如果样本本身就是数字型的,那么样本本身就可以作为特征用于训练我们的模型,那么如果样本本身是文字型样本,如做文本分析等机器学习工作时,该如何提取特征?
1. 词集模型
单词构成的集合,集合中每个元素都只有一个。
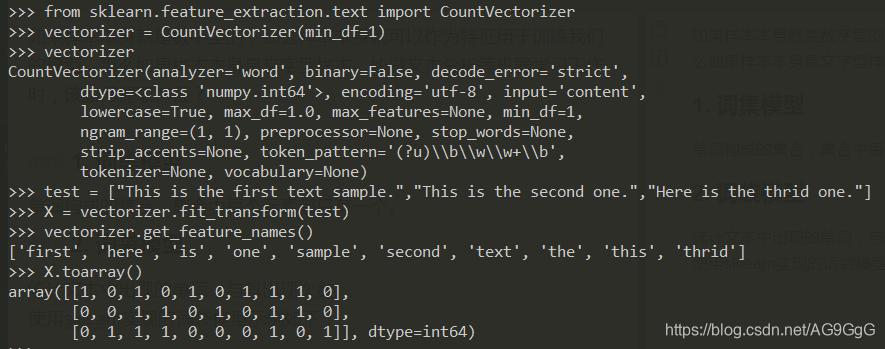
2. 词袋模型
统计文本中出现的单词,与其出现次数。
使用sklearn实现的词袋模型示例如下:
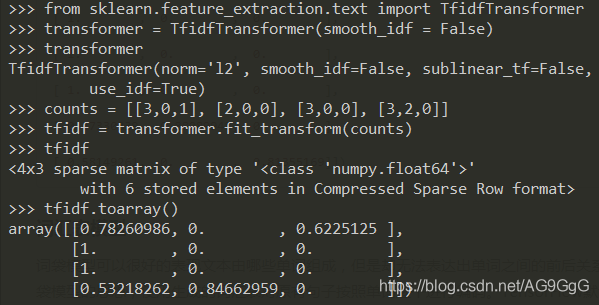
3. TF-IDF模型(term frequency–inverse document frequency,词频与逆向文件频率)
是一种统计方法,用以评估某一字词对于一个文件集或一个语料库的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF模型通常和词袋模型共同使用,用于处理词袋模型生成的数组。