https://zhuanlan.zhihu.com/p/35601839
美拍直播首屏耗时减少50%以上的优化实践
![]()
已认证的官方帐号
导读:直播行业的竞争越来越激烈,各厂商对用户体验的追求也越来越高,这其中首屏时间的体验尤为重要。本文中美图的包红来同学从DNS解析优化、TCP连接耗时、HTTP响应耗时、音视频流的探测耗时、buffer缓冲的耗时等五个方面非常详细的解说了美拍直播首屏时间减少50%,达到500ms左右的一个具体优化实践,对做直播的同学非常有借鉴意义。
随着移动直播的火爆,大量的业务都有直播需求,这就使直播成了一种基本的配置。在观看直播过程中,首屏时间是最重要的体验之一,它的快慢直接影响了用户对该直播 APP 的体验。为了提高用户体验性,美拍对 DNS 解析优化、TCP 连接耗时、HTTP 响应耗时、音视频流的探测耗时、buffer 缓冲的耗时等方面进行了优化,使得首屏时间从 2017 年初还是秒级别以上的耗时,到现在是秒级别内,耗时减少 50% 以上,并且大部分请求落在0~500ms 和 500~1000ms 的区间范围,从而使得大部分热门视频达到瞬开的效果。后面我们将基于 ijkplayer 和 ffpmeg 的源码进行分析。
为什么选择ijkplayer播放器来剖析
ijkplayer 播放器是一款开源的基于 ffmpeg 的移动版的播放器,目前已经被很多互联网公司直接采用。它的代码结构比较清晰,很多做移动端视频分析的都应该接触过,所以基于它来分析应该跟容易理解。美拍直播的播放器并不是直接采用 ijkplayer 播放器,但也是基于 ffmpeg 来实现的,逻辑跟 ijkplayer 比较类似,原理上都是相通的,优化点也很类似,只是额外做了一些其他相关点的优化。所以基于 ijkplayer 展开,也方便大家从源码级别可以直接看到相关的关键点。
一、首屏时间的影响因素
首屏时间是指从用户从进入到直播间到直播画面出来的这部分时间,这是观众最简单,直观的体验。它主要受直播播放器和 CDN 加速策略以及移动端手机网络的影响。可以拆分为以下5个方面:
- 点击直播后,进入到直播间后,加载一些比如用户头像,观众列表,礼物之类的会占用网络带宽,影响到直播加载。
- 移动端手机网络带宽的限制,目前一般直播的带宽都在 1Mbps 左右,所以如果下行带宽小于 1Mbps ,或者更小,对直播的体验影响就会很大。
- 直播播放器拉流的速度,以及缓冲策略的控制,对于直播类,实时性的需求更高,需要动态的缓冲控制策略,能尽快的渲染出视频画面,减少用户等待时间。
- CDN 是否有缓存直播流,以及缓存的策略对首屏影响也很大。
- 直播拉流协议的影响,以及 CDN 对不同的协议优化支持友好程度不一样,当前流行的拉流协议主要有 rtmp 和 http-flv。经过大量的测试发现,移动端拉流时在相同的 CDN 策略以及播放器控制策略的条件下,http-flv 协议相比 rtmp 协议,首屏时间要减少 300~400ms 左右。主要是在 rtmp 协议建联过程中,与服务端的交互耗时会更久,所以后面的分析会直接在 http-flv 协议的基础上。
二、首屏耗时的“条分节解”
要想优化首屏时间,就必须清楚的知道所有的耗时分别耗在哪里。下面我们以移动版的 ffplay(ijkplayer)播放器为基础,逐渐剖析直播拉流细节。下面我们以 http-flv 协议为拉流协议分析,http-flv 协议就是专门拉去flv文件流的 http 协议,所以它的请求流程就是一个http 的下载流程,如下图:
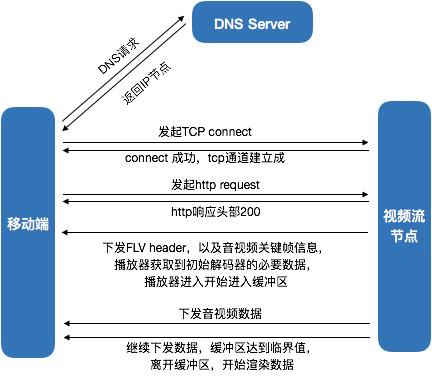
从上图中可以看出,首屏耗时的组成主要有 DNS 耗时、TCP 连接耗时、http 响应耗时、音视频流探测耗时、缓冲耗时5部分组成。
1.DNS耗时
DNS 解析,是所有网络请求的第一步,在我们用基于ffmpeg 实现的播放器 ffplay 中,所有的 DNS 解析请求都是 ffmpeg 调用 getaddrinfo 方法来获取的。
1)一般耗时多久?
如果在没有缓存的情况下,实测发现一次域名的解析会花费至少 300ms 左右的时间,有时候更长,如果本地缓存命中,耗时很短,几个 ms 左右,可以忽略不计。缓存的有效时间是在 DNS 请求包的时候,每个域名会配置对应的缓存 TTL 时间,这个时间不确定,根据各域名的配置,有些长有些短,不确定性比较大。
2)为什么是这么久?
为什么 DNS 的请求这么久呢,一般理解,DNS 包的请求,会先到附近的运营商的 DNS 服务器上查找,如果没有,会递归到根域名服务器,这个耗时就很久。一般如果请求过一次,这些服务器都会有缓存,而且其他人也在不停的请求,会持续更新,下次再请求的时候就会比较快。有时候通过抓包发现每次请求都会去请求 A 和 AAAA 查询,这是去请求 IPv6 的地址,但由于我们的域名没有 IPv6 的地址,所以每次都要回根域名服务器去查询。为什么会请求 IPV6 的地址呢,因为 ffmpeg 在配置 DNS 请求的时候是按如下配置的:
hints.ai_family = AF_UNSPEC;
它是一个兼容 IPv4 和 IPv6 的配置,如果修改成 AF_INET ,那么就不会有 AAAA 的查询包了。通过实测发现,如果只有 IPv4 的请求,即使是第一次,也会在 100ms 内完成,后面会更短。这个地方的优化空间很大。
3)如何统计?
以ffmpeg 为例,可以在 libavformat/tcp.c 文件中, tcp_open 方法中,按以下方法统计:以ffmpeg 为例,可以在 libavformat/tcp.c 文件中, tcp_open 方法中,按以下方法统计:
int64_t start = av_gettime();
if (!hostname[0])
ret = getaddrinfo(NULL, portstr, &hints, &ai);
else
ret = getaddrinfo(hostname, portstr, &hints, &ai);
int64_t end = av_gettime();
2.TCP连接耗时
TCP 连接在这里是只调用 Socket 的 connect 方法,并连接成功的耗时,它是一个阻塞方法,它会一直等待 TCP 的三次握手完成。它直接反应了客户端到 CDN 服务器节点,点对点的延时情况,实测在一般的 wifi 网络环境下耗时在 50ms 以内。耗时较短,基本是没有什么优化空间的,不过它的时间反应了客户端的网络情况或者客户端到节点的网络情况。
1)如何统计?
以ffmpeg为例,也是在 libavformat/tcp.c 文件中, tcp_open 方法中,按以下方法统计:
int64_t start = av_gettime();
if ((ret = ff_listen_connect(fd, cur_ai->ai_addr, cur_ai->ai_addrlen,
s->open_timeout / 1000, h, !!cur_ai->ai_next)) < 0) {
if (ret == AVERROR_EXIT)
goto fail1;
else
goto fail;
}
int64_t end = av_gettime();
3.http响应耗时
1)什么是http响应耗时?
http 响应耗时是指客户端发起一个 http request 请求,然后等待 http 响应的header 返回这部分耗时。直播拉流 http-flv 协议也是一个 http 请求,客服端发起请求后,服务端会先将 http 的响应头部返回,不带音视频流的数据,响应码如果是 200 ,表明视频流存在,紧接着就开始下发音视频数据。
http 响应耗时非常重要,它直接反应了 CDN 服务节点处理请求的能力。它与CDN 节点是否有缓存这条流有关,如果在请求之前有缓存这条流,节点就会直接响应客户端,这个时间一般也在 50ms 左右,最多不会超过 200ms ,如果没有缓存,节点则会回直播源站拉取直播流,耗时就会很久,至少都在 200ms 以上,大部分时间都会更长,所以它反应了这条直播流是否是冷流和热流,以及 CDN 节点的缓存命中情况。
2)如何统计?
如果需要统计它的话,可以在 libavformat/http.c 文件中的, http_open 方法
int64_t start = av_gettime();
ret = http_open_cnx(h, options);
int64_t end = av_gettime();
4.音视频流探测耗时
这个定义比较模糊,它在 ffplay 中对应的是 avformat_find_stream_info 的耗时,它是一个同步的方法。在播放器中它会阻塞整个流程,因为它的作用是找到初始化音视频解码器的必要的数据。它有一些参数会印象到它的耗时,不过如果参数设置合适的话,一般是 100ms 内完成。
1)如何统计?
可以在 ijkplayer 的工程中 ff_ffplay.c 文件中,read_thread 方法
int64_t start = av_gettime();
avformat_find_stream_info(ic, opts);
int64_t end = av_gettime();
5.缓冲耗时
1)什么是缓冲耗时?
缓冲耗时是指播放器的缓冲的数据达到了预先设定的阈值,可以开始播放视频了。这个值是可以动态设置的,所以不同的设置给首屏带来的影响是不一样的。
我们在美拍直播播放器最开始的设置是视频帧数和音频帧数都达到10帧以上,才可以开始播放。所以这部分一般的耗时都比较大,同时它还跟播放器里面的一个设置 BUFFERING_CHECK_PER_MILLISECONDS 值有关,因为播放器 check 缓冲区的数据是否达到目标值不是随意检测的,因为 check 本身会有一定的浮点数运算,所以 ijkplayer 最初给他设置了500ms 值,明显比较大,所以会对缓冲耗时有比较大的影响。
2)如何统计?
缓冲耗时的统计方法,不像前面几个那么简单,因为它涉及到的代码有多处,所以需要再多个地方计时。 开始计时可以直接从前面的 find 后面开始,结束计时可以在第一帧视频渲染出来的时候结束计时。
avformat_find_stream_info(ic, opts);
start = av_gettime();
....
if (!ffp->first_video_frame_rendered) {
ffp->first_video_frame_rendered = 1;
ffp_notify_msg1(ffp, FFP_MSG_VIDEO_RENDERING_START);
end = av_gettime();
}
至此,首屏耗时的拆解就完成了,剩下的优化就从具体每个阶段着手优化。
三、首屏时间的具体优化
在前面的分解之后,再来优化首屏时间,思路就比较清晰了。因为流程是串行的,所以只需要做到局部最优,总体就会最优。
1.DNS的优化解析
1)优化思路
DNS 的解析一直以来都是网络优化的首要问题,不仅仅有时间解析过长的问题,还有小运营商 DNS 劫持的问题,一般的解决方案都是采用 HttpDNS,但 HttpDNS 在部分地区也可能存在准确性问题,综合各方面我们采用了HTTPDNS 和 LocalDNS 结合的方案,来提升解析的速度和准确率。
前面已经提到了,一般来说如果只是解析IPV4来说,LocalDNS 的耗时并不算长。但我们也不能直接修改 ffmpeg ,因为也要考虑到将来的 IPV6 的扩展问题。好在我们内部有专门做 DNS 的 SDK,他们的大概思路是,APP 启动的时候就会先预解析我们指定的域名,因为拉流域名是固定的几个,所以完全可以先缓存起来。然后会根据各个域名解析的时候返回的有效时间,过期后再去解析更新。
至于 DNS 劫持的问题,内部会有一个评估策略,如果 loacldns 出来的IP无法正常使用,或者延时太高,就会切换到 HttpDns 重新解析。这样就保证了每次真正去拉流的时候,DNS 的耗时几乎为0,因为可以定时更新缓存池,使每次获得的 DNS 都是来自缓存池的。
2)具体实现方式
如何替换掉 ffmpeg 中 tcp.c 文件中的 ret = getaddrinfo(hostname, portstr, &hints, &ai); 方法,我们最开始想到了两种方案:
- 方案A
比如我们的拉流 url 是这样的 http://a.meipai.com/m/c04.flv ,如果在传递 url 给 ffmpeg 前将 http://a.meipai.com 替换成 DNS 预先解析出来的 ip 比如 112.34.23.45 ,那替换后的url就是http://112.34.23.45/m/c04.flv。如果直接用这个 url 去发起 http 请求,在有些情况可以,很多情况是不行的。如果这个iP的机器只部署了 http://a.meipai.com 对应的服务,就能解析出来。如果有多个域名的服务,CDN 节点就无法正确的解析。所以这个时候一般是设置 http 请求的 header里面的 Host 字段。一般可以通过以下代码传递给 ffmpeg 内部,这个参数的作用就是填充 http 的 Host 头部,具体的实现,可以 ffmpeg 源码,文件 http.c 中http_connect 方法中。
AVDictionary **dict = ffplayer_get_opt_dict(ffplayer, opt_category);
av_dict_set(dict, "headers", "Host: hdl-test-meipai.com", 0);
但这种方案有个 bug 就是,如果在发出请求 http://a.meipai.com/m/c04.flv 的时候,服务端通过302调度方式返回了类似的结果 http://112.34.23.45/http://a.meipei.com/m/c04.flv ,指定了 ip 的 url ,这时客户端并不知道跳转的逻辑,因为 http 请求都是在 ffmpeg 内部进行的。这个时候再设置了Host,就会出现 http://112.34.23.45/http://a.meipai.com/a.meipai.com/m/c04.flv 中间有两个 host 的情况,导致服务端无法解析的 bug。这种情况也是在中途测试的时候偶尔发生的,目前没有比较好的解决方案,除非让服务端采用不下发302跳转,但这样就不通用了,会给将来留下隐患,所以这种简单的方案不可行。
- 方案B
还有一种方案就是经常会用到的设置函数指针的方式,在 ffmpeg 中的 tcp.c 中用函数指针替换掉 getaddreinfo 方法,因为这个方法就是实际解析 DNS 的方法,比如下面代码:
if(my_getaddreinfo) {
ret = my_getaddreinfo(hostname, portstr, &hints, &ai);
} else {
ret = getaddrinfo(hostname, portstr, &hints, &ai);
}
在 my_getaddreinfo 方法中,可以调用 DNS SDK 的解析方法,获取到 ip,然后填充到 ai 里面,就实现了我们的需求。这种方案的优势很明显,就是灵活,容易扩展,而且没有什么风险。不过有个劣势是需要修改 ffmpeg 源码,这对于一个大的 APP 里面,有多个功能共用一个 ffmpeg 库的情况来讲,需要增加很多测试成本。
总体来说,DNS 优化后,根据线上的数据首屏时间能减少 100ms~300ms 左右,特别是针对很多首次打开,或者 DNS 本地缓存过期的情况下,能有很好的优化效果。
2. TCP连接耗时的优化解析
TCP 连接耗时,这个耗时可优化的空间主要是针对建连节点链路的优化,主要受限于三个因素影响:用户自身网络条件、用户到 CDN 边缘节点中间链路的影响、CDN 边缘节点的稳定性。因为用户网络条件有比较大的不可控性,所以优化主要会在后面两个点。我们这边会结合着用户所对应的城市、运营商的情况,同时结合着服务端的 CDN 多融合调度体系,可以给用户下发更合适的 CDN 服务域名,然后通过 HTTPDNS SDK 来优化 DNS 解析的结果。同时对于一些用户被解析到比较偏远的节点,或者质量不稳定的节点,那么我们会通过监控机制来发现,并推动做些优化。
3. http响应耗时的优化解析
目前 HTTP 响应耗时分两种情况:
- 如果 CDN 节点没有缓存流,CDN 收到 HTTP 请求后,就需要回源站去拉流,请求响应,并等待源站的响应结果。这个耗时就比较久了,一般是 400ms 左右,这块和 CDN 内部的架构有关,有时更久,达到几秒的情况都有,所以这种情况,一般需要推动 CDN 厂商做一些优化;
- 如果 CDN 节点有缓存流,CDN 收到 HTTP 请求后,会理解返回响应头部,一般是在 100ms 以内,响应很快。这块比较受限于 CDN 边缘节点分发策略,不同的 CDN 厂商的表现会有些差异,在端层面可做的东西较少,所以主要是推动多 CDN 的融合策略来提升更好的体验。
4. 音视频流探测耗时的优化解析
音视频流的探测耗时,在 ffmpeg 中可以对应函数 avformat_find_stream_info 函数。在 ijkplayer 的实现中,这个方法的耗时一般会比较久。在 ffmpeg 中的 utils.c 文件中的函数实现中有一行代码是 int fps_analyze_framecount = 20; ,这行代码的大概用处是,如果外部没有额外设置这个值,那么 avformat_find_stream_info 需要获取至少 20 帧视频数据,这对于首屏来说耗时就比较长了,一般都要 1s 左右。而且直播还有实时性的需求,所以没必要至少取 20 帧。这里就有优化空间,可以去掉这个条件。设置方式:
av_dict_set_int(&ffp->format_opts, "fpsprobesize", 0, 0);
这样,avformat_find_stream_info 的耗时就可以缩减到 100ms 以内。
5. buffer缓冲耗时的优化解析
这部分是纯粹看播放器内部逻辑的实现,因为我们是基于 ijkplayer 来修改的,就以 ijkplayer 来讲。先点出需要优化的三个地方:
- BUFFERING_CHECK_PER_MILLISECONDS 值需要降低;
- MIN_MIN_FRAMES 值需要降低;
- CDN配置快启优化,下面具体分析。
1)BUFFERING_CHECK_PER_MILLISECONDS
这部分逻辑主要是在 ijkplayer 工程中 ff_ffplay.c 文件中的 read_thread 方法中。用到的地方只有一处:
#define BUFFERING_CHECK_PER_MILLISECONDS (300)
if (ffp->packet_buffering) {
io_tick_counter = SDL_GetTickHR();
if (abs((int)(io_tick_counter - prev_io_tick_counter)) > BUFFERING_CHECK_PER_MILLISECONDS){
prev_io_tick_counter = io_tick_counter;
ffp_check_buffering_l(ffp);
}
}
从这个代码逻辑中可以看出,每次调用 ffp_check_buffering_l 去检查 buffer是否满足条件的时间间隔是 500ms 左右,如果刚好这次只差一帧数据就满足条件了,那么还需要再等 500ms 才能再次检查了。这个时间,对于直播来说太长了。我们当前的做法是降低到 50ms,理论上来说可以降低 150ms 左右,根据我们线上灰度的数据来看,平均可以减少 200ms 左右,符合预期值。
2)MIN_MIN_FRAMES
这部分代码实现是在 ffp_check_buffering_l(ffp) 函数中。
#define MIN_MIN_FRAMES 10
if (is->buffer_indicator_queue && is->buffer_indicator_queue->nb_packets > 0) {
if ( (is->audioq.nb_packets > MIN_MIN_FRAMES || is->audio_stream < 0 || is->audioq.abort_request)
&& (is->videoq.nb_packets > MIN_MIN_FRAMES || is->video_stream < 0 || is->videoq.abort_request)) {
printf("ffp_check_buffering_l buffering end \n");
ffp_toggle_buffering(ffp, 0);
}
}
这里大概的意思需要缓冲的数据至少要有 11 帧视频,和 11 个音频数据包,才能离开缓冲区,开始播放。我们知道音频数据很容易满足条件,因为如果采样率是 44.1k 的采集音频话,那么 1s,平均有 44 个音频包。11 个音频包,相当于 0.25s 数据。但对于视频,如果是24帧的帧率,至少需要 0.4s 左右的数据,对于大部分 android 直播来说,因为美颜、 AR 方面的处理消耗,所以他们的采集编码帧率只有 10~15s ,那么就需要接近1s的数据,这个耗时太长。缓冲区里需要这么多数据,但实际上播放器已经下载了多少数据呢?我们深入 ff_ffplay.c 源码可以看到视频解码后会放到一个 frame_queue 里面,用于渲染数据。可以看到视频数据的流程是这样的:下载到缓冲区->解码->渲染。其中渲染的缓冲区就是 frame_queue 。下载的数据会先经过解码线程将数据输出到 frame_queue 中,然后等 frame_queue 队列满了,才留在缓冲队列中。在 ff_ffplay.c 中,可以找到如下代码:
#define VIDEO_PICTURE_QUEUE_SIZE_MIN (3)
#define VIDEO_PICTURE_QUEUE_SIZE_MAX (16)
#define VIDEO_PICTURE_QUEUE_SIZE_DEFAULT (VIDEO_PICTURE_QUEUE_SIZE_MIN)
ffp->pictq_size = VIDEO_PICTURE_QUEUE_SIZE_DEFAULT; // option
/* start video display */
if (frame_queue_init(&is->pictq, &is->videoq, ffp->pictq_size, 1) < 0)
goto fail;
所以目前来看,如果设置 10 ,播放器开始播放时至少有 14 帧视频。对于低帧率的视频来说,也相当大了。在实践中我们把它调整到 5 ,首屏时间减少了 300ms 左右,并且卡顿率只上升了 2 个百分点左右。
3)CDN边沿优化
CDN 边沿的优化主要包括 GOP 缓存技术及快启优化技术。这项两项技术基本原理是通过快速下发足够的视频帧以填充满播放器的缓冲区从而让播放器在最短的时间内达到播放条件以优化首屏时间。视频缓存会以完整 GOP 为单位,这个主要是为了防止视频出现花屏,快启优化则是会在 GOP 缓存基本上根据播放器缓冲区大小设定一定的 GOP 数量用于填充播放器缓冲区。
这个优化项并不是客户端播放器来控制的,而是 CDN 下发视频数据的带宽和速度。因为缓冲区耗时不仅跟缓冲需要的帧数有关,还跟下载数据的速度优化,以网宿 CDN 为例,他们可以配置快启后,在拉流时,前面缓存 1s 的数据,服务端将以 5 倍于平时带宽的速度下发。这样的效果除了首屏速度跟快以外,首屏也会更稳定,因为有固定 1s 的缓存快速下发。这个优化的效果是平均可以更快 100ms 左右。
四、小结
至此,美拍直播的首屏效果,已经基本跟业界主流直播效果相当,后面我们将在稳定性、卡顿率和卡顿时间上面做进一步优化。
需要注意的是:基础数据的统计是一切优化的基础。比如首屏时间优化的一个最基本的大前提就是需要有直播播放情况的各个阶段的统计数据,这在我们工作开展的前期是不完善的,比如,DNS 的耗时和 http 响应的耗时。这个因为种种原因导致一直都没有上报上来,所以最初是无法精准定位,只有一个大概的时间。还有一些更致命的问题是统计数据的不准确,因为历史原因导致数据的准确性不够,所以往往会因为错误的数据导致错误的分析。因此,我们需要重视基础数据统计的准确性和完善程度。