基于低阶矩的自适应估计的Adam,是一种基于一阶梯度的随机目标函数优化算法
一、关键问题
高维参数空间随机目标的优化:
高阶优化方法往往不合适,本文讨论一阶方法
二、主要思路
1、算法及更新规则
(1)算法详述

注:
- 通过牺牲清晰度,可以提高算法的效率:
将伪代码的后三行改为:
- 移动指数加权平均法
- 根据同一个移动段内不同时间的数据对预测值的影响程度,分别给予不同的权数,然后再进行平均移动以预测未来值
- β等于历史值的加权率
- 如果把公式详细的展开,就会得到一个指数形式的公式:
(2)更新规则
- 每个时段在参数空间中采取的步骤的有效性受步长
限制:
,可理解为当前参数的可信域
2、初始化偏差校正
- 若
是固定的,则
;否则由于令指数衰减率为1,使得指数移动平均值分配过小的权重给梯度,
可以很小
- 用零初始化运行平均值带来
,因此,在算法1中我们除以该项以校正初始化偏差
3、收敛性分析
使用regret来评估我们的算法:
其中
计算复杂度为
三、实验验证
1、逻辑斯蒂回归
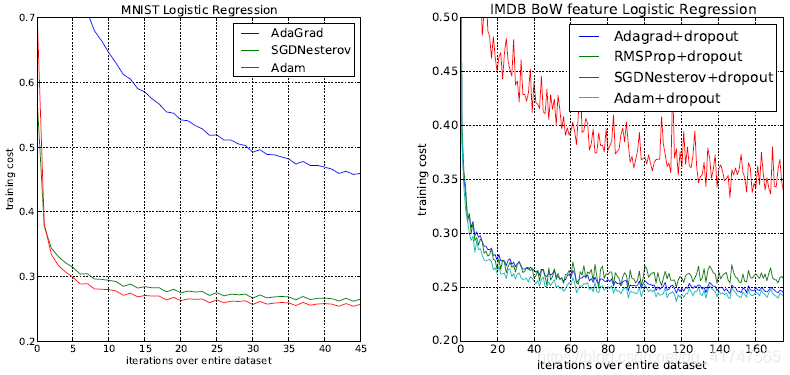
(1)Adam与SGD的收敛速度相似,并且都快于Adgrad
(2)(稀疏矩阵的情况)无论是否有正则噪音,Adgrad都比SGDNesterov好很多, Adam收敛速度和Adgrad一样快
2、多层神经网络

sum-of-functions (SFO)
(1)Adam在iterations和wall-clock time取得了更快的进展
(2)Adam的收敛速度比其他方法好
3、卷积神经网络

(1)Adagrad收敛慢
(2)虽然Adam比SGD的改善不明显,但它的不同层适应学习率规模,而不是像SGD那样手动拣选
4、偏差修正

(1)我们迭代了广泛的超参数选择:
,
(2)无论超参数设置如何,Adam都表现出与RMSProp相同或更好的表现
四、创新点
- 根据梯度的第一和第二矩的估计来计算不同参数的各个自适应学习速率(Adam:自适应矩估计)
- 结合两种流行方法的优点
- AdaGrad:适用于稀疏梯度
- RMSProp:适用于线上和不平稳的设置
五、主要贡献
- 实现简单,计算效率高,存储容量要求低,对梯度的对角重新缩放不变,并且非常适合于数据/参数方面较大的问题
- 适用于目标不变和具有非常嘈杂/稀疏梯度的问题
- 超参数具有直观的解释,并且通常只需要很少的调整。
六、对该领域的认知
随机梯度优化在许多科学和工程领域具有重要作用。 这些领域中的许多问题可以被视为一些标量目标函数优化,使其得到关于其参数的最大化或最小化。
AdaGrad:适用于稀疏梯度
RMSProp:适用于在线和不平稳的情况