实验介绍
学号尾数:186
原创作品转载请注明出处 + https://github.com/mengning/linuxkernel/
引例:http://codelab.shiyanlou.com/xref/linux-3.18.6/include/linux/sched.h#1235
参考:https://www.cnblogs.com/fuchen1994/p/5400967.html
实验背景
代码运行在Ubuntu14.04上
虚拟机在Mac的Parallel Desktop上运行。
目标
理解进程创建、可执行文件的加载和进程执行进程切换,重点理解分析fork、execve和进程切换
分析fork函数对应的内核处理过程do_fork,理解创建一个新进程如何创建和修改task_struct数据结构;
使用gdb跟踪分析一个fork系统调用内核处理函数do_fork
理解编译链接的过程和ELF可执行文件格式等
实验步骤
1.阅读进程调度相关代码
代码来源:http://codelab.shiyanlou.com/xref/linux-3.18.6/include/linux/sched.h#1235;
task_struct的结构体
Linux系统是采用链式方式来组织PCB的,对于不同的状态建立起一个进程队列。在Linux内核中,使用一个名为task_struct的结构体来描述PCB.此处仅列出部分结构体的定义代码。
1235 struct task_struct {
1236 volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
1237 void *stack;
1238 atomic_t usage;
1239 unsigned int flags; /* per process flags, defined below */
1240 unsigned int ptrace;
do_fork函数
Linux中创建进程有三个函数fork,vfork和clone:
fork:创建子进程
vfork:与fork类似,但是父子进程共享地址空间,而且子进程先于父进程运行。
clone:主要用于创建线程.
相关代码:
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
// ...
// 复制进程描述符,返回创建的task_struct的指针
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
// 取出task结构体内的pid
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
// 如果使用的是vfork,那么必须采用某种完成机制,确保父进程后运行
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
// 将子进程添加到调度器的队列,使得子进程有机会获得CPU
wake_up_new_task(p);
// ...
// 如果设置了 CLONE_VFORK 则将父进程插入等待队列,并挂起父进程直到子进程释放自己的内存空间
// 保证子进程优先于父进程运行
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
运行流程:
调用copy_process,将当期进程复制一份出来为子进程,并且为子进程设置相应地上下文信息。
初始化vfork的完成处理信息(如果是vfork调用)
调用wake_up_new_task,将子进程放入调度器的队列中,此时的子进程就可以被调度进程选中,得以运行。
如果是vfork调用,需要阻塞父进程,知道子进程执行exec。
2.使用gdb跟踪分析一个fork系统调用内核处理函数do_fork
qemu和gdb跟踪分析do_fork的调用过程
将进程代码写在/usr/menu/test.c内,以便测试

注意在主函数main()中添加对fork函数的引用:

重新编译menu,并创建rootfs
管理员权限下:
make rootfs
cd …/rootfs
cp …/menu/init ./
find . | cpio -o -Hnewc |gzip -9 > …/rootfs.img
跟踪分析
在终端中输入命令:
qemu-system-i386 -kernel linux-5.0.1/arch/x86/boot/bzImage -initrd rootfs.img -s -S -append nokaslr
分别在sys_clone、do_fork、dup_task_struct、copy_process和copy_thread函数调用处设置断点:
运行结果: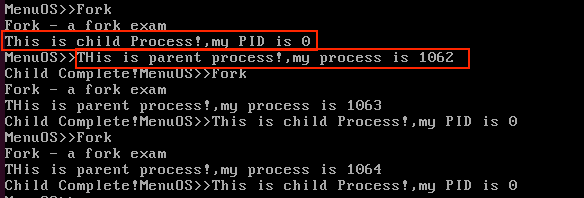
fork()函数调用一次会返回两次,在父进程中返回的是创建的子进程的pid,在子进程中返回的是0,因此可以通过返回的pid的值来判断输出的信息是来自于子进程还是父进程,接着我们使用gdb开始跟踪fork()的执行过程。相关信息如图所示。
3.理解编译链接的过程和ELF可执行文件格式:
注:图片引用自https://blog.csdn.net/Xindolia_Ring/article/details/80961363

ELF头以一个16字节的序列开始,描述了生成该文件的系统的字的大小和字节顺序。ELF头剩下的部分包含帮助连接器语法分析和解释目标文件的信息。其中包括ELF头的大小、目标文件的类型(如可重定位、可执行、共享的)、机器类型(如x86-64)、节头部表的文件偏移,以及节头部表中条目的大小和数量。
相关字段:
| .text | 已编译程序的机器代码 |
|---|---|
| .rodata | 只读数据 |
| .data | 已初始化的全局和静态C变量。 |
| .bss | 未初始化的全局和静态C变量,以及所有被初始化为0的全局或静态变量。 |
编译是指编译器读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码。
源文件的编译过程包含两个主要阶段:
第一个阶段是预处理阶段,在正式的编译阶段之前进行。预处理阶段将根据已放置在文件中的预处理指令来修改源文件的内容。
第二个阶段编译、优化阶段,编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。
静态链接(编译时)
链接器将函数的代码从其所在地(目标文件或静态链接库中)拷贝到最终的可执行程序中。这样该程序在被执行时这些代码将被装入到该进程的虚拟地址空间中。静态链接库实际上是一个目标文件的集合,其中的每个文件含有库中的一个或者一组相关函数的代码。
为创建可执行文件,链接器必须要完成的主要任务:
符号解析:把目标文件中符号的定义和引用联系起来;
重定位:把符号定义和内存地址对应起来,然后修改所有对符号的引用。
动态链接(加载、运行时)
在此种方式下,函数的定义在动态链接库或共享对象的目标文件中。在编译的链接阶段,动态链接库只提供符号表和其他少量信息用于保证所有符号引用都有定义,保证编译顺利通过。动态链接器(ld-linux.so)链接程序在运行过程中根据记录的共享对象的符号定义来动态加载共享库,然后完成重定位。在此可执行文件被执行时,动态链接库的全部内容将被映射到运行时相应进程的虚地址空间。动态链接程序将根据可执行程序中记录的信息找到相应的函数代码。
4.使用execve库函数加载一个可执行文件:
编写execl.c,使用gcc编译
gcc -o execl execl.c
结果如图所示:

实验总结与致谢
通过系统调用,用户空间的应用程序就会进入内核空间,由内核代表该进程运行于内核空间,这就涉及到上下文的切换,用户空间和内核空间具有不同的地址映射,通用或专用的寄存器组,而用户空间的进程要传递很多变量、参数给内核,内核也要保存用户进程的一些寄存器、变量等,以便系统调用结束后回到用户空间继续执行,所谓的进程上下文,就是一个进程在执行的时候,CPU的所有寄存器中的值、进程的状态以及堆栈中的内容,当内核需要切换到另一个进程时,它需要保存当前进程的所有状态,即保存当前进程的进程上下文,以便再次执行该进程时,能够恢复切换时的状态,继续执行。
学号尾数:186
原创作品转载请注明出处 + https://github.com/mengning/linuxkernel/
引例:http://codelab.shiyanlou.com/xref/linux-3.18.6/include/linux/sched.h#1235
参考:https://www.cnblogs.com/fuchen1994/p/5400967.html