训练为例。
第一阶段

以经典的分类网络为初始化。最后两级是全连接(红色),参数弃去不用。
第二阶段

从特征小图(16*16*4096)预测分割小图(16*16*21),之后直接32倍率上采样为大图。
反卷积(橙色)的步长为32,这个网络称为FCN-32s。
这一阶段使用单GPU训练约需3天。
第三阶段

上采样分为两次完成(橙色×2)。
在第二次上采样前,把第4个pooling层(绿色)的预测结果(蓝色)融合进来。使用跳级结构提升精确性。
第二次反卷积步长为16,这个网络称为FCN-16s。
这一阶段使用单GPU训练约需1天。
第四阶段

上采样分为三次完成(橙色×3)。
进一步融合了第3个pooling层的预测结果。
第三次反卷积步长为8,记为FCN-8s。
这一阶段使用单GPU训练约需1天。
较浅层的预测结果包含了更多细节信息。比较2,3,4阶段可以看出,跳级结构利用浅层信息辅助逐步升采样,有更精细的结果。

反卷积-上采样(DeConvolution-upsampling)
转置卷积的使用场景
1. CNN可视化,通过反卷积将卷积得到的feature map还原到像素空间,来观察feature map对哪些pattern相应最大,即可视化哪些特征是卷积操作提取出来的;
2. FCN全卷积网络中,由于要对图像进行像素级的分割,需要将图像尺寸还原到原来的大小,类似upsampling的操作,所以需要采用反卷积;
3. GAN对抗式生成网络中,由于需要从输入图像到生成图像,自然需要将提取的特征图还原到和原图同样尺寸的大小,即也需要反卷积操作。

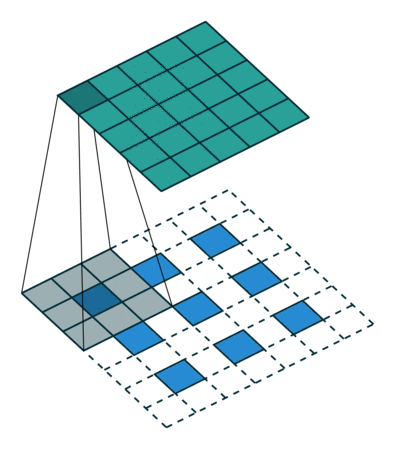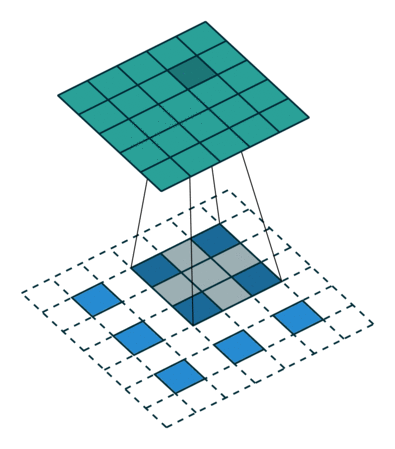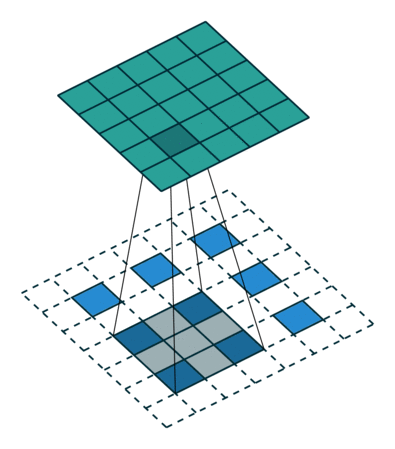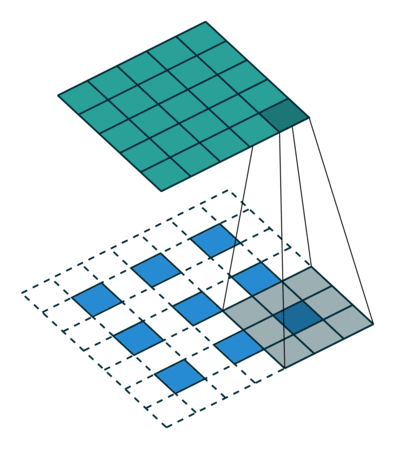
合并
如下图所示,对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时图像不再叫featureMap而是叫heatMap。
现在我们有1/32尺寸的heatMap,1/16尺寸的featureMap和1/8尺寸的featureMap,1/32尺寸的heatMap进行upsampling操作之后,因为这样的操作还原的图片仅仅是conv5中的卷积核中的特征,限于精度问题不能够很好地还原图像当中的特征,因此在这里向前迭代。把conv4中的卷积核对上一次upsampling之后的图进行反卷积补充细节(相当于一个差值过程),最后把conv3中的卷积核对刚才upsampling之后的图像进行再次反卷积补充细节,最后就完成了整个图像的还原。

缺点
在这里我们要注意的是FCN的缺点:
-
是得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
-
是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
总结
-
想要精确预测每个像素的分割结果,必须经历从大到小,再从小到大的两个过程
-
在上采样过程中,分阶段增大比一步到位效果更好
-
在上采样的每个阶段,使用降采样对应层的特征进行辅助