注意,在TensorFlow 1.3中,Dataset API是放在contrib包中的:
tf.contrib.data.Dataset
而在TensorFlow 1.4中,Dataset API已经从contrib包中移除,变成了核心API的一员:
tf.data.Dataset
此前,在TensorFlow中读取数据一般有两种方法:
使用placeholder读内存中的数据
使用queue读硬盘中的数据
Dataset API同时支持从内存和硬盘的读取,相比之前的两种方法在语法上更加简洁易懂。此外,如果想要用到TensorFlow新出的Eager模式,就必须要使用Dataset API来读取数据。
三、基本使用
1、一维数据集示范基本使用
Google官方给出的Dataset API中的类图:

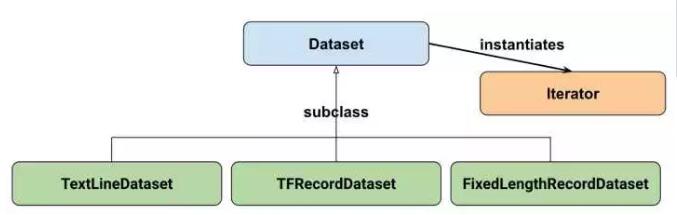
在初学时,我们只需要关注两个最重要的基础类:Dataset和Iterator。
Dataset可以看作是相同类型“元素”的有序列表。在实际使用时,单个“元素”可以是向量,也可以是字符串、图片,甚至是tuple或者dict。
数据集对象实例化:
dataset = tf.data.Dataset.from_tensor_slices(数据)
迭代器对象实例化(非Eager模式下):
iterator = dataset.make_one_shot_iterator()
one_element = iterator.get_next()
综合起来效果如下,
| 1 2 3 4 5 6 7 8 9 |
|
输出:1.0 2.0 3.0 4.0 5.0
读取结束异常:
如果一个dataset中元素被读取完了,再尝试sess.run(one_element)的话,就会抛出tf.errors.OutOfRangeError异常,这个行为与使用队列方式读取数据的行为是一致的。
在实际程序中,可以在外界捕捉这个异常以判断数据是否读取完,综合以上三点请参考下面的代码:
| 1 2 3 4 5 6 7 8 9 10 |
|
输出:1.0 2.0 3.0 4.0 5.0 end!
2、高维数据集使用
tf.data.Dataset.from_tensor_slices真正作用是切分传入Tensor的第一个维度,生成相应的dataset,即第一维表明数据集中数据的数量,之后切分batch等操作都以第一维为基础。
dataset = tf.data.Dataset.from_tensor_slices(np.random.uniform(size=(5, 2)))
传入的数值是一个矩阵,它的形状为(5, 2),tf.data.Dataset.from_tensor_slices就会切分它形状上的第一个维度,最后生成的dataset中一个含有5个元素,每个元素的形状是(2, ),即每个元素是矩阵的一行。
| 1 2 3 4 5 6 7 8 9 10 |
|
[0.09787406 0.71672957]
[0.25681324 0.81974072]
[0.35186046 0.39362398]
[0.75228199 0.6534702 ]
[0.39695169 0.9341708 ]
end!
3、字典使用
在实际使用中,我们可能还希望Dataset中的每个元素具有更复杂的形式,如每个元素是一个Python中的元组,或是Python中的词典。例如,在图像识别问题中,一个元素可以是{“image”: image_tensor, “label”: label_tensor}的形式,这样处理起来更方便,
注意,image_tensor、label_tensor和上面的高维向量一致,第一维表示数据集中数据的数量。相较之下,字典中每一个key值可以看做数据的一个属性,value则存储了所有数据的该属性值。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
{'a': 1.0, 'b': array([0.31721037, 0.33378767])}
{'a': 2.0, 'b': array([0.99221946, 0.65894961])}
{'a': 3.0, 'b': array([0.98405468, 0.11478854])}
{'a': 4.0, 'b': array([0.95311317, 0.57432678])}
{'a': 5.0, 'b': array([0.46067428, 0.19716722])}
end!
4、复杂的tuple组合数据
类似的,可以使用组合的特征进行拼接,
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
(1.0, array([6.55877282e-04, 6.63244735e-01]))
(2.0, array([0.04756927, 0.44968581]))
(3.0, array([0.97841076, 0.06465231]))
(4.0, array([0.46639246, 0.39146086]))
(5.0, array([0.61085016, 0.61609538]))
end!
四、数据集处理方法
Dataset支持一类特殊的操作:Transformation。一个Dataset通过Transformation变成一个新的Dataset。通常我们可以通过Transformation完成数据变换,打乱,组成batch,生成epoch等一系列操作。
常用的Transformation有:
map
batch
shuffle
repeat
map
和python中的map类似,map接收一个函数,Dataset中的每个元素都会被当作这个函数的输入,并将函数返回值作为新的Dataset,
| 1 2 3 4 5 6 7 8 9 10 11 12 |
|
输出:2.0 3.0 4.0 5.0 6.0 end!
注意map函数可以使用num_parallel_calls参数加速(第五部分有介绍)。
batch
batch就是将多个元素组合成batch,如上所说,按照输入元素第一个维度,
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
{'a': array([1., 2.]), 'b': array([[0.87466134, 0.21519021], [0.6123372 , 0.95722733]])}
{'a': array([3., 4.]), 'b': array([[0.76964374, 0.22445015], [0.08313089, 0.60531841]])}
{'a': array([5.]), 'b': array([[0.37901654, 0.3955096 ]])}
end!
shuffle
shuffle的功能为打乱dataset中的元素,它有一个参数buffersize,表示打乱时使用的buffer的大小,建议舍的不要太小,一般是1000:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
{'a': 3.0, 'b': array([0.82048268, 0.39821839])}
{'a': 4.0, 'b': array([0.42775421, 0.36749283])}
{'a': 1.0, 'b': array([0.09588742, 0.01954797])}
{'a': 2.0, 'b': array([0.10992948, 0.24416772])}
{'a': 5.0, 'b': array([0.15447616, 0.09005545])}
end!
repeat
repeat的功能就是将整个序列重复多次,主要用来处理机器学习中的epoch,假设原先的数据是一个epoch,使用repeat(2)就可以将之变成2个epoch:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
{'a': 1.0, 'b': array([0.85180201, 0.1703507 ])}
{'a': 2.0, 'b': array([0.37874819, 0.81303628])}
{'a': 3.0, 'b': array([0.99560094, 0.56446562])}
{'a': 4.0, 'b': array([0.86341794, 0.69984075])}
{'a': 5.0, 'b': array([0.85026424, 0.74761098])}
{'a': 1.0, 'b': array([0.85180201, 0.1703507 ])}
{'a': 2.0, 'b': array([0.37874819, 0.81303628])}
{'a': 3.0, 'b': array([0.99560094, 0.56446562])}
{'a': 4.0, 'b': array([0.86341794, 0.69984075])}
{'a': 5.0, 'b': array([0.85026424, 0.74761098])}
end!
注意,如果直接调用repeat()的话,生成的序列就会无限重复下去,没有结束,因此也不会抛出tf.errors.OutOfRangeError异常。
五、模拟读入磁盘图片与对应label
考虑一个简单,但同时也非常常用的例子:读入磁盘中的图片和图片相应的label,并将其打乱,组成batch_size=32的训练样本,在训练时重复10个epoch
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
在这个过程中,dataset经历三次转变:
运行dataset = tf.data.Dataset.from_tensor_slices((filenames, labels))后,dataset的一个元素是(filename, label)。filename是图片的文件名,label是图片对应的标签。
之后通过map,将filename对应的图片读入,并缩放为28x28的大小。此时dataset中的一个元素是(image_resized, label)
最后,dataset.shuffle(buffersize=1000).batch(32).repeat(10)的功能是:在每个epoch内将图片打乱组成大小为32的batch,并重复10次。最终,dataset中的一个元素是(image_resized_batch, label_batch),image_resized_batch的形状为(32, 28, 28, 3),而label_batch的形状为(32, ),接下来我们就可以用这两个Tensor来建立模型了。
help(tf.data.Dataset.map)
可见:
Help on function map in module tensorflow.python.data.ops.dataset_ops:
map(self, map_func, num_parallel_calls=None)
Maps `map_func` across this datset.
Args:
map_func: A function mapping a nested structure of tensors (having
shapes and types defined by `self.output_shapes` and
`self.output_types`) to another nested structure of tensors.
num_parallel_calls: (Optional.) A `tf.int32` scalar `tf.Tensor`,
representing the number elements to process in parallel. If not
specified, elements will be processed sequentially.
Returns:
A `Dataset`.
由此可见map作为读取处理的关键步骤,是可以多线程加速的。
六、更多的Dataset创建方法
除了tf.data.Dataset.from_tensor_slices外,目前Dataset API还提供了另外三种创建Dataset的方式:
tf.data.TextLineDataset():这个函数的输入是一个文件的列表,输出是一个dataset。dataset中的每一个元素就对应了文件中的一行。可以使用这个函数来读入CSV文件。
tf.data.FixedLengthRecordDataset():这个函数的输入是一个文件的列表和一个record_bytes,之后dataset的每一个元素就是文件中固定字节数record_bytes的内容。通常用来读取以二进制形式保存的文件,如CIFAR10数据集就是这种形式。
tf.data.TFRecordDataset():顾名思义,这个函数是用来读TFRecord文件的,dataset中的每一个元素就是一个TFExample。
它们的详细使用方法可以参阅文档:Module: tf.data
Tensorflow 现在将 Dataset 作为首选的数据读取手段,而 Iterator 是 Dataset 中最重要的概念。这篇文章的目的是,以官网文档为基础,较详细的介绍 Iterator 的用法。
Dataset 和 Iterator 的关系
在文章开始之前,首先得对 Dataset 和 Iterator 有一个感性的认识。
Dataset 是数据集,Iterator 是对应的数据集迭代器。
如果 Dataset 是一个水池的话,那么它其中的数据就好比是水池中的水,Iterator 你可以把它当成是一根水管。
在 Tensorflow 的程序代码中,正是通过 Iterator 这根水管,才可以源源不断地从 Dataset 中取出数据。
但为了应付多变的环境,水管也需要变化,Iterator 也有许多种类。
下面,细细道来。
一次性水管,单次 Iterator
创建单次迭代器,非常的简单,只需要调用 Dataset 对象相应的方法。
make_one_shot_iterator()
1
这个方法会返回一个 Iterator 对象。
而调用 iterator 的 get_next() 就可以轻松地取出数据了。
import tensorflow as tf
dataset = tf.data.Dataset.range(5)
iterator = dataset.make_one_shot_iterator()
with tf.Session() as sess:
while True:
try:
print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError:
break
上面的代码非常简单,首先创建了一个包含 0 到 4 的数据集。然后,创建了一个单次迭代器。
通过循环调用 get_next() 方法就可以将数据取出。
需要注意的是,通常用 try-catch 配合使用,当 Dataset 中的数据被读取完毕的时候,程序会抛出异常,获取这个异常就可以从容结束本次数据的迭代。
然后, iterator 就完成了它的历史使命。单次的迭代器,不支持动态的数据集,它比较单纯,它不支持参数化。
什么是参数化呢?你可以理解为单次的 Iterator 认死理,它需要 Dataset 在程序运行之前就确认自己的大小,但我们都知道 Tensorflow 中有一种 feeding 机制,它允许我们在程序运行时再真正决定我们需要的数据,很遗憾,单次的 Iterator 不能满足这要的要求。
可以定制的水管,可初始化的 Iterator
单次 Iterator 无法满足参数化的要求,但有其他类型的 Iterator 可以完成这个目标。
先看一段代码,问问自己,你觉得它能正常运行吗?
def initialable_test():
numbers = tf.placeholder(tf.int64,shape=[])
dataset = tf.data.Dataset.range(numbers)
iterator = dataset.make_one_shot_iterator()
with tf.Session() as sess:
while True:
try:
print(sess.run(iterator.get_next(),feed_dict={numbers:5}))
except tf.errors.OutOfRangeError:
break
答案是否定的,程序会报错。
ValueError: Cannot capture a placeholder (name:Placeholder, type:Placeholder) by value.
1
原因,我前面刚刚有讲过。
不过,我们可以这样改写代码:
def initialable_test():
numbers = tf.placeholder(tf.int64,shape=[])
dataset = tf.data.Dataset.range(numbers)
# iterator = dataset.make_one_shot_iterator()
iterator = dataset.make_initializable_iterator()
with tf.Session() as sess:
sess.run(iterator.initializer,feed_dict={numbers:5})
while True:
try:
print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError:
break
sess.run(iterator.initializer,feed_dict={numbers:6})
while True:
try:
print(sess.run(iterator.get_next()))
except tf.errors.OutOfRangeError:
break
运行程序,结果就是打印了 01234,012345 相信大家可以很容易明白发生了什么。
跟单次 Iterator 的代码只有 2 处不同。
1、创建的方式不同,iterator.make_initialnizer()。
2、每次重新初始化的时候,都要调用sess.run(iterator.initializer)
你可以这样理解,Dataset 这个水池连续装了 2 次水,每次水量不一样,但可初始化的 Iterator 很好地处理了这件事情,但需要注意的是,这个时候 Iterator 还是面对同一个 Dataset。
能够接不同水池的水管,可重新初始化的 Iterator
有时候,需要一个 Iterator 从不同的 Dataset 对象中读取数值。Tensorflow 针对这种情况,提供了一个可以重新初始化的 Iterator,它的用法相对而言,比较复杂,但好在不是很难理解。
def reinitialable_iterator_test():
training_data = tf.data.Dataset.range(10)
validation_data = tf.data.Dataset.range(5)
iterator = tf.data.Iterator.from_structure(training_data.output_types,
training_data.output_shapes)
train_op = iterator.make_initializer(training_data)
validation_op = iterator.make_initializer(validation_data)
next_element = iterator.get_next()
with tf.Session() as sess:
for _ in range(3):
sess.run(train_op)
for _ in range(3):
print(sess.run(next_element))
print('===========')
sess.run(validation_op)
for _ in range(2):
print(sess.run(next_element))
print('===========')
它的运行结果如下:
0
1
2
===========
0
1
===========
0
1
2
===========
0
1
===========
0
1
2
===========
0
1
===========
核心代码其实只有 3 行。
iterator = tf.data.Iterator.from_structure(training_data.output_types,
training_data.output_shapes)
train_op = iterator.make_initializer(training_data)
validation_op = iterator.make_initializer(validation_data)
Iterator 可以接多个水池里面的水,但是要求这水池里面的水是同样的品质。
也就是,多个 Dataset 中它们的元素数据类型和形状应该是一致的。
通过 from_structure() 统一规格,后面的 2 句代码可以看成是 2 个水龙头,它们决定了放哪个水池当中的水。
不知道大家注意到一点没有?每次 Iterator 切换时,数据都从头开始打印了。如果,不想这种情况发生,就需要接下来介绍的另外一种 Iterator。
水管的转换器,可馈送的 Iterator
Tensorflow 最美妙的一个地方就是 feeding 机制,它决定了很多东西可以在程序运行时,动态填充,这其中也包括了 Iterator。
不同的 Dataset 用不同的 Iterator,然后利用 feeding 机制,动态决定,听起来就很棒,不是吗?
我们都知道,无论是在机器学习还是深度学习当中,训练集、验证集、测试集是大家绕不开的话题,但偏偏它们要分离开来,偏偏它们的数据类型又一致,所以,经常我们要写同样的重复的代码。
复用,是软件开发中一个重要的思想。
可馈送的 Iterator 一定程度上可以解决重复的代码,同时又将训练集和验证集的操作清晰得分离开来。
def feeding_iterator_test():
train_data = tf.data.Dataset.range(100).map(
lambda x : x + tf.random_uniform([],0,10,tf.int64)
)
val_data = tf.data.Dataset.range(5)
handle = tf.placeholder(tf.string,shape=[])
iterator = tf.data.Iterator.from_string_handle(
handle,train_data.output_types,train_data.output_shapes)
next_element = iterator.get_next()
train_op = train_data.make_one_shot_iterator()
validation_op = val_data.make_initializable_iterator()
with tf.Session() as sess:
train_iterator_handle = sess.run(train_op.string_handle())
val_iterator_handle = sess.run(validation_op.string_handle())
for _ in range(3):
for _ in range(2):
print(sess.run(next_element,feed_dict={handle:train_iterator_handle}))
print('======')
sess.run(validation_op.initializer)
for _ in range(5):
print(sess.run(next_element,feed_dict={handle:val_iterator_handle}))
print('======')
看起来跟前面以小节的代码没有多大区别。核心代码如下:
handle = tf.placeholder(tf.string,shape=[])
iterator = tf.data.Iterator.from_string_handle(
handle,train_data.output_types,train_data.output_shapes)
train_iterator_handle = sess.run(train_op.string_handle())
val_iterator_handle = sess.run(validation_op.string_handle())
它是通过一个 string 类型的 handle 实现的。
需要注意的一点是,string_handle() 方法返回的是一个 Tensor,只有运行一个 Tensor 才会返回 string 类型的 handle。不然,程序会报错。
如果用图表的形式加深理解的话,那就是可馈送 Iterator 的方式,可以自主决定用哪个 Iterator,就好比不同的水池有不同的水管,不需要用同一根水管接到不同的水池当中去了。
可馈送的 Iterator 和可重新初始化的 Iterator 非常相似,但是,可馈送的 Iterator 在不同的 Iterator 切换的时候,可以做到不从头开始。
总结
相信阅读到这里,你已经明白了这 4 中 Iterator 的用法了。
1、 单次 Iterator ,它最简单,但无法重用,无法处理数据集参数化的要求。
2、 可以初始化的 Iterator ,它可以满足 Dataset 重复加载数据,满足了参数化要求。
3、可重新初始化的 Iterator,它可以对接不同的 Dataset,也就是可以从不同的 Dataset 中读取数据。
4、可馈送的 Iterator,它可以通过 feeding 的方式,让程序在运行时候选择正确的 Iterator,它和可重新初始化的 Iterator 不同的地方就是它的数据在不同的 Iterator 切换时,可以做到不重头开始读取数据。
终上所述,在真实的神经网络训练过程当中,可馈送的 Iterator 是最值得推荐的方式。
tf.data.TFRecordDataset() & make_one_shot_iterator()
tf.data.TFRecordDataset() 输入参数直接是后缀名为tfrecords的文件路径,正因如此,即可解决数据量过大,导致无法单机训练的问题。本篇博客中,文件路径即为/Users/honglan/Desktop/train_output.tfrecords,此处是我自己电脑上的路径,大家可以 根据自己的需要修改为对应的文件路径。
make_one_shot_iterator() 即为单次迭代器,是最简单的迭代器形式,仅支持对数据集进行一次迭代,不需要显式初始化。
配合 MNIST数据集以及tf.data.TFRecordDataset(),实现代码如下。
# Validate tf.data.TFRecordDataset() using make_one_shot_iterator()
import tensorflow as tf
import numpy as np
num_epochs = 2
num_class = 10
sess = tf.Session()
def parser(record):
keys_to_features = {
"image_raw": tf.FixedLenFeature((), tf.string, default_value=""),
"pixels": tf.FixedLenFeature((), tf.int64, default_value=tf.zeros([], dtype=tf.int64)),
"label": tf.FixedLenFeature((), tf.int64,
default_value=tf.zeros([], dtype=tf.int64)),
}
parsed = tf.parse_single_example(record, keys_to_features)
images = tf.decode_raw(parsed["image_raw"], tf.uint8)
images = tf.reshape(images, [28, 28, 1])
labels = tf.cast(parsed['label'], tf.int32)
labels = tf.one_hot(labels, num_class)
pixels = tf.cast(parsed['pixels'], tf.int32)
print("IMAGES", images)
print("LABELS", labels)
return {"image_raw": images}, labels
filenames = ["/Users/honglan/Desktop/train_output.tfrecords"]
dataset = tf.data.TFRecordDataset(filenames)
print("DATASET", dataset)
dataset = dataset.map(parser)
print("DATASET_1", dataset)
dataset = dataset.shuffle(buffer_size=10000)
print("DATASET_2", dataset)
dataset = dataset.batch(32)
print("DATASET_3", dataset)
dataset = dataset.repeat(num_epochs)
print("DATASET_4", dataset)
iterator = dataset.make_one_shot_iterator()
features, labels = iterator.get_next()
print("FEATURES", features)
print("LABELS", labels)
print("SESS_RUN_LABELS \n", sess.run(labels))tf.data.TFRecordDataset() & Initializable iterator
make_initializable_iterator() 为可初始化迭代器,运用此迭代器首先需要先运行显式 iterator.initializer 操作,然后才能使用。并且,可运用 可初始化迭代器实现训练集和验证集的切换。
配合 MNIST数据集 实现代码如下。
import tensorflow as tf
def decode_line(line):
# Decode the line to tensor
record_defaults = [[1.0] for col in range(785)]
items = tf.decode_csv(line, record_defaults)
features = items[1:785]
label = items[0]
features = tf.cast(features, tf.float32)
features = tf.reshape(features,[28,28,1])
label = tf.cast(label, tf.int64)
label = tf.one_hot(label,num_class)
return features,label
def create_dataset(filename, batch_size=32, is_shuffle=False, n_repeats=0):
"""create dataset for train and validation dataset"""
dataset = tf.data.TextLineDataset(filename).skip(1)
if n_repeats > 0:
dataset = dataset.repeat(n_repeats) # for train
# dataset = dataset.map(decode_line).map(normalize)
dataset = dataset.map(decode_line)
# decode and normalize
if is_shuffle:
dataset = dataset.shuffle(10000) # shuffle
dataset = dataset.batch(batch_size)
return dataset
training_filenames = ["/Users/honglan/Desktop/train.csv"]
# replace the filenames with your own path
validation_filenames = ["/Users/honglan/Desktop/val.csv"]
# replace the filenames with your own path
# Create different datasets
training_dataset = create_dataset(training_filenames, batch_size=32, \
is_shuffle=True, n_repeats=num_epochs) # train_filename
validation_dataset = create_dataset(validation_filenames, batch_size=32, \
is_shuffle=True, n_repeats=num_epochs) # val_filename
iterator = tf.data.Iterator.from_structure(training_dataset.output_types,
training_dataset.output_shapes)
features, labels = iterator.get_next()
training_init_op = iterator.make_initializer(training_dataset)
validation_init_op = iterator.make_initializer(validation_dataset)
# Using reinitializable iterator to alternate between training and validation.
sess.run(training_init_op)
print("TRAIN\n",sess.run(labels))
# print(sess.run(features))
# Reinitialize `iterator` with validation data.
sess.run(validation_init_op)
print("VAL\n",sess.run(labels))tf.data.TextLineDataset() & Reinitializable iterator
tf.data.TextLineDataset(),输入参数可以是后缀名为csv或者是txt的源数据的文件路径。
此处用的迭代器是 Reinitializable iterator,即为可重新初始化迭代器。官方定义如下。配合 MNIST数据集 实现代码见第二部分。
import tensorflow as tf
def decode_line(line):
# Decode the line to tensor
record_defaults = [[1.0] for col in range(785)]
items = tf.decode_csv(line, record_defaults)
features = items[1:785]
label = items[0]
features = tf.cast(features, tf.float32)
features = tf.reshape(features,[28,28])
label = tf.cast(label, tf.int64)
label = tf.one_hot(label,num_class)
return features,label
def create_dataset(filename, batch_size=32, is_shuffle=False, n_repeats=0):
"""create dataset for train and validation dataset"""
dataset = tf.data.TextLineDataset(filename).skip(1)
if n_repeats > 0:
dataset = dataset.repeat(n_repeats) # for train
# dataset = dataset.map(decode_line).map(normalize)
dataset = dataset.map(decode_line)
# decode and normalize
if is_shuffle:
dataset = dataset.shuffle(10000) # shuffle
dataset = dataset.batch(batch_size)
return dataset
training_filenames = ["/Users/honglan/Desktop/train.csv"]
# replace the filenames with your own path
validation_filenames = ["/Users/honglan/Desktop/val.csv"]
# replace the filenames with your own path
# Create different datasets
training_dataset = create_dataset(training_filenames, batch_size=32, \
is_shuffle=True, n_repeats=num_epochs) # train_filename
validation_dataset = create_dataset(validation_filenames, batch_size=32, \
is_shuffle=True, n_repeats=num_epochs) # val_filename
handle = tf.placeholder(tf.string, shape=[])
iterator = tf.data.Iterator.from_string_handle(
handle, training_dataset.output_types, training_dataset.output_shapes)
features, labels = iterator.get_next()
training_iterator = training_dataset.make_one_shot_iterator()
validation_iterator = validation_dataset.make_initializable_iterator()
training_handle = sess.run(training_iterator.string_handle())
validation_handle = sess.run(validation_iterator.string_handle())
print("TRAIN\n",sess.run(labels, feed_dict={handle: training_handle}))
# print(sess.run(features))
sess.run(validation_iterator.initializer)
print("VAL\n",sess.run(labels, feed_dict={handle: validation_handle}))