一、Deep Learning & Art: Neural Style Transfer
import os
import sys
import scipy.io
import scipy.misc
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
from PIL import Image
from nst_utils import *
import numpy as np
import tensorflow as tf
%matplotlib inline
2 - Transfer Learning
Neural Style Transfer (NST) uses a previously trained convolutional network, and builds on top of that. The idea of using a network trained on a different task and applying it to a new task is called transfer learning.
Following the original NST paper (https://arxiv.org/abs/1508.06576), we will use the VGG network. Specifically, we'll use VGG-19, a 19-layer version of the VGG network. This model has already been trained on the very large ImageNet database, and thus has learned to recognize a variety of low level features (at the earlier layers) and high level features (at the deeper layers).
model = load_vgg_model("pretrained-model/imagenet-vgg-verydeep-19.mat")
print(model)
3 - Neural Style Transfer
We will build the NST algorithm in three steps:
- Build the content cost function Jcontent(C,G)Jcontent(C,G)
- Build the style cost function Jstyle(S,G)Jstyle(S,G)
- Put it together to get J(G)=αJcontent(C,G)+βJstyle(S,G)J(G)=αJcontent(C,G)+βJstyle(S,G).
content_image = scipy.misc.imread("images/louvre.jpg")
imshow(content_image)
So, suppose you have picked one particular hidden layer to use. Now, set the image C as the input to the pretrained VGG network, and run forward propagation. Let a(C)a(C) be the hidden layer activations in the layer you had chosen. (In lecture, we had written this as a[l](C)a[l](C), but here we'll drop the superscript [l][l] to simplify the notation.) This will be a nH×nW×nCnH×nW×nC tensor. Repeat this process with the image G: Set G as the input, and run forward progation. Let
a(G)a(G)
be the corresponding hidden layer activation. We will define as the content cost function as:
Jcontent(C,G)=14×nH×nW×nC∑all entries(a(C)−a(G))2
def compute_content_cost(a_C, a_G):
"""
Computes the content cost
Arguments:
a_C -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing content of the image C
a_G -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing content of the image G
Returns:
J_content -- scalar that you compute using equation 1 above.
"""
### START CODE HERE ###
# Retrieve dimensions from a_G (≈1 line)
m, n_H, n_W, n_C = a_G.get_shape().as_list()
# Reshape a_C and a_G (≈2 lines)
a_C_unrolled = tf.reshape(tf.transpose(a_C), (m, n_H * n_W, n_C))
a_G_unrolled = tf.reshape(tf.transpose(a_G), (m, n_H * n_W, n_C))
# compute the cost with tensorflow (≈1 line)
J_content =tf.reduce_sum((a_C_unrolled-a_G_unrolled)**2 / (4.* n_H * n_W *n_C))
### END CODE HERE ###
return J_content
tf.reset_default_graph()
with tf.Session() as test:
tf.set_random_seed(1)
a_C = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)
a_G = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)
J_content = compute_content_cost(a_C, a_G)
print("J_content = " + str(J_content.eval()))
3.2 - Computing the style cost¶
For our running example, we will use the following style image:
style_image = scipy.misc.imread("images/monet_800600.jpg")
imshow(style_image)

The result is a matrix of dimension (nC,nC)(nC,nC) where nCnC is the number of filters. The value GijGij measures how similar the activations of filter ii are to the activations of filter jj.
One important part of the gram matrix is that the diagonal elements such as GiiGii also measures how active filter ii is. For example, suppose filter ii is detecting vertical textures in the image. Then GiiGii measures how common vertical textures are in the image as a whole: If GiiGii is large, this means that the image has a lot of vertical texture.
By capturing the prevalence of different types of features (GiiGii), as well as how much different features occur together (GijGij), the Style matrix GG measures the style of an image.
Exercise: Using TensorFlow, implement a function that computes the Gram matrix of a matrix A. The formula is: The gram matrix of A is GA=AATGA=AAT. If you are stuck, take a look at Hint 1 and Hint 2.
def gram_matrix(A):
"""
Argument:
A -- matrix of shape (n_C, n_H*n_W)
Returns:
GA -- Gram matrix of A, of shape (n_C, n_C)
"""
### START CODE HERE ### (≈1 line)
GA = tf.matmul(A, tf.transpose(A))
### END CODE HERE ###
return GA
tf.reset_default_graph()
with tf.Session() as test:
tf.set_random_seed(1)
A = tf.random_normal([3, 2*1], mean=1, stddev=4)
GA = gram_matrix(A)
print("GA = " + str(GA.eval()))
3.2.2 - Style cost
After generating the Style matrix (Gram matrix), your goal will be to minimize the distance between the Gram matrix of the "style" image S and that of the "generated" image G. For now, we are using only a single hidden layer a[l]a[l], and the corresponding style cost for this layer is defined as:

where G(S)G(S) and G(G)G(G) are respectively the Gram matrices of the "style" image and the "generated" image, computed using the hidden layer activations for a particular hidden layer in the network.
Instructions: The 3 steps to implement this function are:
- Retrieve dimensions from the hidden layer activations a_G:
- To retrieve dimensions from a tensor X, use:
X.get_shape().as_list()
- To retrieve dimensions from a tensor X, use:
- Unroll the hidden layer activations a_S and a_G into 2D matrices, as explained in the picture above.
- Compute the Style matrix of the images S and G. (Use the function you had previously written.)
- Compute the Style cost:
def compute_layer_style_cost(a_S, a_G):
"""
Arguments:
a_S -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing style of the image S
a_G -- tensor of dimension (1, n_H, n_W, n_C), hidden layer activations representing style of the image G
Returns:
J_style_layer -- tensor representing a scalar value, style cost defined above by equation (2)
"""
### START CODE HERE ###
# Retrieve dimensions from a_G (≈1 line)
m, n_H, n_W, n_C = a_G.get_shape().as_list()
# Reshape the images to have them of shape (n_C, n_H*n_W) (≈2 lines)
a_S = tf.reshape(tf.transpose(a_S), (n_C, n_H * n_W))
a_G = tf.reshape(tf.transpose(a_S), (n_C, n_H * n_W))
# Computing gram_matrices for both images S and G (≈2 lines)
GS = gram_matrix(a_S)
GG = gram_matrix(a_G)
# Computing the loss (≈1 line)
J_style_layer = gram_matrix(a_G)
### END CODE HERE ###
return J_style_layer
tf.reset_default_graph()
with tf.Session() as test:
tf.set_random_seed(1)
a_S = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)
a_G = tf.random_normal([1, 4, 4, 3], mean=1, stddev=4)
J_style_layer = compute_layer_style_cost(a_S, a_G)
print("J_style_layer = " + str(J_style_layer.eval()))
3.2.3 Style Weights
So far you have captured the style from only one layer. We'll get better results if we "merge" style costs from several different layers. After completing this exercise, feel free to come back and experiment with different weights to see how it changes the generated image GG. But for now, this is a pretty reasonable default:
STYLE_LAYERS = [
('conv1_1', 0.2),
('conv2_1', 0.2),
('conv3_1', 0.2),
('conv4_1', 0.2),
('conv5_1', 0.2)]

def compute_style_cost(model, STYLE_LAYERS):
"""
Computes the overall style cost from several chosen layers
Arguments:
model -- our tensorflow model
STYLE_LAYERS -- A python list containing:
- the names of the layers we would like to extract style from
- a coefficient for each of them
Returns:
J_style -- tensor representing a scalar value, style cost defined above by equation (2)
"""
# initialize the overall style cost
J_style = 0
for layer_name, coeff in STYLE_LAYERS:
# Select the output tensor of the currently selected layer
out = model[layer_name]
# Set a_S to be the hidden layer activation from the layer we have selected, by running the session on out
a_S = sess.run(out)
# Set a_G to be the hidden layer activation from same layer. Here, a_G references model[layer_name]
# and isn't evaluated yet. Later in the code, we'll assign the image G as the model input, so that
# when we run the session, this will be the activations drawn from the appropriate layer, with G as input.
a_G = out
# Compute style_cost for the current layer
J_style_layer = compute_layer_style_cost(a_S, a_G)
# Add coeff * J_style_layer of this layer to overall style cost
J_style += coeff * J_style_layer
return J_style
3.3 - Defining the total cost to optimize
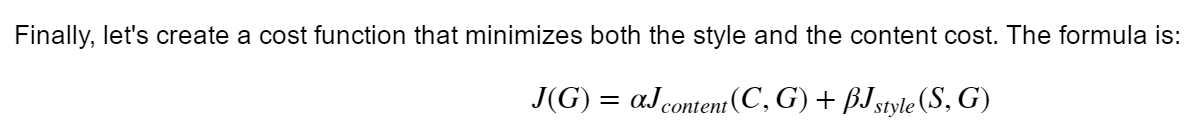
def total_cost(J_content, J_style, alpha = 10, beta = 40):
"""
Computes the total cost function
Arguments:
J_content -- content cost coded above
J_style -- style cost coded above
alpha -- hyperparameter weighting the importance of the content cost
beta -- hyperparameter weighting the importance of the style cost
Returns:
J -- total cost as defined by the formula above.
"""
### START CODE HERE ### (≈1 line)
J = alpha * J_content + beta * J_style
### END CODE HERE ###
return J
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(3)
J_content = np.random.randn()
J_style = np.random.randn()
J = total_cost(J_content, J_style)
print("J = " + str(J))
4 - Solving the optimization problem¶
Here's what the program will have to do:
- Create an Interactive Session
- Load the content image
- Load the style image
- Randomly initialize the image to be generated
- Load the VGG16 model
- Build the TensorFlow graph:
- Run the content image through the VGG16 model and compute the content cost
- Run the style image through the VGG16 model and compute the style cost
- Compute the total cost
- Define the optimizer and the learning rate
- Initialize the TensorFlow graph and run it for a large number of iterations, updating the generated image at every step.
Here's what the program will have to do:
- Create an Interactive Session
- Load the content image
- Load the style image
- Randomly initialize the image to be generated
- Load the VGG16 model
- Build the TensorFlow graph:
- Run the content image through the VGG16 model and compute the content cost
- Run the style image through the VGG16 model and compute the style cost
- Compute the total cost
- Define the optimizer and the learning rate
- Initialize the TensorFlow graph and run it for a large number of iterations, updating the generated image at every step.
# Reset the graph
tf.reset_default_graph()
# Start interactive session
sess = tf.InteractiveSession()
content_image = scipy.misc.imread("images/louvre_small.jpg")
content_image = reshape_and_normalize_image(content_image)
style_image = scipy.misc.imread("images/monet.jpg")
style_image = reshape_and_normalize_image(style_image)
generated_image = generate_noise_image(content_image)
imshow(generated_image[0])
model = load_vgg_model("pretrained-model/imagenet-vgg-verydeep-19.mat")
sess.run(model['input'].assign(content_image))
# Select the output tensor of layer conv4_2
out = model['conv4_2']
# Set a_C to be the hidden layer activation from the layer we have selected
a_C = sess.run(out)
# Set a_G to be the hidden layer activation from same layer. Here, a_G references model['conv4_2']
# and isn't evaluated yet. Later in the code, we'll assign the image G as the model input, so that
# when we run the session, this will be the activations drawn from the appropriate layer, with G as input.
a_G = out
# Compute the content cost
J_content = compute_content_cost(a_C, a_G)
sess.run(model['input'].assign(style_image))
# Compute the style cost
J_style = compute_style_cost(model, STYLE_LAYERS)
J = total_cost(J_content, J_style, alpha = 10, beta = 40)
optimizer = tf.train.AdamOptimizer(2.0)
# define train_step (1 line)
train_step = optimizer.minimize(J)
def model_nn(sess, input_image, num_iterations = 200):
# Initialize global variables (you need to run the session on the initializer)
### START CODE HERE ### (1 line)
sess.run(tf.global_variables_initializer())
### END CODE HERE ###
# Run the noisy input image (initial generated image) through the model. Use assign().
### START CODE HERE ### (1 line)
sess.run(model['input'].assign(input_image))
### END CODE HERE ###
for i in range(num_iterations):
# Run the session on the train_step to minimize the total cost
### START CODE HERE ### (1 line)
sess.run(train_step)
### END CODE HERE ###
# Compute the generated image by running the session on the current model['input']
### START CODE HERE ### (1 line)
generated_image = sess.run(model['input'])
### END CODE HERE ###
# Print every 20 iteration.
if i%20 == 0:
Jt, Jc, Js = sess.run([J, J_content, J_style])
print("Iteration " + str(i) + " :")
print("total cost = " + str(Jt))
print("content cost = " + str(Jc))
print("style cost = " + str(Js))
# save current generated image in the "/output" directory
save_image("output/" + str(i) + ".png", generated_image)
# save last generated image
save_image('output/generated_image.jpg', generated_image)
return generated_image
二、Face Recognition for the Happy House¶
- Face Verification - "is this the claimed person?". For example, at some airports, you can pass through customs by letting a system scan your passport and then verifying that you (the person carrying the passport) are the correct person. A mobile phone that unlocks using your face is also using face verification. This is a 1:1 matching problem.
- Face Recognition - "who is this person?". For example, the video lecture showed a face recognition video (https://www.youtube.com/watch?v=wr4rx0Spihs) of Baidu employees entering the office without needing to otherwise identify themselves. This is a 1:K matching problem.
FaceNet learns a neural network that encodes a face image into a vector of 128 numbers. By comparing two such vectors, you can then determine if two pictures are of the same person.
from keras.models import Sequential
from keras.layers import Conv2D, ZeroPadding2D, Activation, Input, concatenate
from keras.models import Model
from keras.layers.normalization import BatchNormalization
from keras.layers.pooling import MaxPooling2D, AveragePooling2D
from keras.layers.merge import Concatenate
from keras.layers.core import Lambda, Flatten, Dense
from keras.initializers import glorot_uniform
from keras.engine.topology import Layer
from keras import backend as K
K.set_image_data_format('channels_first')
import cv2
import os
import numpy as np
from numpy import genfromtxt
import pandas as pd
import tensorflow as tf
from fr_utils import *
from inception_blocks_v2 import *
%matplotlib inline
%load_ext autoreload
%autoreload 2
np.set_printoptions(threshold=np.nan)
The key things you need to know are:
- This network uses 96x96 dimensional RGB images as its input. Specifically, inputs a face image (or batch of mm face images) as a tensor of shape (m,nC,nH,nW)=(m,3,96,96)(m,nC,nH,nW)=(m,3,96,96)
- It outputs a matrix of shape (m,128)(m,128) that encodes each input face image into a 128-dimensional vector
FRmodel = faceRecoModel(input_shape=(3, 96, 96))

def triplet_loss(y_true, y_pred, alpha = 0.2):
"""
Implementation of the triplet loss as defined by formula (3)
Arguments:
y_true -- true labels, required when you define a loss in Keras, you don't need it in this function.
y_pred -- python list containing three objects:
anchor -- the encodings for the anchor images, of shape (None, 128)
positive -- the encodings for the positive images, of shape (None, 128)
negative -- the encodings for the negative images, of shape (None, 128)
Returns:
loss -- real number, value of the loss
"""
anchor, positive, negative = y_pred[0], y_pred[1], y_pred[2]
### START CODE HERE ### (≈ 4 lines)
# Step 1: Compute the (encoding) distance between the anchor and the positive, you will need to sum over axis=-1
pos_dist = tf.reduce_sum(tf.square(tf.subtract(y_pred[0],y_pred[1])))
# Step 2: Compute the (encoding) distance between the anchor and the negative, you will need to sum over axis=-1
neg_dist = tf.reduce_sum(tf.square(tf.subtract(y_pred[0],y_pred[2])))
# Step 3: subtract the two previous distances and add alpha.
basic_loss = tf.add(tf.subtract(pos_dist,neg_dist),alpha)
# Step 4: Take the maximum of basic_loss and 0.0. Sum over the training examples.
loss = tf.reduce_sum(tf.maximum(basic_loss,0.0))
### END CODE HERE ###
return loss
with tf.Session() as test:
tf.set_random_seed(1)
y_true = (None, None, None)
y_pred = (tf.random_normal([3, 128], mean=6, stddev=0.1, seed = 1),
tf.random_normal([3, 128], mean=1, stddev=1, seed = 1),
tf.random_normal([3, 128], mean=3, stddev=4, seed = 1))
loss = triplet_loss(y_true, y_pred)
print("loss = " + str(loss.eval()))
2 - Loading the trained model¶
FRmodel.compile(optimizer = 'adam', loss = triplet_loss, metrics = ['accuracy'])
load_weights_from_FaceNet(FRmodel)
3 - Applying the model¶
3.1 - Face Verification
database = {}
database["danielle"] = img_to_encoding("images/danielle.png", FRmodel)
database["younes"] = img_to_encoding("images/younes.jpg", FRmodel)
database["tian"] = img_to_encoding("images/tian.jpg", FRmodel)
database["andrew"] = img_to_encoding("images/andrew.jpg", FRmodel)
database["kian"] = img_to_encoding("images/kian.jpg", FRmodel)
database["dan"] = img_to_encoding("images/dan.jpg", FRmodel)
database["sebastiano"] = img_to_encoding("images/sebastiano.jpg", FRmodel)
database["bertrand"] = img_to_encoding("images/bertrand.jpg", FRmodel)
database["kevin"] = img_to_encoding("images/kevin.jpg", FRmodel)
database["felix"] = img_to_encoding("images/felix.jpg", FRmodel)
database["benoit"] = img_to_encoding("images/benoit.jpg", FRmodel)
database["arnaud"] = img_to_encoding("images/arnaud.jpg", FRmodel)
def verify(image_path, identity, database, model):
"""
Function that verifies if the person on the "image_path" image is "identity".
Arguments:
image_path -- path to an image
identity -- string, name of the person you'd like to verify the identity. Has to be a resident of the Happy house.
database -- python dictionary mapping names of allowed people's names (strings) to their encodings (vectors).
model -- your Inception model instance in Keras
Returns:
dist -- distance between the image_path and the image of "identity" in the database.
door_open -- True, if the door should open. False otherwise.
"""
### START CODE HERE ###
# Step 1: Compute the encoding for the image. Use img_to_encoding() see example above. (≈ 1 line)
encoding = img_to_encoding(image_path,model)
# Step 2: Compute distance with identity's image (≈ 1 line)
dist = np.linalg.norm((encoding-database[identity]))
# Step 3: Open the door if dist < 0.7, else don't open (≈ 3 lines)
if None:
print("It's " + str(identity) + ", welcome home!")
door_open = True
else:
print("It's not " + str(identity) + ", please go away")
door_open = False
### END CODE HERE ###
return dist, door_open
verify("images/camera_2.jpg", "kian", database, FRmodel)