前言
异常检测首先不是检测机器学习算法中的异常,也不是一个算法,它指的是一种应用场景(刚开始时我也陷入这两种猜测。。。)比如在工厂内生产一批零件,我们用高斯分布的方法来预测新生产的零件的异常状况。这就是本章学习的内容——异常检测
一、高斯分布
正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution),最早由A.棣莫弗在求二项分布的渐近公式中得到。C.F.高斯在研究测量误差时从另一个角度导出了它。P.S.拉普拉斯和高斯研究了它的性质。是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。
正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线。其中u表示均值,σ表示标准差,那么σ2则表示方差。
其中由于高斯分布是一个概率模型,所以图像形成的面积(积分)等于1,而均值u则表示高斯分布的最大分布位置(函数的最大值),方差σ2影响函数的形状(σ2越大正态分布的约扁平)
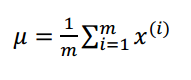
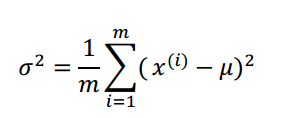

1、问题描述
x1表示引擎运转时产生的热量,x2表示引擎的振动,那么绘制引擎的图像如下示。这里的每个点、每个叉,都是你的无标签数据。这样,异常检测问题可以定义如下:我们假设后来有一天,你有一个新的飞机引擎从生产线上流出,而你的新飞机引擎有特征变量xtest。所谓的异常检测问题就是:我们希望知道这个新的飞机引擎是否有某种异常。这个就是异常检测的应用场景。

2、算法
我们上面也回顾了高斯分布的算法,下面介绍异常检测怎么应用高斯分布求解。一旦我们获得了平均值和方差的估计值,给定新的一个训练实例,根据模型计算 p(x)。其中我们选择一个ε,将p(x) = ε 作为我们的判定边界,当p(x) > ε时预测数据为正常数据,否则为异常
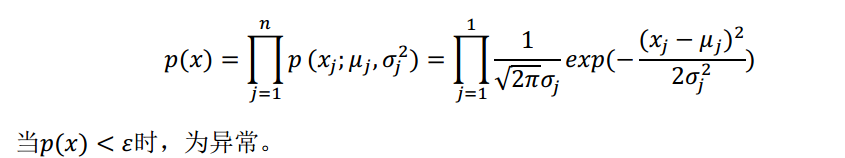
二、异常检测方法应用
1、应用方式
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量 y 的值来告诉我们数据是否真的是异常的。例如:我们有 10000 台正常引擎的数据,有 20 台异常引擎的数据。 我们这样分配数据:
6000 台正常引擎的数据作为训练集
2000 台正常引擎和 10 台异常引擎的数据作为交叉检验集
2000 台正常引擎和 10 台异常引擎的数据作为测试集
具体的评价方法如下:
- 根据测试集数据,我们估计特征的平均值和方差并构建p(x)函数
- 对交叉检验集,我们尝试使用不同的 ε 值作为阀值,并预测数据是否异常,根据 F1 值或者查准率与查全率的比例来选择 ε
- 选出 ε 后,针对测试集进行预测,计算异常检验系统的F1值,或者查准率与查全率之比

2、异常检测与监督学习比较
异常检测和监督学习(logistics回归)有点相似,下面的对比有助于选择采用监督学习还是异常检测

3、特征选择
对于异常检测算法,我们使用的特征是至关重要的,下面谈谈如何选择特征:异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,异常检测算法也能够工作,但是最好还是将数据转换成高斯分布,例如使用对数函数: x = log(x + c),其中 c 为非负常数; 或者 x = xc, c为 0-1 之间的一个分数等方法。

三、多变量的高斯分布
下图中是两个相关特征, 洋红色的线(根据 ε 的不同其范围可大可小) 是一般的高斯分布模型获得的判定边界,很明显绿色的 X 所代表的数据点很可能是异常值,但是其p(x)值却仍然在正常范围内。多元高斯分布将创建像图中蓝色曲线所示的判定边界。

在多元高斯分布模型中,我们将构建特征的协方差矩阵,用所有的特征一起来计算 p(x)。我们首先计算所有特征的平均值,然后再计算协方差矩阵:

原高斯分布模型被广泛使用着,如果特征之间在某种程度上存在相互关联的情况,我们可以通过构造新新特征的方法来捕捉这些相关性。如果训练集不是太大,并且没有太多的特征,我们可以使用多元高斯分布模型。下面是应用高斯分布模型还是多变量的高斯分布模型的比较。

总结
以上就是《吴恩达机器学习》系列视频 异常检测 的内容笔记,以便后续学习和查阅。