Google于2017年6月发布在arxiv上的一篇文章《Attention is all you need》,提出解决sequence to sequence问题的transformer模型,用全attention的结构代替了lstm,抛弃了之前传统的encoder-decoder模型必须结合cnn或者rnn的固有模式,只用attention,可谓大道至简。文章的主要目的是在减少计算量和提高并行效率的同时不损害最终的实验结果( GLUE 上效果排名第一https://gluebenchmark.com/leaderboard),创新之处在于提出了两个新的Attention机制,分别叫做 Scaled Dot-Product Attention 和 Multi-Head Attention。Transformer作者已经发布其在TensorFlow的tensor2tensor库中。
考虑到RNN(或者LSTM,GRU等)的计算限制为是顺序的,也就是说RNN相关算法只能从左向右依次计算或者从右向左依次计算,这种机制带来了两个问题:
- 时间片
的计算依赖
时刻的计算结果,这样限制了模型的并行能力;
- 顺序计算的过程中信息会丢失,尽管LSTM等门机制的结构一定程度上缓解了长期依赖的问题,但是对于特别长期的依赖现象,LSTM依旧无能为力。
transformer模型结构
论文中的验证Transformer的实验室基于机器翻译的,其本质上是一个Encoder-Decoder的结构,编码器由6个编码block组成(encoder每个block由self-attention,FFNN组成),同样解码器是6个解码block组成(decoder每个block由self-attention,encoder-decoder attention以及FFNN组成),与所有的生成模型相同的是,编码器的输出会作为解码器的输入。Transformer可概括为:
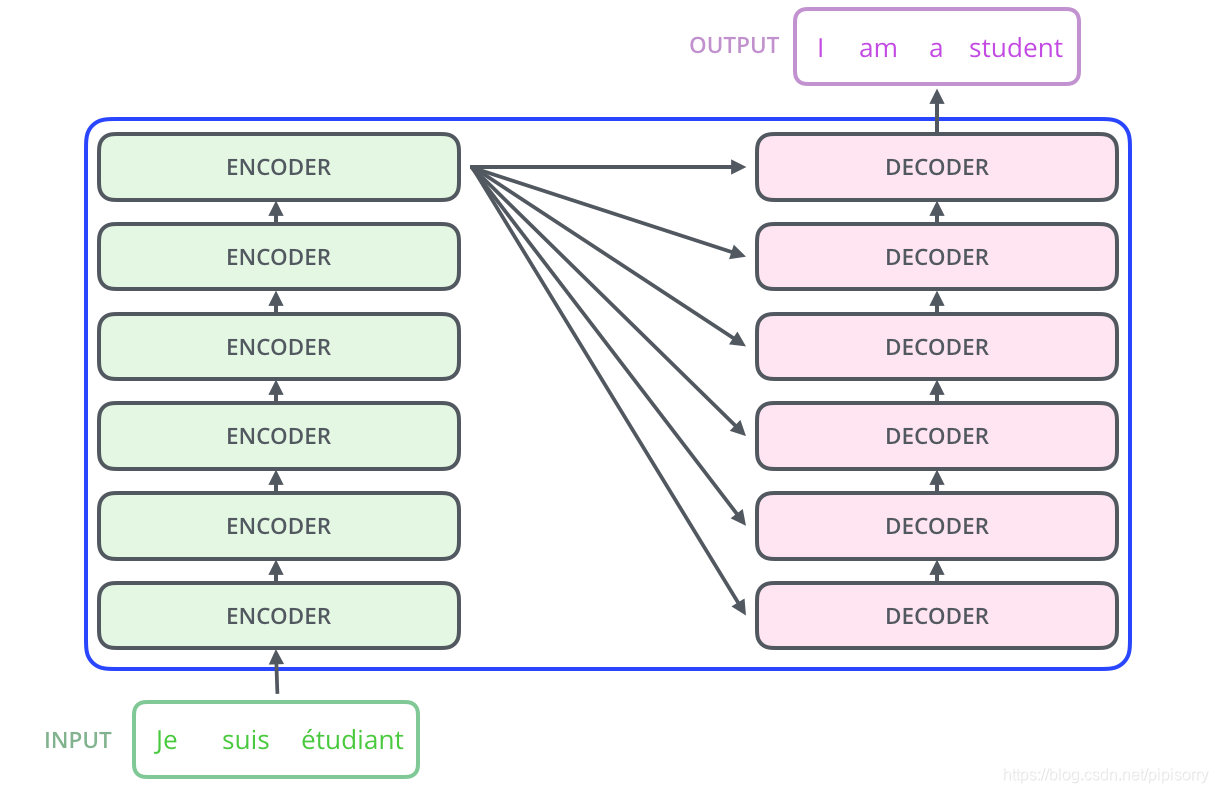
具体模型结构如下图:

Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNNs or convolution。和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
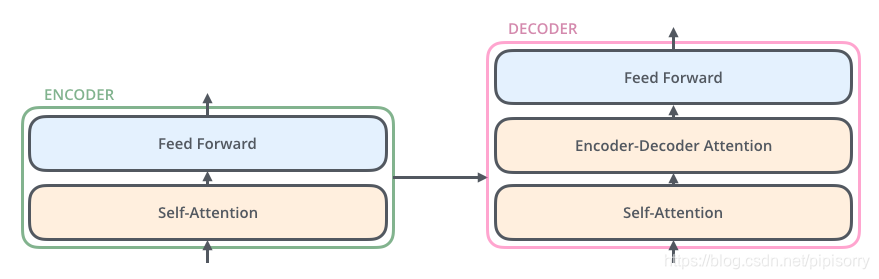
Transformer Encoder
Encoder由Nx个相同的layer组成,layer指的就是上图左侧的单元,最左边有个“Nx”(论文中是6x个)。每个Layer由两个sub-layer组成,分别是multi-head self-attention mechanism和fully connected feed-forward network。其中每个sub-layer都加了residual connection和normalisation,即在两个子层中会使用一个残差连接,接着进行层标准化(layer normalization)。因此可以将sub-layer的输出表示为:
multi-head self-attention mechanism和fully connected feed-forward network两个sub-layer的解释。
Multi-head self-attention
多头注意力机制——点乘注意力的升级版本。attention可由以下形式表示[深度学习:注意力模型Attention Model:Attention机制]:

Multi-head attention:multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来(很像cnn的思想):
Transformer会在三个地方使用multi-head attention:
1. encoder-decoder attention:输入为encoder的输出和decoder的self-attention输出,其中encoder的self-attention作为 key and value,decoder的self-attention作为query。
2. encoder self-attention:输入的Q、K、V都是encoder的input embedding and positional embedding。
3. decoder self-attention:在decoder的self-attention层中,deocder 都能够访问当前位置前面的位置,输入的Q、K、V都是decoder的input embedding and positional embedding。
Note: 在一般的attention模型中,Q就是decoder的隐层,K就是encoder的隐层,V也是encoder的隐层。所谓的self-attention就是取Q,K,V相同,均为encoder或者decoder的input embedding and positional embedding,更具体为“网络输入是三个相同的向量q, k和v,是word embedding和position embedding相加得到的结果"。
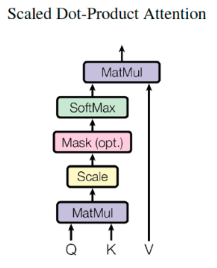
Scaled dot-product attention:不同的attention线性变换的计算采用了scaled dot-product attention,即:
Note:
1 作者同样提到了另一种复杂度相似但计算方法additive attention,在 (size_per_head=attention_head_size=hidden_size(768) / num_attention_heads(12): int. Size of each attention head.)很小的时候和dot-product结果相似,
大的时候,如果不进行缩放则表现更好,但dot-product的计算速度更快,进行缩放后可减少影响(由于softmax使梯度过小)。点乘注意力机制对于加法注意力而言,更快,同时更节省空间。
2 上面的softmax后可以再加个dropout,然后再multiply V。
3 虽然说的是多头,但是在实现时实际是通过transposes and reshapes tensors实现的,而不是分开的tensors。
Transformer注意力机制有效的解释:Transformer所使用的注意力机制的核心思想是去计算一句话中的每个词对于这句话中所有词的相互关系,然后认为这些词与词之间的相互关系在一定程度上反应了这句话中不同词之间的关联性以及重要程度。因此再利用这些相互关系来调整每个词的重要性(权重)就可以获得每个词新的表达。这个新的表征不但蕴含了该词本身,还蕴含了其他词与这个词的关系,因此和单纯的词向量相比是一个更加全局的表达。使用了Attention机制,将序列中的任意两个位置之间的距离缩小为一个常量。
Attention之后还有一个线性的dense层,即multi-head attention_output经过一个hidden_size为768的dense层,然后对hidden层进行dropout,最后加上resnet并进行normalization(tensor的最后一维,即feature维进行)。
Position-wise feed-forward networks
位置全链接前馈网络——MLP变形。之所以是position-wise(i/o维度一样)是因为处理的attention输出是某一个位置i的attention输出。hidden_size变化为:768->3072->768(或者512->2048->512)。
Position-wise feed forward network其实就是一个MLP 网络,1 的输出中,每个 d_model 维向量 x 在此先由 xW_1+b_1 变为 d_f 维的 x',再经过max(0,x')W_2+b_2 回归 d_model 维。
Feed Forward Neural Network全连接有两层dense,第一层的激活函数是ReLU(或者其更平滑的版本Gaussian Error Linear Unit-gelu),第二层是一个线性激活函数,如果multi-head输出表示为Z,则FFN可以表示为:
之后就是对hidden层进行dropout,最后加一个resnet并normalization(tensor的最后一维,即feature维进行)。
Transformer通过对输入的文本不断进行这样的注意力机制层和普通的非线性层交叠来得到最终的文本表达。
Transformer Decoder
Decoder和Encoder的结构差不多,但是多了一个attention的sub-layer。
对应上图先明确一下decoder的输入输出和解码过程:
- 输出:对应i位置的输出词的概率分布。
- 输入:encoder的输出 & 对应i-1位置decoder的输出(所以最开始的attention是self-attention(QKV全是decoder隐层);中间的attention不是self-attention,K,V来自encoder,Q来自上一位置decoder的输出)。
- 解码:编码可以并行计算,一次性全部encoding出来,但解码不是一次把所有序列解出来的,而是像rnn一样一个一个解出来的,因为要用上一个位置的输入当作attention的query。
decoder中间的Multi-head attention(Encoder-Decnoder Attention)和Position-wise feed-forward networks同encoder。不同的是decoder第一个多头注意力子层(Self-Attention)。其中Self-Attention:当前翻译和已经翻译的前文之间的关系;Encoder-Decnoder Attention:当前翻译和编码的特征向量之间的关系。
Masked multi-head attention:对于decoder中的第一个多头注意力子层,需要添加masking,确保预测位置i的时候仅仅依赖于位置小于i的输出,确保预测第i个位置时不会接触到未来的信息。在机器翻译中,解码过程是一个顺序操作的过程,也就是当解码第i个特征向量时,我们只能看到第i-1及其之前的解码结果。而我们要计算的attention是根据当前词i和前面的词来的,不能是后面的。
加了mask的attention原理如图(另附multi-head attention):
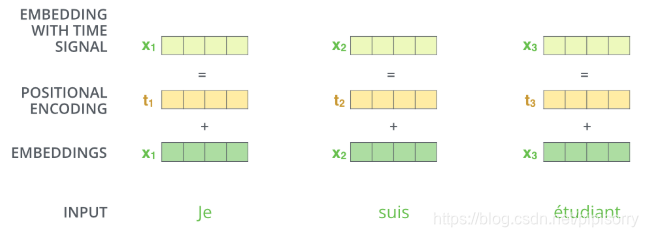
Positional Encoding
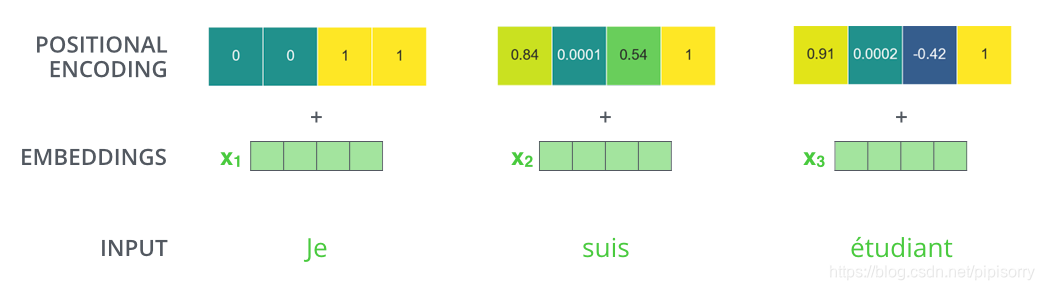
除了主要的Encoder和Decoder,还有数据预处理的部分。截止目前为止,我们介绍的Transformer模型并没有捕捉顺序序列的能力,也就是说无论句子的结构怎么打乱,Transformer都会得到类似的结果。换句话说,Transformer只是一个功能更强大的词袋模型而已。
Transformer抛弃了RNN,而RNN最大的优点就是在时间序列上对数据的抽象,所以文章中作者提出两种Positional Encoding的方法,将Positional Encoding后的数据与输入embedding数据求和,加入了相对位置信息。
两种Positional Encoding方法:
- 用不同频率的sine和cosine函数直接计算
- 学习出一份positional embedding(参考文献)。学习时注意,每个batch的pos emb都一样,即在batch维度进行broadcast。
经过实验发现两者的结果一样,所以最后选择了第一种方法,公式如下:
Note: 表示单词的位置,
表示单词的维度,d_model表示embedding维度512。关于位置编码的实现可在Google开源的算法中
get_timing_signal_1d()函数找到对应的代码。
方法1的好处有两点:
1. 任意位置的 都可以被
的线性函数表示。考虑到在NLP任务中,除了单词的绝对位置,单词的相对位置也非常重要。根据公式
以及
,这表明位置
的位置向量可以表示为位置
的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利。
2. 如果是学习到的positional embedding,可能会像词向量一样受限于词典大小。也就是只能学习到“位置2对应的向量是(1,1,1,2)”这样的表示。所以用三角公式明显不受序列长度的限制,也就是可以对 比所遇到序列的更长的序列 进行表示。
损失层
解码器解码之后,解码的特征向量经过一层激活函数为softmax的全连接层之后得到反映每个单词概率的输出向量。此时我们便可以通过CTC等损失函数训练模型了。
Transformer模型的评价
优点
作者主要讲了以下三点:
1. Total computational complexity per layer (每层计算复杂度)
2. Amount of computation that can be parallelized, as mesured by the minimum number of sequential operations required
作者用最小的序列化运算来测量可以被并行化的计算。也就是说对于某个序列 ,self-attention可以直接计算
的点乘结果,而rnn就必须按照顺序从
计算到
3. Path length between long-range dependencies in the network
这里Path length指的是要计算一个序列长度为n的信息要经过的路径长度。cnn需要增加卷积层数来扩大视野,rnn需要从1到n逐个进行计算,而self-attention只需要一步矩阵计算就可以,Transformer 在结构上优越,任何两个 token 可以无视距离直接互通。所以也可以看出,self-attention可以比rnn更好地解决长时依赖问题。当然如果计算量太大,比如序列长度n>序列维度d这种情况,也可以用窗口限制self-attention的计算数量。
4. 另外,从作者在附录中给出的栗子可以看出,self-attention模型更可解释,attention结果的分布表明了该模型学习到了一些语法和语义信息
缺点
缺点在原文中没有提到,是后来在Universal Transformers中指出的,在这里加一下吧,主要是两点:
- 实践上:有些rnn轻易可以解决的问题transformer没做到,比如复制string,尤其是碰到比训练时的sequence更长的时。
- 理论上:transformers非computationally universal(图灵完备),这种非RNN式的模型是非图灵完备的,无法单独完成NLP中推理、决策等计算问题(包括使用transformer的bert模型等等)。
Transformer结构细节和实现方式
神经网络的初始化是tf.truncated_normal_initializer(stddev=initializer_range)。
输入编码
Transformer的输入数据。如图所示,首先通过Word2Vec等词嵌入方法将输入语料转化成特征向量,论文中使用的词嵌入的维度为 (或者后来的bert中的768)。

单词的输入编码
在最底层的block中, 将直接作为Transformer的输入,而在其他层中,输入则是上一个block的输出。

输入编码作为一个tensor输入到encoder中
Self-Attention(scaled dot-product attention)
Self-Attention是Transformer最核心的内容,然而作者并没有详细讲解,下面我们来补充一下作者遗漏的地方。回想Bahdanau等人提出的用Attention,其核心内容是为输入向量的每个单词学习一个权重,例如在下面的例子中我们判断it代指的内容,
The animal didn't cross the street because it was too tired
通过加权之后可以得到类似下图的加权情况,在讲解self-attention的时候我们也会使用类似的表示方式

经典Attention可视化示例图
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量( ),Key向量(
)和Value向量(
),长度均是64。它们是通过3个不同的权值矩阵由嵌入向量
乘以三个不同的权值矩阵
,
,
得到,其中三个矩阵的尺寸也是相同的。均是
。
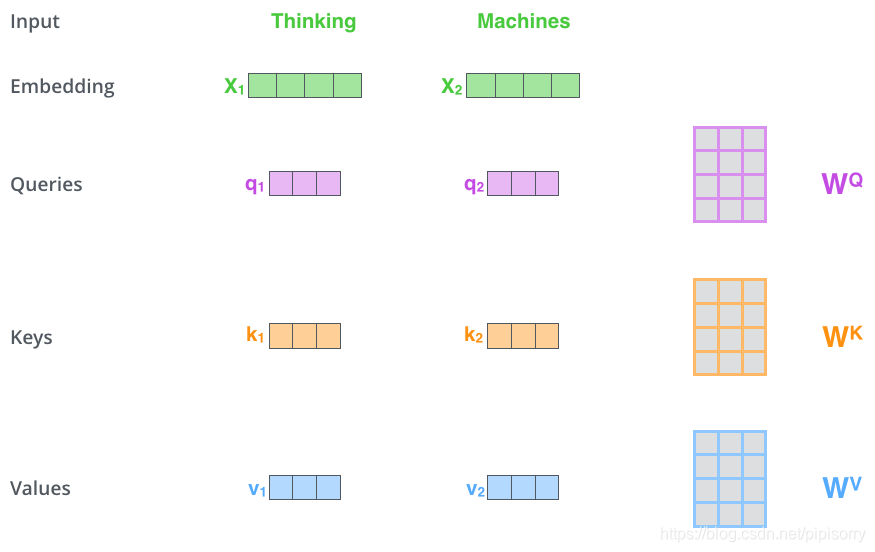
Q,K,V的计算示例图
那么Query,Key,Value是什么意思呢?它们在Attention的计算中扮演着什么角色呢?我们先看一下Attention的计算方法,整个过程可以分成7步:
- 如上文,将输入单词转化成嵌入向量;
- 根据嵌入向量得到
,
,
三个向量;
- 为每个向量计算一个score:
;
- 为了梯度的稳定,Transformer使用了score归一化,即除以
;
- 对score施以softmax激活函数;
- softmax点乘Value值
- 相加之后得到最终的输出结果
:
。
上面步骤的可以表示:
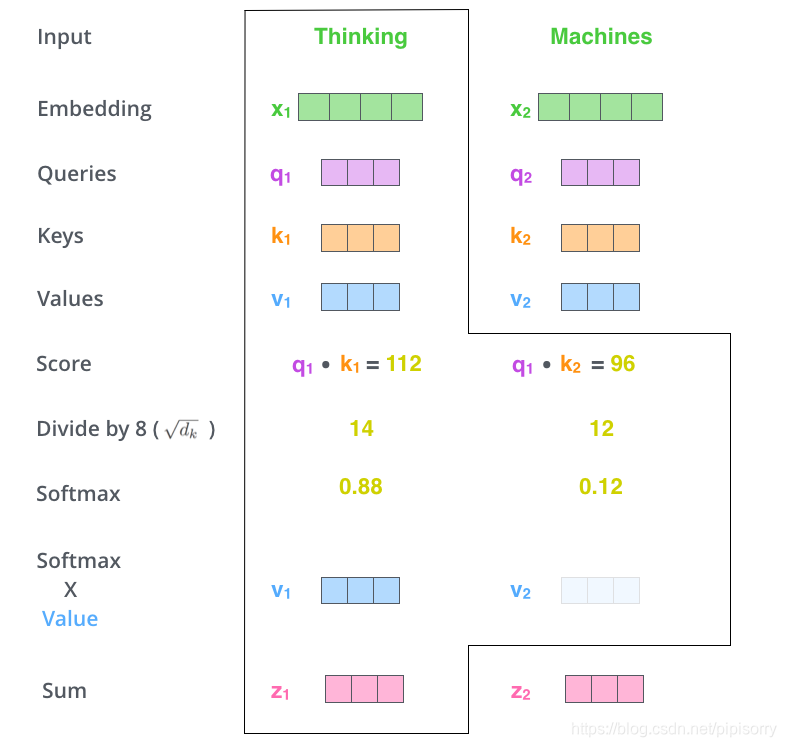
Self-Attention计算示例图
实际计算过程中是采用基于矩阵的计算方式,那么论文中的 ,
,
的计算方式如:
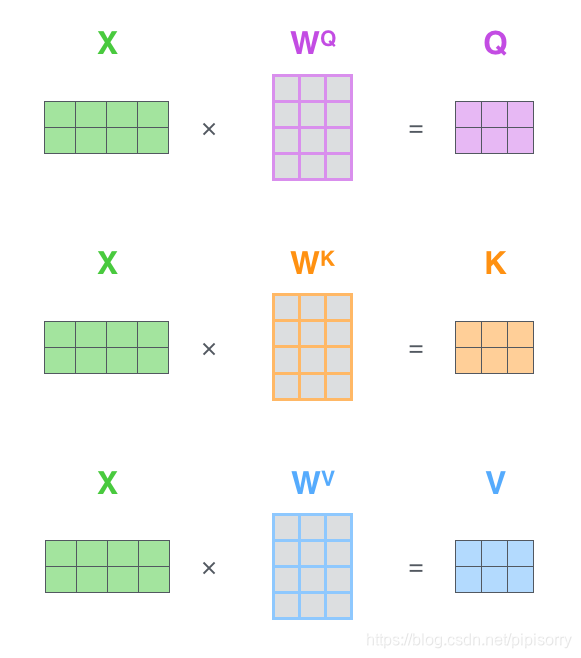
Q,V,K的矩阵表示
总结为下面的矩阵形式:
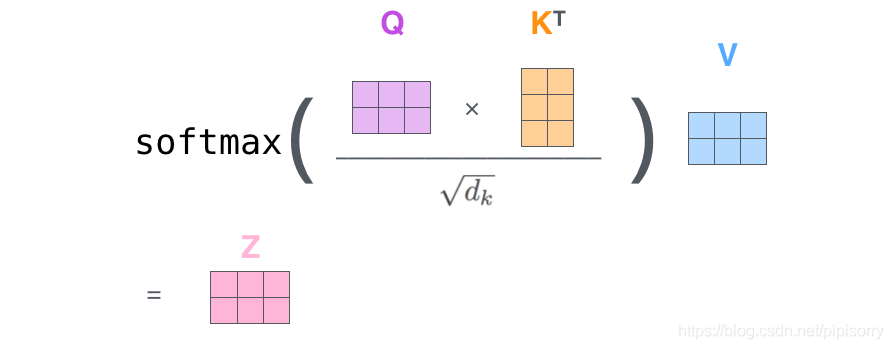
Self-Attention的矩阵表示
这里也就是公式1的计算方式。
在self-attention需要强调的最后一点是其采用了残差网络中的short-cut结构,目的当然是解决深度学习中的退化问题,得到的最终结果如图。
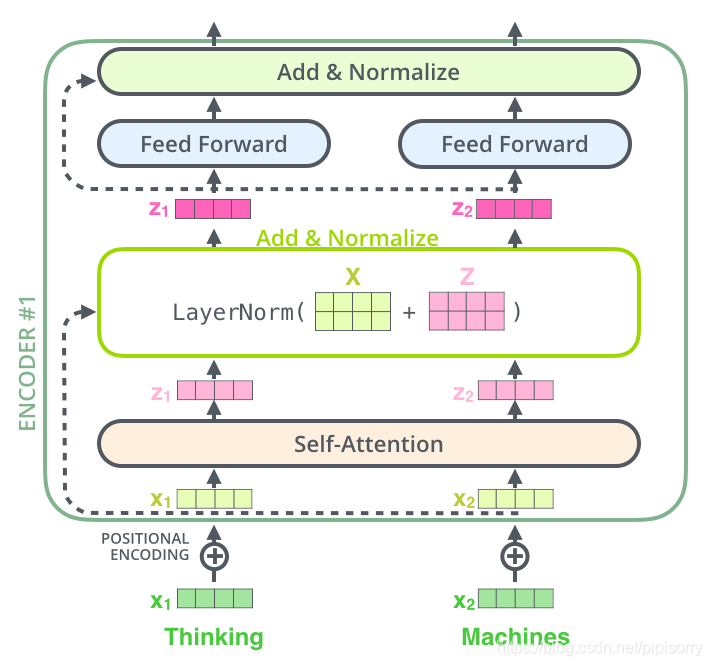
Self-Attention中的short-cut连接
Multi-Head Attention
Multi-Head Attention相当于 个不同的self-attention的集成(ensemble),在这里我们以
举例说明。Multi-Head Attention的输出分成3步:
- 将数据
分别输入到上面的8个self-attention中,得到8个加权后的特征矩阵
。
- 将8个
按列拼成一个大的特征矩阵;
- 特征矩阵经过一层全连接后得到输出
。
整个过程如图所示:
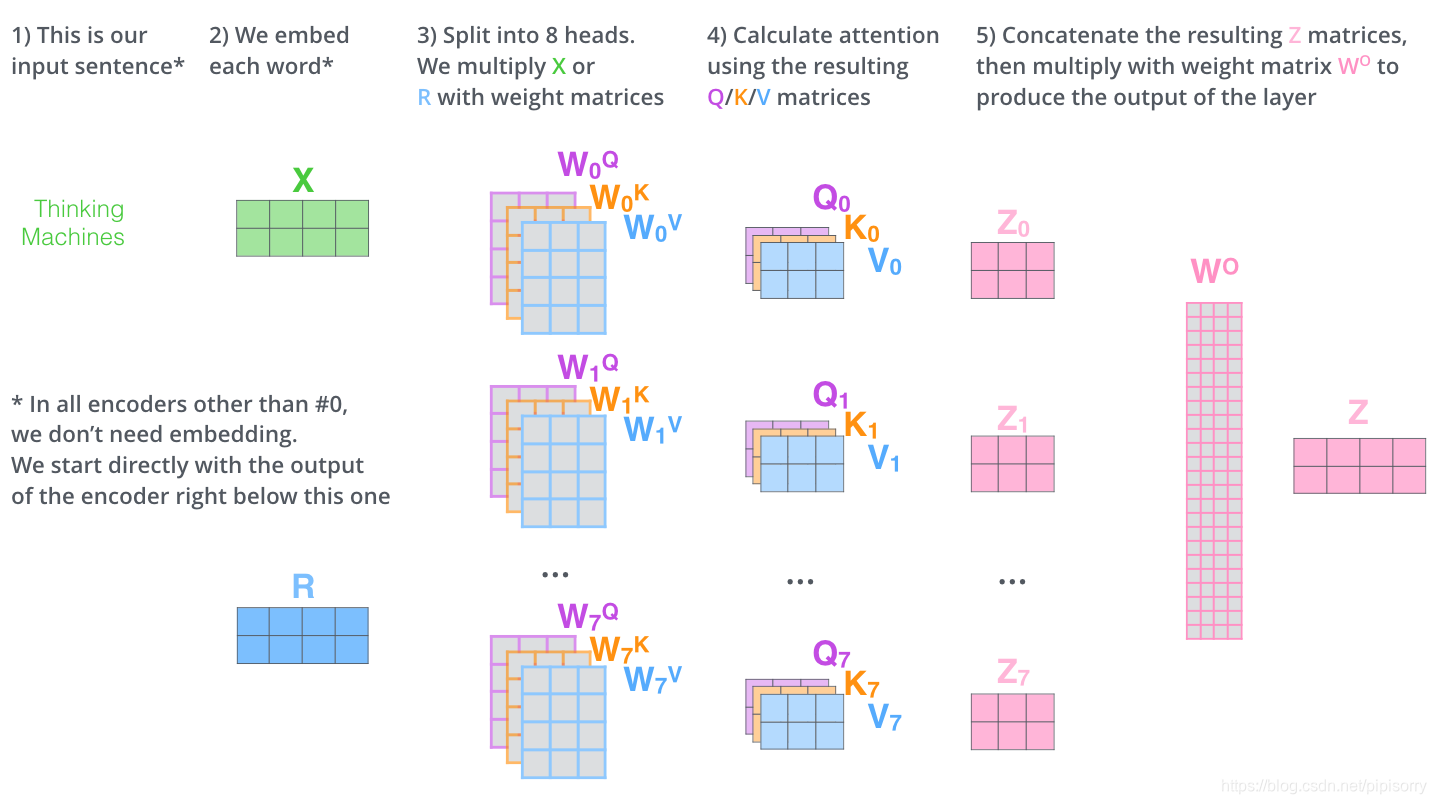
Multi-Head Attention
同self-attention一样,multi-head attention也加入了short-cut机制。
decode整体的动图
先通过encoder生成一个词。
![]()
再通过decoder生成后续的词。
![]()
转自:https://blog.csdn.net/pipisorry/article/details/84946653
from: http://blog.csdn.net/pipisorry/
ref: [论文笔记:Attention is all you need]
[详解Transformer (Attention Is All You Need)]*
[图解transformer:The Illustrated Transformer]
[code tensor2tensor/models/transformer.py]