隐马尔可夫模型示意图:

如图所示,模型在贝叶斯网络中相关分析:
如果z1是A,z2是c,x1是B
那么当A是不可观测时候,那么B和c就不是相互独立的,就是没确定,则x1和z2就一定有关系。那么当A是可观测的时候,那么B和c就是相互独立的。
如果把z2、x2融为一体看做c的话,那可知x1与z2、x2一定有关系,那么最后x1和x2就是不独立的呢
同理,x1 和x2, x3, xn+1都是不独立的。
隐马尔可夫模型概念:
隐马尔可夫模型(Hidden Markov Model,HMM)是用来描述一个含有隐含未知参数的马尔可夫过程。x为观测序列,z是我们无法观测到的隐藏的状态的随机序列,叫状态序列。所有关于时间和空间的问题都可以采用这个模型。隐藏状态一定是离散的。但是观测是可以是离散的也可以是连续的。
隐马尔可夫模型的假设:
对 HMM 来说,有如下三个重要假设,即便这些假设都是不现实的
假设1:有限历史性假设的马尔可夫假设
p(xi|xi−1…x1)=p(xi|xi−1)
p(xi|xi−1…x1)=p(xi|xi−1)
假设2:输出也即是观察值仅与当前状态有关的输出独立性假设
p(o1…oT|x1…xT)=∏p(Ot|xt)
假设3:状态与具体时间无关的齐次性假设
p(xi+1|xi)=p(xj+1|xj)
p(xi+1|xi)=p(xj+1|xj)
隐马尔可夫和线性回归对比:
线性回归中的样本是相互独立,误差是符合高斯分布。
隐马尔可夫的样本不是相互独立的,样本之间是有关系的,不是相互独立的数据叫做结构化数据。
维特比算法:
给定一个矩阵,这个矩阵是由非负数组成的,从这个矩阵的[0,0]开始走,走的方向只能是向下或者是向右,然后求出最小的路径之和。

路径计算公式:
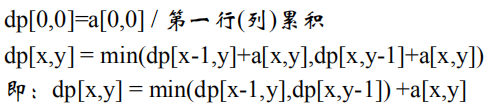
viterbi是针对Lattice篱笆网络的有向图最短路径的问题提出来的,是用动态规划来解觉隐马尔可夫模型预测问题。 viterbi针对于hmm出现的问题进行解码,用DP求概率最大的路径,每一条路径对应着一个状态序列,它可以解决一个图中的最短路径问题。 定义变量,在时刻t状态为i的所有路径中,求概率的最大值。
举栗子:
隐性状态 = (‘晴天’, ‘下雨’)
观测状态 = (‘散步’, ‘购物’, ‘清洗’)
初始概率 = { ‘晴天’: 0.6’,下雨’: 0.4}
状态转移矩阵 =
{‘晴天’ : {‘晴天’: 0.7, ‘下雨’: 0.3},‘下雨’ : {‘晴天’: 0.4, ‘下雨’: 0.6},}
发射矩阵 =
{‘晴天’ : {‘散步’: 0.5, ‘购物’: 0.4, ‘清洗’: 0.1}, ‘下雨’ : {'散步: 0.1, ‘购物’: 0.3, ‘清洗’: 0.6},}
第一天:
P(第一天晴天) = P(散步|晴天)*P(晴天|初始情况) = 0.5 * 0.6 = 0.3
P(第一天下雨) = P(散步|下雨)*P(下雨|初始情况) = 0.1 * 0.4 = 0.04
第二天的时候:求出路径的单个路径的最大概率,然后再乘上观测概率。
P(第二天晴天) =
max{ P(晴天|晴天) P(第一天晴天) , P(晴天|下雨) P(第一天下雨) } P(购物|晴天) =max{0.30.7, 0.040.4}0.4=0.30.70.4=0.084
P(第二天下雨) =
max{ P(下雨|晴天) P(第一天晴天) , P(下雨|下雨)P(第一天下雨) } P(购物|下雨) =max{0.30.3, 0.040.6}0.3=0.30.30.3=0.027
可以得到在第二天下雨0.027这个路径,第一天也是晴天的。
第三天:
P(第三天晴天)=
max{P(晴天|晴天)P(第二天晴天) , P(晴天|下雨) P(第二天晴天) } P(清洗|晴天)
max{0.0840.7, 0.0270.4}0.1= 0.0840.70.1 =0.00588,
这个路径,第二天是晴天
P(第三天下雨)=
max{P(下雨|晴天) P(第二天晴天) ,P(下雨|下雨) P(第二天下雨) } P(清洗|下雨)
max{0.0840.3, 0.0270.6}0.6=0.0840.30.6 = 0.01512
这个路径,第二天是晴天
栗子总结:最后一天的状态概率分布就是最优路径的概率分布:P(第三天下雨)=0.01512
第三天下雨 ----最优路径开始回溯—> 第二天晴天-- --最优路径开始回溯–> 第一天是晴天
路径即为:晴天,晴天,下雨
BMES标签分词应用:
天气当成“词性标签”,当天的活动当做“字”:
分词:一个句子,找出概率最大的标签序列。
断句符号:“词尾”或“非词尾”构成的序列)
利用BMES标签来分词:
1开头、B
2中间、M
3结尾、E
4独立成词、S
终止词和非终止词分词举例1:
比如:平时加强体育锻炼是好习惯
0:[ ]
1:[平, 平时]
2:[时, 时加, 时加强]
3:[加, 加强]
4:[强, 强体]
5:[体, 体育]
6:[育, 育段]
7:[锻, 锻炼]
8:[炼, 链是]
9:[是, 是好]
10:[外]
10:[好]
11:[严, 严重]
11:[习, 习惯]
12:[重]
12:[惯]
13:[ ]
起始和末尾的标志就是空
0:
1:平 A1, 平时 A2
通过“平”可以计算2[时, 时加, 时加强]
平 ----> 时 A1+B12
平 ----> 时加 A1+ B22
平 ----> 时加强 A2 + B23
通过 ”平时“可以计算3[ 加, 时加]
平时 ----> 加 A2 + B32
平时 ----> 加强 A2 + B33
小结:前面的隐状态的概率全部求出来,根据这个前面的隐状态的概率去依次求取后面的隐状态的各个概率,后面序列中的每一个状态的最大值作为当前序列隐状态的概率,并且记录前面隐状态到当前隐状态的路径,也就是一个动态规划实现最短路径。
终止词和非终止词分词举例2:
接待来到我家的客人
建立HMM的A, B, π。
π的确定:
每个样本,是不是“终止字”的 状态只有2个:状态1 为是、状态2 为不是,所以 π = {p1,p2}
P1:第一个字是非终止字的概率
P2:第一个字是终止字的概率
状态转移矩阵A:
根据π = {p1,p2},状态转移矩阵是2乘2矩阵,如下:
p11:非终止字 —到----> 非终止字概率
p21:终止字 ------到----> 非终止字概率
p12:非终止字 —到----> 终止字概率
p22:终止字 ------到-----> 终止字概率
观测矩阵B:
Unicode编码,每个字是0到65535中的其中一个数,B是2*65535矩阵:
p1,0:汉字是Unicode编码中的0的非终止字的概率
p2,0:汉字是Unicode编码中的0的终止字的概率
p1,1:汉字是Unicode编码中的1的非终止字的概率
p2,1:汉字是Unicode编码中的1的终止字的概率
首先有了Z1是“非终止字”的这个隐性状态,通过状态转移矩阵,转移到Z2 为“终止字”,Z2从65535个字中选出了x2=“迎”这个字,完成。



引自原文:https://blog.csdn.net/LaoLiulaoliu/article/details/7559145