版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_24452475/article/details/82970085
写在前面
- 运行环境
- jupyter
- 最近在处理大数据量问题,强化下Python性能优化方面的能力。
- 个人总结便于后续掌握与使用,仅供参考。
- 后续待更( 深入学习 ) …
1. 循环之外能实现逻辑,不放在循环内处理 [2.22倍] :
a = range(10000)
size_a = len(a)
%timeit -n 1000 for i in a: k = len(a)
%timeit -n 1000 for i in a: k = size_a
1000 loops, best of 3: 569 µs per loop
1000 loops, best of 3: 256 µs per loop
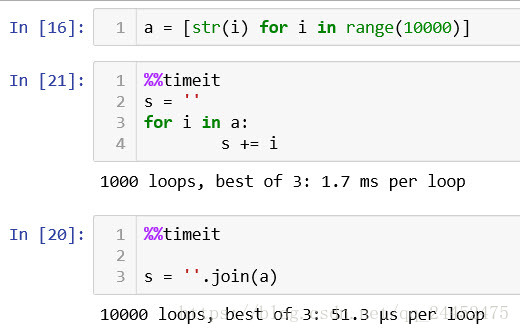
2. join 优于 += [33.1倍] :
a = [str(i) for i in range(10000)]
%%timeit
s = '' for i in a: s += i %%timeit
s = ''.join(a)
- 性能提升数十倍,如下图所示:
3. while 1 优于 while true [1.6倍] :
def while_1():
n = 100000
while 1:
n -= 1
if n <= 0: break
def while_true():
n = 100000
while True:
n -= 1
if n <= 0: break
m, n = 1000000, 1000000
%timeit -n 100 while_1()
%timeit -n 100 while_true()
100 loops, best of 3: 2.38 ms per loop
100 loops, best of 3: 3.79 ms per loop
4. ** 优于pow函数 [6.8倍] :
%timeit -n 10000 c = pow(2,20)
%timeit -n 10000 c = 2**20
10000 loops, best of 3: 80.4 ns per loop
10000 loops, best of 3: 11.7 ns per loop
5. set 优于 list [2.18倍]:
lista=[1,2,3,4,5,6,7,8,9,13,34,53,42,44]
listb=[2,4,6,9,23]
%%timeit
intersection=[]
for i in range (1000000):
for a in lista:
for b in listb:
if a == b:
intersection.append(a)
1 loop, best of 3: 2.11 s per loop
%%timeit
intersection=[]
for i in range (1000000):
list(set(lista)&set(listb))
1 loop, best of 3: 966 ms per loop
6. key 优于 list [2.28倍] :
lists = ['a','b','is','python','jason','hello','hill','with','phone','test',
'dfdf','apple','pddf','ind','basic','none','baecr','var','bana','dd','wrd']
%%timeit
filter = []
for i in range (1000000):
for find in ['is','hat','new','list','old','.']:
if find not in lists:
filter.append(find)
1 loop, best of 3: 1.52 s per loop
%%timeit
lists2 = dict.fromkeys(lists,True)
filter = []
for i in range (1000000):
for find in ['is','hat','new','list','old','.']:
if find not in lists2:
filter.append(find)
1 loop, best of 3: 667 ms per loop
7. 列表解析 优于 append构建 [2.36倍]:
list = ['a','b','is','python','jason','hello','hill','with','phone','test',
'dfdf','apple','pddf','ind','basic','none','baecr','var','bana','dd','wrd']
%%timeit
total=[]
for i in range (1000000):
for w in list:
total.append(w)
1 loop, best of 3: 1.74 s per loop
%%timeit
for i in range (1000000):
a = [w for w in list]
1 loop, best of 3: 737 ms per loop